The BCHOICE Procedure

The MODEL statement is required; it defines the dependent variable and the fixed effects. The fixed-effects determine the ![]() matrix of the model. The specification of effects is the same as in the GLIMMIX and MIXED procedures, where you do not specify
random effects in the MODEL statement.
matrix of the model. The specification of effects is the same as in the GLIMMIX and MIXED procedures, where you do not specify
random effects in the MODEL statement.
Table 27.3 summarizes the options available in the MODEL statement. These are subsequently discussed in detail in alphabetical order by option category.
Table 27.3: MODEL Statement Options
|
Option |
Description |
|---|---|
|
Specifies the variables for defining a choice set |
|
|
Specifies the prior of the regression coefficients |
|
|
Specifies the prior of the covariance parameter for a probit model |
|
|
Specifies the structure of the covariance matrix of the error difference for a probit model |
|
|
Controls the generation of initial values of the regression coefficients |
|
|
Specifies the prior of the log-sum coefficients for a nested logit model |
|
|
Defines the nonoverlapping nests for a nested logit model |
|
|
Constrains the log-sum coefficients to be the same for all the nests in a nested logit model |
|
|
Specifies the type of the model |
- CHOICESET=(variables)
-
specifies one or more variables for defining the choice sets. You must specify how the choice sets are constructed, and you can use more than one variable. PROC BCHOICE does not sort by the values of the choice set variable; rather, it considers the data to be from a new choice set whenever the value of the choice set variable changes from the previous observation.
-
COEFFPRIOR=NORMAL < (options)>
CPRIOR=NORMAL <(options)> -
specifies the prior distribution for the regression coefficients. The default is the normal prior
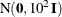 , where
, where 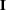 is the identity matrix. You can specify the following options, enclosed in parentheses:
is the identity matrix. You can specify the following options, enclosed in parentheses:
- INPUT=SAS-data-set
-
specifies a SAS data set that contains the mean and covariance information of the normal prior. The data set must have a
_TYPE_variable to represent the type of each observation and a variable for each regression coefficient. If the data set also contains a_NAME_variable, the values of this variable are used to identify the covariances for the_TYPE_=’COV’ observations; otherwise, the_TYPE_=’COV’ observations are assumed to be in the same order as the explanatory variables in the MODEL statement. PROC BCHOICE reads the mean vector from the observation for which_TYPE_=’MEAN’ and reads the covariance matrix from observations for which_TYPE_=’COV’. For an independent normal prior, the variances can be specified with_TYPE_=’VAR’; alternatively, the precisions (inverse of the variances) can be specified with_TYPE_=’PRECISION’. - VAR<=c>
-
specifies the normal prior
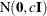 , where is the identity matrix and c is a scalar.
, where is the identity matrix and c is a scalar.
- COVPRIOR=IWISHART<(options)>
-
specifies an inverse Wishart prior distribution, IWISHART(a,b), for the covariance matrix for the vector of error differences. For models that do not have a covariance matrix for the error differences (the logit and nested logit models), this option is ignored.
You can specify the following options, enclosed in parentheses:
- DF=a
-
specifies the degrees of freedom of the inverse Wishart distribution. The default is the number of alternatives in the choice set plus 2, which is equivalent to the dimension of the covariance matrix of the error differences plus 3.
- SCALE=b
-
specifies
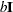 for the scale parameter of the inverse Wishart distribution, where is the identity matrix. The default is the number of alternatives in the choice set plus 2.
for the scale parameter of the inverse Wishart distribution, where is the identity matrix. The default is the number of alternatives in the choice set plus 2.
- COVTYPE=UN | VC
-
specifies the covariance structure of the error difference vector for a probit model. Although a variety of structures are available, most applications call for either COVTYPE=VC or COVTYPE=UN for the error difference vector. The COVTYPE=VC (variance components) models a different variance component for each error term. The TYPE=UN (unstructured) specifies a full structured covariance matrix. The unstructured form accommodates any pattern of correlation in addition to fitting a different variance component for each error difference term.
-
INIT=keyword-list | (numeric-list)
INITIAL=keyword-list | (numeric-list) -
specifies options for generating the initial values for the coefficients parameters that are specified as fixed-effects in the MODEL statement. By default, INIT=POSTMODE for logit models and INIT=PRIORMODE for probit models. You can specify the following keywords:
-
LAMBDAPRIOR=SEMIFLAT<(options)>
LPRIOR=SEMIFLAT<(options)> -
specifies a semi-flat prior distribution (Lahiri and Gao, 2002) for the log-sum coefficient,
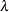 , for each nest in a nested logit model. For models that are not nested logit, this option is ignored.
, for each nest in a nested logit model. For models that are not nested logit, this option is ignored.
You can specify the following option, enclosed in parentheses:
- NEST=(numeric-list)
-
defines the nonoverlapping nests for a nested logit model. For a nested logit model, you must specify the nests for all the alternatives in the choice set. Otherwise, the standard logit model is assumed. The number of values in the list should match the number of alternatives in the choice sets, and each of the actual values represents the nest that the particular alternative goes to. For example, NEST=(1 2 1 1 2) arranges the first, third, and fourth alternatives in the first nest and the second and fifth alternatives in the second nest. Currently, this option can accommodate only two-level nested logit models.
- SAMELAMBDA
-
constrains the log-sum coefficients to be the same for all the nests in a nested logit model.
- TYPE=keyword
-
specifies the type of the model. You can specify the following keywords: