Usage Note 32304: Causes of missing predicted values and excluded (unused) observations from modeling procedures
 |  |  |
In an analysis performed by a modeling procedure, observations can be excluded for various reasons. When an observation is excluded, it might or might not be possible to compute its predicted value (where prediction is applicable). The numbers of observations read and used (excluded) are typically reported in a table displayed by the analysis procedure.
The following discusses reasons for observations to be excluded and for predictions to be missing. It also shows how to get an analysis of missing values by looking simultaneously at all variables involved in the model to help understand why and which observations are excluded and possibly have missing predictions. It is important to understand that investigation of individual variables in the model is not sufficient since different observations can be excluded for different reasons.
Also shown below are how you can produce data sets of observations that were used or were excluded from fitting the model as well as data sets of observations for which predictions could and could not be produced.
Causes for exclusion and missing prediction
SAS® modeling procedures provide several ways for scoring observations using a fitted model as described in SAS Note 33307. When scoring new data or data used in training the model, the observation will be excluded (not used in fitting the model) and its predicted value will be missingNote1 if any of the following conditions occurs.
- The value of any predictor is missing. Predictor variables are typically specified in a MODEL statement, but depending on the procedure, might be specified in other statements such as VAR, RANDOM, ZEROMODEL, DISPMODEL, or others. All predictor variables must be nonmissing in order to compute a predicted value. Otherwise predicted values and various other computed statistics in the output data set will be missing. This condition is illustrated in the example below. The ADAPTIVEREG and PLS procedures are exceptions. PROC ADAPTIVEREG can provide predicted values when predictors are missing. The MISSING= option can be used in PROC PLS to impute missing predictors so that predicted values can be computed. In procedures that provide effect selection methods (forward, stepwise, and others), a missing value in a candidate variable will not cause the predicted value to be missing if that variable is not included in the final model. Imputation methods are available in the MI procedure (SAS Note 22930) that can be used in many situations to replace missing predictor values.
- The value is missing for any variable in a statement (such as CLASS, STRATA, REPEATED, or other) that further defines the model. As with model predictors, variables in such statements must also be nonmissing. In some cases, the procedure cannot fit the model when missing values exist. Generally, observations with missing CLASS variable values are ignored by modeling procedures when fitting the model, and many proceduresNote2 also do not compute predicted values for such observations. Therefore, it is best practice to not specify variables in the CLASS statement unless they are also specified in another model-defining statement such as the MODEL, ZEROMODEL, REPEATED, or other statement.
- The value of any CLASS predictor in the data set being scored does not appear in the set of observations that was used to fit (train) the model. The model has parameters only for the values of a CLASS predictor that appear in the data set that trains the model. A new CLASS predictor value has no model parameter corresponding to it, so a predicted value cannot be computed. This condition does not apply to a CLASS variable used as the SUBJECT= variable in the REPEATED statement of a procedure since such a variable is not a predictor in the model. This condition is illustrated in the example below.
- The value of the OFFSET= variable is missing, if an OFFSET= option is available in the procedure and is specified. An offset variable is just another predictor in the model and therefore must be nonmissing in order to compute a predicted value.
- The predicted value is invalid. This issue can occur when the model should produce values in a restricted range. For example, predicted values from a logistic or probit model should be estimates of binomial means and therefore be between 0 and 1. In some cases, usually resulting from an inappropriate model specification or pathological data, the predicted value might fall outside the valid range and be reported as a missing value. Check the log for messages indicating problems.
- For nonparametric modeling procedures GAM and LOESS, predicted values cannot be computed for any data point that is not within the range of predictor values found in the data used to fit (train) the model. This is an issue when using the SCORE statement. For observations in the SCORE DATA= data set that are outside this range, predicted values are set to missing. See the Extrapolation section of SAS Note 57682 for spline models in other procedures created using the EFFECT statement.
- For survival analysis procedures LIFEREG and PHREG, the survival or cumulative distribution function estimate is missing if the observed response is missing.
- In PROC DISCRIM, a data set specified in the TESTDATA= option can be scored using the TESTOUT= option. The predicted classification variable in the TESTOUT= data set, _INTO_, will be missing for an observation if the THRESHOLD= option is specified and the largest posterior probability for the observation is less than the THRESHOLD= value.
Example
Consider the neuralgia data in the example titled "Logistic Modeling with Categorical Predictors" in the PROC LOGISTIC documentation and the following model. The Treatment predictor has three possible levels that appear in the data, A, B, and P.
proc logistic data=Neuralgia;
class Treatment;
model Pain (event="No") = Treatment Age;
store Neurmod;
run;
Suppose that you want to use the fitted model to score the following data, which can be done using the SCORE statement in PROC PLM:
data New;
input Treatment $ Age;
datalines;
A 65
B 72
P 80
A .
Z 68
;
proc plm restore=Neurmod;
score data=New out=New_scored;
run;
Since none of the above causes apply to the first three observations in New, a predicted value can be computed for each of them. However, because the fourth observation has a missing predictor value, no predicted value is computed. While it seems as though prediction is possible for the last observation, note that the Treatment value, Z, is not one of the levels for Treatment in the Neuralgia data set that trained the model. As a result, there is no parameter estimate for this nonexistent treatment and therefore no predicted value is possible.
Additional causes for exclusion but not missing prediction
Observations will also be excluded from the analysis under any of the following conditions. However, if none of the above conditions applies to an observation, then the predicted value can be computed.
- If the value of the WEIGHT variable is less than or equal to zero or missing.
- If the value of the FREQ variable is less than one or missing.
- If the response variable is missing
- When the response uses events/trials syntax in a binary-response model: if the events value is negative or missing, or if the trials value is missing or zero or negative, or if the events value is greater than the trials value
- In LIFEREG, if the lower and upper response variables are both missing or if the lower response value is greater than the upper response value.
- In PHREG, if any failure time response variable value is missing or negative.
Produce a table summarizing all missing values
An analysis of missing values can provide a table showing the numbers of observations with various patterns of missing values across the variables involved in the model. This can be used to show groups of observations excluded from the model due to missing values. But note that the table does not indicate observations that might be excluded due to invalid values.
First, use the desired procedure to fit the model and add the necessary option or statement to output a data set that adds a variable containing predicted values to your input data set. Assume this variable is called PRED. Then run PROC MI using your variables as indicated.
proc mi data=<your-data-set> nimpute=0 displaypattern=nomeans;
var PRED <response variable(s)>
<all other variables involved in the model>;
class <all character variables in VAR statement>;
fcs logistic;
ods select MissPattern;
run;
In the table that it produces, X means a value is present, O or . means it is missing. Only those observations in Group 1, with no missing values in any variable, can potentially be used in the modeling procedure, though some might still be excluded due to nonmissing but invalid values as indicated in the second list above.
Example of missing value analysis
The following statements generate 100 observations with missing values randomly appearing across all of the variables.
data nomiss;
call streaminit(453);
drop i;
do i=1 to 100;
y=rand('table',.25,.25,.25,.25);
x1=rand('uniform');
x2=rand('binomial',.5,1);
off=rand('uniform')*5;
w=rand('uniform')*10;
f=floor(rand('uniform')*10);
output;
end;
run;
data miss; set nomiss;
array v (*) y x1 x2 off w f;
do i=1 to dim(v);
if ranuni(342)<.3 then v(i)=.;
end;
drop i;
run;
PROC GENMOD is used to fit a model to the data and output a data set of that includes the predicted values. PROC MI is used as described above to obtain an analysis of missing values.
proc genmod data=miss;
class x2;
model y=x1 x2 / dist=poisson offset=off;
weight w;
freq f;
output out=out pred=pred;
run;
proc mi data=out nimpute=0 displaypattern=nomeans;
var pred y x1 x2 off w f;
ods select MissPattern;
run;
The first table, produced by GENMOD, shows that only 11 of the 100 observations were used in fitting the model. The next table, from MI, shows that 12 observations were nonmissing on all variables involved in the model and for which predicted values were produced. Observations in the remaining groups were all excluded from contributing when fitting the model because of missing values, but predictions could be obtained for those in Groups 2-8.

The MI Procedure
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
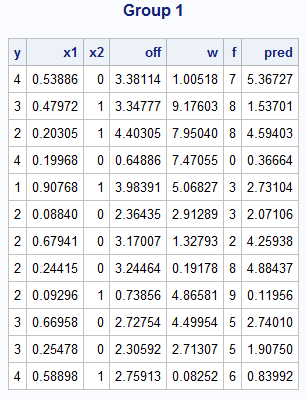
As noted above, this analysis by MI is only of missing values. It does not address the additional causes for exclusion when fitting the model. The following statements create and display a data set containing all of the observations in Group 1 which have no missing values.
data group1; set out;
if cmiss(of y x1 x2 off w f)=0;
run;
proc print noobs;
title "Group 1";
run;
Note that there is one observation in which the FREQ statement variable, F, is zero. As noted in the list of additional causes for exclusion above, zero or negative values of a FREQ statement variable are invalid and exclude the observation. This is why GENMOD reported 11 observations used and not 12.
 |
By also checking for the additional causes for exclusion, it is possible to create data sets of used and unused observations. For this model, the only applicable additional causes for exclusion are invalid WEIGHT or FREQ values. These statements produce the Used data set with 11 observations and the NotUsed data set with 89 observations, consistent with the counts shown in table from GENMOD above.
data Used; set out;
/* all model variables nonmissing; valid weights, freqs */
if cmiss(of y x1 x2 off w f)=0 and w>0 and f>=1;
run;
data NotUsed; set out;
/* some model variables missing or invalid weight, freq */
if cmiss(of pred y x1 x2 off w f) or w<=0 or f<1;
run;
Data sets of observations that could and could not be predicted can be produced by simply using the variable of predicted values saved from the modeling procedure. Data set PRED contains 34 observations, the sum of sizes of Groups 1-8, and data set NotPred contains 66 observations.
data Pred; set out;
where pred ne .;
run;
data NotPred; set out;
where pred=.;
run;
If needed, a data set of any one of the groups from the PROC MI analysis can be produced for examination using a DATA step similar to the one above. For example, the Group 9 observations can be obtained using this step.
data group9; set out;
if cmiss(of y x1 x2 w f)=0 /* none of these is missing and */
and cmiss(of off) /* any of these is missing */
;
run;
__________
NOTE 1: Some previous problems caused predicted values to incorrectly be set to missing.
- In PROC LOGISTIC prior to SAS 9.4, if the FORMAT statement is used and appears before the SCORE statement, then missing predicted values appear in the SCORE OUT= data set. Move the FORMAT statement to follow the SCORE statement to avoid this problem.
- The problem described in SAS Note 48299 affects PROC GENMOD prior to SAS 9.4 TS1M2.
- In PROC QUANTSELECT prior to SAS 9.4 TS1M3, a missing value in a predictor that is not included in the final model causes the predicted value to be missing.
NOTE 2: GLM, GENMOD, PROBIT, PHREG, LIFEREG, QUANTREG, QUANTSELECT, ROBUSTREG, SURVEYREG, SURVEYPHREG, HPLOGISTIC, HPMIXED, COUNTREG, QLIM, and possibly others.
Operating System and Release Information
| Product Family | Product | System | SAS Release | |
| Reported | Fixed* | |||
| SAS System | SAS/STAT | z/OS | ||
| OpenVMS VAX | ||||
| Microsoft® Windows® for 64-Bit Itanium-based Systems | ||||
| Microsoft Windows Server 2003 Datacenter 64-bit Edition | ||||
| Microsoft Windows Server 2003 Enterprise 64-bit Edition | ||||
| Microsoft Windows XP 64-bit Edition | ||||
| Microsoft® Windows® for x64 | ||||
| OS/2 | ||||
| Microsoft Windows 95/98 | ||||
| Microsoft Windows 2000 Advanced Server | ||||
| Microsoft Windows 2000 Datacenter Server | ||||
| Microsoft Windows 2000 Server | ||||
| Microsoft Windows 2000 Professional | ||||
| Microsoft Windows NT Workstation | ||||
| Microsoft Windows Server 2003 Datacenter Edition | ||||
| Microsoft Windows Server 2003 Enterprise Edition | ||||
| Microsoft Windows Server 2003 Standard Edition | ||||
| Microsoft Windows XP Professional | ||||
| Windows Millennium Edition (Me) | ||||
| Windows Vista | ||||
| 64-bit Enabled AIX | ||||
| 64-bit Enabled HP-UX | ||||
| 64-bit Enabled Solaris | ||||
| ABI+ for Intel Architecture | ||||
| AIX | ||||
| HP-UX | ||||
| HP-UX IPF | ||||
| IRIX | ||||
| Linux | ||||
| Linux for x64 | ||||
| Linux on Itanium | ||||
| OpenVMS Alpha | ||||
| OpenVMS on HP Integrity | ||||
| Solaris | ||||
| Solaris for x64 | ||||
| Tru64 UNIX | ||||
| SAS System | SAS/ETS | Microsoft Windows 2000 Advanced Server | ||
| Microsoft Windows 95/98 | ||||
| Microsoft Windows 8.1 Pro 32-bit | ||||
| Microsoft Windows 8.1 Pro | ||||
| Microsoft Windows 8.1 Enterprise x64 | ||||
| Microsoft Windows 8 Pro x64 | ||||
| Microsoft Windows 8.1 Enterprise 32-bit | ||||
| Microsoft Windows 8 Pro 32-bit | ||||
| Microsoft Windows 8 Enterprise 32-bit | ||||
| Microsoft Windows 8 Enterprise x64 | ||||
| OS/2 | ||||
| Microsoft Windows XP 64-bit Edition | ||||
| Microsoft® Windows® for x64 | ||||
| Microsoft Windows Server 2003 Enterprise 64-bit Edition | ||||
| Microsoft Windows Server 2003 Datacenter 64-bit Edition | ||||
| OpenVMS VAX | ||||
| Microsoft® Windows® for 64-Bit Itanium-based Systems | ||||
| Z64 | ||||
| z/OS | ||||
| Microsoft Windows 2000 Datacenter Server | ||||
| Microsoft Windows 2000 Server | ||||
| Microsoft Windows 2000 Professional | ||||
| Microsoft Windows NT Workstation | ||||
| Microsoft Windows Server 2003 Datacenter Edition | ||||
| Microsoft Windows Server 2003 Enterprise Edition | ||||
| Microsoft Windows Server 2003 Standard Edition | ||||
| Microsoft Windows Server 2003 for x64 | ||||
| Microsoft Windows Server 2008 | ||||
| Microsoft Windows Server 2008 R2 | ||||
| Microsoft Windows Server 2008 for x64 | ||||
| Microsoft Windows Server 2012 Datacenter | ||||
| Microsoft Windows Server 2012 R2 Datacenter | ||||
| Microsoft Windows Server 2012 R2 Std | ||||
| Microsoft Windows Server 2012 Std | ||||
| Microsoft Windows XP Professional | ||||
| Windows 7 Enterprise 32 bit | ||||
| Windows 7 Enterprise x64 | ||||
| Windows 7 Home Premium 32 bit | ||||
| Windows 7 Home Premium x64 | ||||
| Windows 7 Professional 32 bit | ||||
| Windows 7 Professional x64 | ||||
| Windows 7 Ultimate 32 bit | ||||
| Windows 7 Ultimate x64 | ||||
| Windows Millennium Edition (Me) | ||||
| Windows Vista | ||||
| Windows Vista for x64 | ||||
| 64-bit Enabled AIX | ||||
| 64-bit Enabled HP-UX | ||||
| 64-bit Enabled Solaris | ||||
| ABI+ for Intel Architecture | ||||
| AIX | ||||
| HP-UX | ||||
| HP-UX IPF | ||||
| IRIX | ||||
| Linux | ||||
| Linux for x64 | ||||
| Linux on Itanium | ||||
| OpenVMS Alpha | ||||
| OpenVMS on HP Integrity | ||||
| Solaris | ||||
| Solaris for x64 | ||||
| Tru64 UNIX | ||||
| Type: | Usage Note |
| Priority: | |
| Topic: | Analytics ==> analytics |
| Date Modified: | 2026-02-03 10:53:16 |
| Date Created: | 2008-06-02 12:17:42 |