The SEQDESIGN Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsFixed-Sample Clinical TrialsOne-Sided Fixed-Sample Tests in Clinical TrialsTwo-Sided Fixed-Sample Tests in Clinical TrialsGroup Sequential MethodsStatistical Assumptions for Group Sequential DesignsBoundary ScalesBoundary VariablesType I and Type II ErrorsUnified Family MethodsHaybittle-Peto MethodWhitehead MethodsError Spending MethodsAcceptance (beta) BoundaryBoundary Adjustments for Overlapping Lower and Upper beta BoundariesSpecified and Derived ParametersApplicable Boundary KeysSample Size ComputationApplicable One-Sample Tests and Sample Size ComputationApplicable Two-Sample Tests and Sample Size ComputationApplicable Regression Parameter Tests and Sample Size ComputationAspects of Group Sequential DesignsSummary of Methods in Group Sequential DesignsTable OutputODS Table NamesGraphics OutputODS Graphics
-
ExamplesCreating Fixed-Sample DesignsCreating a One-Sided O’Brien-Fleming DesignCreating Two-Sided Pocock and O’Brien-Fleming DesignsGenerating Graphics Display for Sequential DesignsCreating Designs Using Haybittle-Peto MethodsCreating Designs with Various Stopping CriteriaCreating Whitehead’s Triangular DesignsCreating a One-Sided Error Spending DesignCreating Designs with Various Number of StagesCreating Two-Sided Error Spending Designs with and without Overlapping Lower and Upper beta BoundariesCreating a Two-Sided Asymmetric Error Spending Design with Early Stopping to Reject H0Creating a Two-Sided Asymmetric Error Spending Design with Early Stopping to Reject or Accept H0Creating a Design with a Nonbinding Beta BoundaryComputing Sample Size for Survival Data
- References
The SEQDESIGN procedure provides sample size computation for two-sample tests: the test for the difference between two normal means, tests for binomial proportions, and the log-rank test for two survival distributions. These tests for binomial proportions include the test for the difference between two binomial proportions, the log odds ratio test for binomial proportions, and the log relative risk test for binomial proportions,
For a test of difference between two sample means, the required sample size depends on the assumed sample variances. Similarly, for a test of two-sample proportions, the required sample size depends on the assumed sample proportions. For a log-rank test of two survival distributions, the required sample size depends on the assumed sample hazard rates, accrual rate, and accrual time.
If the REF=NULLPROP or REF=NULLHAZARD option is specified, the proportions or hazard rates under the null hypothesis are used to derive the required sample size or number of events. Otherwise, the REF=PROP option (which is the default in the MODEL=TWOSAMPLEFREQ option) or the REF=HAZARD option (which is the default in the MODEL=TWOSAMPLESURVIVAL option) uses proportions or hazard rates under the alternative hypothesis to derive the required sample size or number of events.
The MODEL=TWOSAMPLEMEAN option in the SAMPLESIZE statement derives the sample size required to test the difference between
the means of two normal populations ![]() and
and ![]() by using the null hypothesis
by using the null hypothesis ![]() , where
, where ![]() .
.
At stage k, the MLE for ![]() is computed as
is computed as
where ![]() and
and ![]() are the values of the jth observation available in the kth stage groups
are the values of the jth observation available in the kth stage groups A and B, respectively, and ![]() and
and ![]() are the cumulative sample sizes at stage k for these two groups.
are the cumulative sample sizes at stage k for these two groups.
The statistic ![]() has a normal distribution
has a normal distribution
where the information ![]() is the inverse of the variance
is the inverse of the variance ![]() .
.
Then the standardized statistic
Thus, to test the hypothesis ![]() against an upper alternative
against an upper alternative ![]() ,
, ![]() is rejected at stage k if the statistic
is rejected at stage k if the statistic ![]() , the upper
, the upper ![]() boundary for the standardized Z statistic at stage k.
boundary for the standardized Z statistic at stage k.
If the variances ![]() and
and ![]() are unknown, the sample variances can be used to derive the information
are unknown, the sample variances can be used to derive the information ![]() if it is assumed that each sample variance is computed from a large sample such that the test statistic has an approximately
normal distribution.
if it is assumed that each sample variance is computed from a large sample such that the test statistic has an approximately
normal distribution.
The maximum information is needed to derive the required sample size. If the maximum information is not specified or derived
in the procedure, the alternative reference ![]() specified in the MEANDIFF option is used to derive the maximum information.
specified in the MEANDIFF option is used to derive the maximum information.
Note that in order to derive the sample sizes ![]() and
and ![]() uniquely from the information,
uniquely from the information, ![]() is assumed for
is assumed for ![]() , where
, where ![]() is the constant allocation ratio computed from the WEIGHT=
is the constant allocation ratio computed from the WEIGHT=![]()
![]() option in the SAMPLESIZE statement.
option in the SAMPLESIZE statement.
In PROC SEQDESIGN, the computed total sample sizes for the two groups are
where ![]() is the maximum information derived in the SEQDESIGN procedure, R is the constant allocation ratio, and
is the maximum information derived in the SEQDESIGN procedure, R is the constant allocation ratio, and ![]() and
and ![]() are the specified standard deviations.
are the specified standard deviations.
For ![]() , the two sample sizes are equal, then
, the two sample sizes are equal, then
If the variances from the two groups are equal, ![]() , then the total sample sizes for the two groups are
, then the total sample sizes for the two groups are
and the total sample size is
Furthermore, for ![]() , the two sample sizes are equal, then
, the two sample sizes are equal, then
With an available maximum information, you can specify the MODEL=TWOSAMPLEMEAN( WEIGHT= R STDDEV= ![]() ) option in the SAMPLESIZE statement to compute the required total sample size and individual sample size at each stage. A
procedure such as PROC GLM can be used to derive the two-sample Z test for the mean difference.
) option in the SAMPLESIZE statement to compute the required total sample size and individual sample size at each stage. A
procedure such as PROC GLM can be used to derive the two-sample Z test for the mean difference.
The MODEL=TWOSAMPLEFREQ(TEST=PROP) option in the SAMPLESIZE statement derives the sample size required to test the difference
between two binomial populations with ![]() , where
, where ![]() . At stage k, the MLE for
. At stage k, the MLE for ![]() is
is
where ![]() and
and ![]() are the values of the jth observation available in the kth stage for groups
are the values of the jth observation available in the kth stage for groups A and B, respectively, and ![]() and
and ![]() are the cumulative sample sizes at stage k for these two groups.
are the cumulative sample sizes at stage k for these two groups.
For sufficiently large sample sizes ![]() and
and ![]() , the statistic
, the statistic ![]() has an approximate normal distribution
has an approximate normal distribution
where the information is the inverse of the variance
Thus, the standardized statistic
In practice, ![]() and
and ![]() , the estimated sample proportions for groups
, the estimated sample proportions for groups A and B, respectively, at stage k, can be used to derive the information ![]() and the test statistic
and the test statistic ![]() . Thus, to test the hypothesis
. Thus, to test the hypothesis ![]() against an upper alternative
against an upper alternative ![]() ,
, ![]() is rejected at stage k if the statistic
is rejected at stage k if the statistic ![]() , the upper
, the upper ![]() boundary for the standardized Z statistic at stage k.
boundary for the standardized Z statistic at stage k.
The maximum information ![]() is needed to derive the required sample size. If the maximum information is not specified or derived with the ALTREF= option
in the procedure, the PROP= option in the SAMPLESIZE statement is used to provide proportions under the alternative hypothesis
for the alternative reference and then to derive the maximum information.
is needed to derive the required sample size. If the maximum information is not specified or derived with the ALTREF= option
in the procedure, the PROP= option in the SAMPLESIZE statement is used to provide proportions under the alternative hypothesis
for the alternative reference and then to derive the maximum information.
The proportions in the two groups are needed to derive the sample size. Also, in order to derive the sample sizes ![]() and
and ![]() uniquely from the information,
uniquely from the information, ![]() is assumed for
is assumed for ![]() , where
, where ![]() is the constant allocation ratio computed from the WEIGHT=
is the constant allocation ratio computed from the WEIGHT=![]()
![]() option in the SAMPLESIZE statement. Then
option in the SAMPLESIZE statement. Then
In PROC SEQDESIGN, the total sample sizes in the two groups are computed as
where ![]() is the constant allocation ratio, and
is the constant allocation ratio, and ![]() and
and ![]() are proportions specified with the REF= option:
are proportions specified with the REF= option:
-
REF=NULLPROP uses proportions under
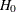 :
: 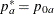 ,
, 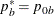
-
REF=AVGNULLPROP uses the average proportion under
: 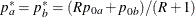
-
REF=PROP uses proportions under
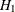 :
: 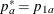 ,
, 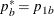
-
REF=AVGPROP uses the average proportion under
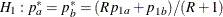
The total sample size is given by
For ![]() , the two sample sizes are equal,
, the two sample sizes are equal,
You can specify the MODEL=TWOSAMPLEFREQ( TEST=PROP WEIGHT=R ) option in the SAMPLESIZE statement to compute the required total sample size and individual sample size at each stage. A procedure such as PROC GENMOD with the default DIST=NORMAL option in the MODEL statement can be used to derive the two-sample Z test for proportion difference.
The MODEL=TWOSAMPLEFREQ(TEST=LOGOR) option in the SAMPLESIZE statement derives the sample size required to test two binomial proportions by using a log odds ratio statistic. The odds ratio is the ratio of the odds in one group to the odds in the other group, and the log odds ratio is the logarithm of the odds ratio
The hypothesis of no difference between two proportions, ![]() , can be tested through the null hypothesis
, can be tested through the null hypothesis ![]() , where
, where ![]() is the log odds ratio. For example, with
is the log odds ratio. For example, with ![]() and
and ![]() , it corresponds to the equivalent hypothesis
, it corresponds to the equivalent hypothesis ![]() and
and ![]() .
.
The maximum likelihood estimate of ![]() is given by
is given by
with an asymptotic variance
where I is the information (Diggle et al., 2002, pp. 341–342). That is, the standardized statistic
In practice, ![]() and
and ![]() , the estimated sample proportions for groups
, the estimated sample proportions for groups A and B, respectively, at stage k, can be used to derive the information ![]() and the test statistic
and the test statistic ![]() if the two sample sizes
if the two sample sizes ![]() and
and ![]() are sufficiently large such that the test statistic has an approximately normal distribution.
are sufficiently large such that the test statistic has an approximately normal distribution.
The maximum information ![]() is needed to derive the required sample size. If the maximum information is not specified or derived with the ALTREF= option
in the procedure, the PROP= option in the SAMPLESIZE statement is used to provide proportions under the alternative hypothesis
for the alternative reference and then to derive the maximum information.
is needed to derive the required sample size. If the maximum information is not specified or derived with the ALTREF= option
in the procedure, the PROP= option in the SAMPLESIZE statement is used to provide proportions under the alternative hypothesis
for the alternative reference and then to derive the maximum information.
In order to derive the sample sizes ![]() and
and ![]() uniquely from the information,
uniquely from the information, ![]() is assumed for
is assumed for ![]() , where
, where ![]() is the constant allocation ratio computed from the WEIGHT=
is the constant allocation ratio computed from the WEIGHT=![]()
![]() option in the SAMPLESIZE statement. Then with
option in the SAMPLESIZE statement. Then with
the sample size can be computed.
In PROC SEQDESIGN, the total sample sizes in the two groups are computed as
where ![]() is the constant allocation ratio, and
is the constant allocation ratio, and ![]() and
and ![]() are proportions specified with the REF= option:
are proportions specified with the REF= option:
-
REF=NULLPROP uses proportions under
: ,
-
REF=AVGNULLPROP uses the average proportion under
:
-
REF=PROP uses proportions under
: ,
-
REF=AVGPROP uses the average proportion under
You can specify the MODEL=TWOSAMPLEFREQ( TEST=LOGOR WEIGHT=R) option in the SAMPLESIZE statement to compute the required total sample size and individual sample size at each stage. A procedure such as PROC LOGISTIC can be used to derive the log odds ratio statistic.
The MODEL=TWOSAMPLEFREQ(TEST=LOGRR) option in the SAMPLESIZE statement derives the sample size required to test two binomial proportions by using a log relative risk statistic. The relative risk is the ratio of the proportion in one group to the proportion in the other group. The log relative risk statistic is the logarithm of the relative risk
The hypothesis of no difference between two proportions, ![]() , can be tested through the null hypothesis
, can be tested through the null hypothesis ![]() . For example, with
. For example, with ![]() and
and ![]() , it corresponds to the equivalent hypothesis
, it corresponds to the equivalent hypothesis ![]() and
and ![]() .
.
The maximum likelihood estimate of ![]() is given by
is given by
with an asymptotic variance
where I is the information (Chow and Liu, 1998, p. 329).
In practice, ![]() and
and ![]() , the estimated sample proportions for groups
, the estimated sample proportions for groups A and B, respectively, at stage k, are used to derive the information ![]() and the test statistic
and the test statistic ![]() .
.
The maximum information ![]() and proportions
and proportions ![]() and
and ![]() are needed to derive the required sample size. If the maximum information is not specified or derived with the ALTREF= option
in the procedure, the PROP= option in the SAMPLESIZE statement is used to provide proportions under the alternative hypothesis
for the alternative reference and then to derive the maximum information.
are needed to derive the required sample size. If the maximum information is not specified or derived with the ALTREF= option
in the procedure, the PROP= option in the SAMPLESIZE statement is used to provide proportions under the alternative hypothesis
for the alternative reference and then to derive the maximum information.
Note that in order to derive the sample sizes ![]() and
and ![]() uniquely from the information,
uniquely from the information, ![]() is assumed for
is assumed for ![]() , where
, where ![]() is the constant allocation ratio computed from the WEIGHT=
is the constant allocation ratio computed from the WEIGHT=![]()
![]() option in the SAMPLESIZE statement. Then the sample size can be computed from
option in the SAMPLESIZE statement. Then the sample size can be computed from
In PROC SEQDESIGN, the computed sample sizes in the two groups are
where ![]() is the constant allocation ratio, and
is the constant allocation ratio, and ![]() and
and ![]() are proportions specified with the REF= option:
are proportions specified with the REF= option:
-
REF=NULLPROP uses proportions under
: ,
-
REF=AVGNULLPROP uses the average proportion under
:
-
REF=PROP uses proportions under
: ,
-
REF=AVGPROP uses the average proportion under
You can specify the MODEL=TWOSAMPLEFREQ( TEST=LOGRR WEIGHT=R) option in the SAMPLESIZE statement to compute the required total sample size and individual sample size at each stage. A procedure such as PROC LOGISTIC can be used to derive the log relative risk statistic.
The MODEL=TWOSAMPLESURV option in the SAMPLESIZE statement derives the number of events required for a log-rank test of two survival distributions. The analysis of survival data involves the survival times for both censored and uncensored data. A noncensored survival time is the time from treatment to an event such as remission or relapse for an individual. A censored survival time is the time from treatment to the time of analysis for an individual surviving at that time, and the status is unknown beyond that time.
Let T be the random variable of the survival time. Then the survival function
is the probability that an individual from the population has a survival time that exceeds t. And the hazard function is given by
where ![]() is the density function of T.
is the density function of T.
The hazard functions can be used to test the equality of two survival distributions ![]() with the null hypothesis
with the null hypothesis ![]() , where
, where ![]() and
and ![]() are survival functions for groups
are survival functions for groups A and B, respectively, and ![]() and
and ![]() are the corresponding hazard functions.
are the corresponding hazard functions.
If the two hazards are proportional, ![]() , where
, where ![]() is a constant, then an equivalent null hypothesis is
is a constant, then an equivalent null hypothesis is
Alternatively, another equivalent null hypothesis is given by
Suppose that the hazard rate h is a constant. Then with a specified median survival time ![]() , the hazard rate can be derived from the equation
, the hazard rate can be derived from the equation
Denote the distinct event times at stage k as ![]() , where
, where ![]() is the total number of distinct event times. Then the score statistic is the log-rank statistic (Jennison and Turnbull 2000, pp. 259–261; Whitehead 1997, pp. 36–39)
is the total number of distinct event times. Then the score statistic is the log-rank statistic (Jennison and Turnbull 2000, pp. 259–261; Whitehead 1997, pp. 36–39)
where ![]() is the number of events from group
is the number of events from group A and ![]() is the number of expected events from
is the number of expected events from A. The number of expected events from ![]() is computed as
is computed as
where ![]() is the number of events from both groups,
is the number of events from both groups, ![]() is the number of individuals from the treatment group who survived up to time
is the number of individuals from the treatment group who survived up to time ![]() , and
, and ![]() is the number of individuals from both groups who survived up to time
is the number of individuals from both groups who survived up to time ![]() .
.
If the number of events ![]() is small relative to
is small relative to ![]() , the number of individuals survived up to time
, the number of individuals survived up to time ![]() , then with a sufficiently large sample size,
, then with a sufficiently large sample size, ![]() has an approximately normal distribution
has an approximately normal distribution
where the variance of ![]() is the estimated information
is the estimated information
In order to derive the number of events from the information ![]() ,
, ![]() is assumed for
is assumed for ![]() , where
, where ![]() is the constant allocation ratio computed from the WEIGHT=
is the constant allocation ratio computed from the WEIGHT=![]()
![]() option in the SAMPLESIZE statement.
option in the SAMPLESIZE statement.
The maximum information ![]() is needed to derive the required sample size. If the maximum information is specified or derived with the ALTREF= option
in the procedure, the HAZARD=, MEDSURVTIME=, and HAZARDRATIO= options are not applicable. Otherwise, the HAZARD=, MEDSURVTIME=,
or HAZARDRATIO= option is used to compute the alternative reference and then to derive the maximum information for the sample
size calculation.
is needed to derive the required sample size. If the maximum information is specified or derived with the ALTREF= option
in the procedure, the HAZARD=, MEDSURVTIME=, and HAZARDRATIO= options are not applicable. Otherwise, the HAZARD=, MEDSURVTIME=,
or HAZARDRATIO= option is used to compute the alternative reference and then to derive the maximum information for the sample
size calculation.
With ![]() , if the number of events is few relative to the number of individuals who survived, then
, if the number of events is few relative to the number of individuals who survived, then ![]() , and
, and
where ![]() is the total number of events.
is the total number of events.
Thus, the required total number of events
For a study group, if the hazard rate is constant, corresponding to an exponential survival distribution, and the individual
accrual is uniform in the accrual time ![]() with a constant accrual rate
with a constant accrual rate ![]() , then the required total sample size and sample size at each stage can be derived. See the section Input Number of Events for Fixed-Sample Design for a detailed description of the sample size computation that uses hazard rates, accrual rate, and accrual time.
, then the required total sample size and sample size at each stage can be derived. See the section Input Number of Events for Fixed-Sample Design for a detailed description of the sample size computation that uses hazard rates, accrual rate, and accrual time.
You can specify the MODEL=TWOSAMPLESURVIVAL option in the SAMPLESIZE statement to compute the required total number of events
and individual number of events at each stage. With the specifications of hazard rates, accrual rate, and accrual time, the
required total sample size and individual sample size at each stage can also be derived. If the REF=NULLHAZARD option is specified,
the hazard rates under the null hypothesis, ![]() and
and ![]() , are used in the sample size computation. Otherwise, the hazard rates under the alternative hypothesis,
, are used in the sample size computation. Otherwise, the hazard rates under the alternative hypothesis, ![]() and
and ![]() , are used. A procedure such as PROC LIFETEST can be used to derive the log-rank statistic.
, are used. A procedure such as PROC LIFETEST can be used to derive the log-rank statistic.