The PLM Procedure

| Analysis Based on Posterior Estimates |
If an item store that are saved from a Bayesian analysis (by PROC GENMOD or PROC PHREG), then PROC PLM can perform sampling-based inference based on Bayes posterior estimates that are saved in the item store. For example, the following statements request that a Bayesian analysis and results be saved to an item store named sasuser.gmd. For the Bayesian analysis, the random number generator seed is set to 1. By default, a noninformative distribution is set as the prior distribution for the regression coefficients and the posterior sample size is 10,000.
proc genmod data=gs; class a b; model y = a b; bayes seed=1; store sasuser.gmd / label='Bayesian Analysis'; run;
When the PLM procedure opens the item store sasuser.gmd, it detects that the results were saved from a Bayesian analysis. The posterior sample of regression coefficient estimates are then loaded to perform statistical inference tasks.
The majority of postprocessing tasks involve inference based on an estimable linear function 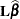 , which often requires its mean and variance. When the standard frequentist analyses are performed, the mean and variance have explicit forms because the parameter estimate
, which often requires its mean and variance. When the standard frequentist analyses are performed, the mean and variance have explicit forms because the parameter estimate  is analytically tractable. However, explicit forms are not usually available when Bayesian models are fitted. Instead, empirical means and variance-covariance matrices for the estimable function are constructed from the posterior sample.
is analytically tractable. However, explicit forms are not usually available when Bayesian models are fitted. Instead, empirical means and variance-covariance matrices for the estimable function are constructed from the posterior sample.
Let 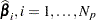 denote the
denote the  vectors of posterior sample estimates of
vectors of posterior sample estimates of 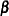 saved in sasuser.gmd. Use these vectors to construct the posterior sample of estimable functions
saved in sasuser.gmd. Use these vectors to construct the posterior sample of estimable functions  . The posterior mean of the estimable function is thus
. The posterior mean of the estimable function is thus
 |
and the posterior variance of the estimable function is
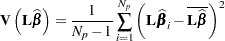 |
Sometimes statistical inference on a transformation of is requested. For example, the EXP option for the ESTIMATE and LSMESTIMATE statements requests analysis based on 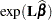 , exponentiation of the estimable function. If this type of analysis is requested, the posterior sample of transformed estimable functions is constructed by transforming each of the estimable function evaluated at the posterior sample:
, exponentiation of the estimable function. If this type of analysis is requested, the posterior sample of transformed estimable functions is constructed by transforming each of the estimable function evaluated at the posterior sample:  . The posterior mean and variance for
. The posterior mean and variance for 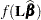 are then computed from the constructed sample to make the inference:
are then computed from the constructed sample to make the inference:
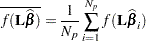 |
 |
After obtaining the posterior mean and variance, the PLM procedure proceeds to perform statistical inference tasks based on them.