The SURVEYMEANS Procedure

This example illustrates how you can use PROC SURVEYMEANS to estimate population means and proportions from sample survey data. The study population is a junior high school with a total of 4,000 students in grades 7, 8, and 9. Researchers want to know how much these students spend weekly for ice cream, on average, and what percentage of students spend at least $10 weekly for ice cream.
To answer these questions, 40 students were selected from the entire student population by using simple random sampling (SRS).
Selection by simple random sampling means that all students have an equal chance of being selected and no student can be selected
more than once. Each student selected for the sample was asked how much he or she spends for ice cream per week, on average.
The SAS data set IceCream saves the responses of the 40 students:
data IceCream; input Grade Spending @@; if (Spending < 10) then Group='less'; else Group='more'; datalines; 7 7 7 7 8 12 9 10 7 1 7 10 7 3 8 20 8 19 7 2 7 2 9 15 8 16 7 6 7 6 7 6 9 15 8 17 8 14 9 8 9 8 9 7 7 3 7 12 7 4 9 14 8 18 9 9 7 2 7 1 7 4 7 11 9 8 8 10 8 13 7 2 9 6 9 11 7 2 7 9 ;
The variable Grade contains a student’s grade. The variable Spending contains a student’s response regarding how much he spends per week for ice cream, in dollars. The variable Group is created to indicate whether a student spends at least $10 weekly for ice cream: Group='more' if a student spends at least $10, or Group='less' if a student spends less than $10.
You can use PROC SURVEYMEANS to produce estimates for the entire student population, based on this random sample of 40 students:
ods graphics on; title1 'Analysis of Ice Cream Spending'; title2 'Simple Random Sample Design'; proc surveymeans data=IceCream total=4000; var Spending Group; run; ods graphics off;
The PROC SURVEYMEANS statement invokes the procedure. The TOTAL=4000 option specifies the total number of students in the
study population, or school. PROC SURVEYMEANS uses this total to adjust variance estimates for the effects of sampling from
a finite population. The VAR statement names the variables to analyze, Spending and Group.
Figure 99.1 displays the results from this analysis. There are a total of 40 observations used in the analysis. The "Class Level Information"
table lists the two levels of the variable Group. This variable is a character variable, and so PROC SURVEYMEANS provides a categorical analysis for it, estimating the relative
frequency or proportion for each level. If you want a categorical analysis for a numeric variable, you can name that variable
in the CLASS statement.
The "Statistics" table displays the estimates for each analysis variable. By default, PROC SURVEYMEANS displays the number of observations, the estimate of the mean, its standard error, and the 95% confidence limits for the mean. You can obtain other statistics by specifying the corresponding statistic-keywords in the PROC SURVEYMEANS statement.
The estimate of the average weekly ice cream expense is $8.75 for students at this school. The standard error of this estimate
if $0.85, and the 95% confidence interval for weekly ice cream expense is from $7.04 to $10.46. The analysis variable Group is a character variable, and so PROC SURVEYMEANS analyzes it as categorical, estimating the relative frequency or proportion
for each level or category. These estimates are displayed in the Mean column of the "Statistics" table. It is estimated that
57.5% of all students spend less than $10 weekly on ice cream, while 42.5% of the students spend at least $10 weekly. The
standard error of each estimate is 7.9%.
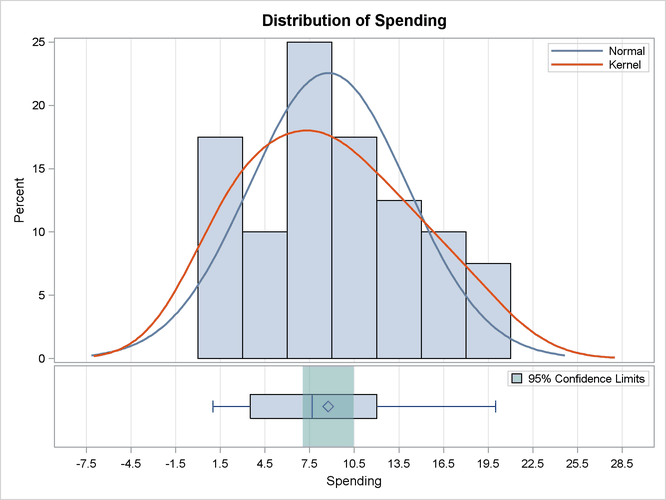
When ODS Graphics is enabled, PROC SURVEYMEANS also displays plots that depict the distribution of the continuous variables.
Figure 99.2 displays such a plot for the variable Spending.