The HPNLMOD Procedure

Computational Method
Multithreading
Threading refers to the organization of computational work into multiple tasks (processing units that can be scheduled by the operating system). A task is associated with a thread. Multithreading refers to the concurrent execution of threads. When multithreading is possible, substantial performance gains can be realized compared to sequential (single-threaded) execution.
The number of threads that the HPNLMOD procedure spawns is determined by the number of CPUs on a machine and can be controlled in the following ways:
-
You can specify the CPU count by using the CPUCOUNT= SAS system option. For example, if you specify the following statement, the HPNLMOD procedure determines threading as if it executed on a system that has four CPUs, regardless of the actual CPU count:
options cpucount=4;
-
You can specify the NTHREADS= option in the PERFORMANCE statement to determine the number of threads. This specification overrides the CPUCOUNT= system option. Specify NTHREADS=1 to force single-threaded execution.
The number of threads per machine is displayed in the "Performance Information" table, which is part of the default output. The HPNLMOD procedure allocates one thread per CPU.
The HPNLMOD procedure divides the data that are processed on a single machine among the threads—that is, the HPNLMOD procedure
implements multithreading by distributing computations across the data. For example, if the input data set has 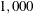 observations and PROC HPNLMOD is running with four threads, then 250 observations are associated with each thread. All operations
that require access to the data are then multithreaded. These operations include the following:
observations and PROC HPNLMOD is running with four threads, then 250 observations are associated with each thread. All operations
that require access to the data are then multithreaded. These operations include the following:
-
calculation of objective function values for the initial parameter grid
-
objective function calculation
-
gradient calculation
-
Hessian calculation
-
scoring of observations
In addition, operations on matrices such as sweeps might be multithreaded, provided that the matrices are of sufficient size to realize performance benefits from managing multiple threads for the particular matrix operation.