The LOESS Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsMissing ValuesOutput Data SetsData ScalingDirect versus Interpolated Fittingk-d Trees and BlendingLocal WeightingIterative ReweightingSpecifying the Local PolynomialsSmoothing MatrixModel Degrees of FreedomStatistical Inference and Lookup Degrees of FreedomAutomatic Smoothing Parameter SelectionSparse and Approximate Degrees of Freedom ComputationScoring Data SetsODS Table NamesODS Graphics
-
Examples
- References
The OUTPUT statement creates a new SAS data set that saves the predicted values and other requested statistics that are calculated after models for all smoothing parameter values that are specified in the SMOOTH= option in the MODEL statement have been fit. If you do not specify a keyword, then only the predicted response is included.
All the variables in the original data set are included in the new data set, along with variables created by the OUTPUT statement. These new variables contain the predicted values and a variety of other statistics that are calculated for each observation in the data set.
If you want to create a SAS data set in a permanent library, you must specify a two-level name. For more information about permanent libraries and SAS data sets, see SAS Language Reference: Concepts.
You can specify the following options in the OUTPUT statement:
- OUT=SAS data set
-
specifies the name of the new data set. By default, the procedure uses the
DATAnconvention to name the new data set. - keyword <=name>
-
specifies the statistics to include in the output data set as new variables and optionally names the new variables. Specify a keyword for each desired statistic (see the following list of keywords), followed optionally by an equal sign and a variable to contain the statistic.
The new variables are named as follows: If you specify keyword=name, the new variable has the specified name. If you omit the optional =name after a keyword, then the new variable name is formed by using a default character string that identifies the statistic. In either case, if you also specify the ROWWISE option after a slash and you specify more than one dependent variable or smoothing value in the MODEL statement, the variable name is appended with an order number. For details, see the ROWWISE option.
The keywords allowed and the statistics they represent are as follows:
- PREDICTED | P
-
creates a new variable that contains predicted values. The default name is
Predicted. - RESIDUAL | R
-
creates a new variable that contains residual values, which are calculated as ACTUAL – PREDICTED. The default name is
Residual. - STD
-
creates a new variable that contains standard errors of the mean predicted values. The use of this option implicitly selects the model option DFMETHOD=EXACT even if the DFMETHOD= option has not been explicitly used. The default name is
StdErr. - T
-
creates a new variable that contains t statistics. The use of this option implicitly selects the model option DFMETHOD=EXACT even if the DFMETHOD= option has not been explicitly used. The default name is
tValue. - LCLM
-
creates a new variable that contains the lower part of
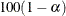 % confidence limits on the mean predicted value. By default, the 95% limits are computed; the ALPHA= option in the MODEL
statement can be used to change the significance level. The use of this option implicitly selects the model option DFMETHOD=EXACT
even if the DFMETHOD= option has not been explicitly used. The default name is
% confidence limits on the mean predicted value. By default, the 95% limits are computed; the ALPHA= option in the MODEL
statement can be used to change the significance level. The use of this option implicitly selects the model option DFMETHOD=EXACT
even if the DFMETHOD= option has not been explicitly used. The default name is LowerCL. - UCLM
-
creates a new variable that contains the upper part of
% confidence limits on the mean predicted value. By default, the 95% limits are computed; the ALPHA= option in the MODEL
statement can be used to change the significance level. The use of this option implicitly selects the model option DFMETHOD=EXACT
even if the DFMETHOD= option has not been explicitly used. The default name is UpperCL.
You can specify the following options in the OUTPUT statement after a slash (/).