The PLM Procedure

| BY Processing and the PLM Procedure |
When a BY statement is in effect for the anlaysis that creates an item store, the information about BY variables and BY-group-specific modeling results are transferred to the item store. In this case, the PLM procedure automatically assumes a processing mode for the item store that is akin to BY processing, with the PLM statements being applied in turn for each of the BY groups. Also, you can then obtain a table of BY groups with the BYVAR option in the SHOW statement. The "Source Information" table also displays the variable names of the BY variables if BY groups are present. The WHERE statement can be used to restrict the analysis to specific BY groups that meet the conditions of the WHERE expression.
See Example 68.4 for an example that uses BY-group-specific information in the source item store.
As with procedures that operate on input data sets, the BY variable information is added automatically to any output data sets and ODS tables produced by the PLM procedure.
When you score a data set with the SCORE statement and the item store contains BY variables, three situations can arise:
None of the BY variables are present in the scoring data set. In this situation the results of the BY groups in the item store are applied in turn to the entire scoring data set. For example, if the scoring data set contains 50 observations and no BY-variable information, the number of observations in the output data set of the SCORE statement equals
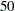 times the number of BY groups.
times the number of BY groups. The scoring data set contains only a part of the BY variables, or the variables have different type or format. The PLM procedure does not process such an incompatible scoring data set.
All BY variables are in the scoring data set in the same type and format as when the item store was created. The BY-group-specific results are applied to each observation in the scoring data set. The scoring data set does not have to be sorted or grouped by the BY variables. However, it is computationally more efficient if the scoring data set is arranged by groups of the BY variables.