The HPLOGISTIC Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsMissing ValuesResponse DistributionsLog-Likelihood FunctionsExistence of Maximum Likelihood EstimatesUsing Validation and Test DataModel Fit and Assessment StatisticsThe Hosmer-Lemeshow Goodness-of-Fit TestComputational Method: MultithreadingChoosing an Optimization AlgorithmDisplayed OutputODS Table Names
-
Examples
- References
Response Distributions
The response distribution is the probability distribution of the response (target) variable. The HPLOGISTIC procedure can fit data for the following distributions:
-
binary distribution
-
binomial distribution
-
multinomial distribution
The expressions for the log-likelihood functions of these distributions are given in the next section.
The binary (or Bernoulli) distribution is the elementary distribution of a discrete random variable that can take on two values with probabilities p and 1 – p. Suppose the random variable is denoted Y and
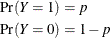
The value associated with probability p is often termed the event or "success"; the complementary event is termed the non-event or "failure." A Bernoulli experiment is a random draw from a binary distribution and generates events with probability p.
If 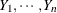 are n independent Bernoulli random variables, then their sum follows a binomial distribution. In other words, if
are n independent Bernoulli random variables, then their sum follows a binomial distribution. In other words, if 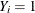 denotes an event (success) in the ith Bernoulli trial, a binomial random variable is the number of events (successes) in n independent Bernoulli trials. If you use the events/trials syntax in the MODEL
statement, the HPLOGISTIC procedure fits the model as if the data had arisen from a binomial distribution. For example, the
following statements fit a binomial regression model with regressors
denotes an event (success) in the ith Bernoulli trial, a binomial random variable is the number of events (successes) in n independent Bernoulli trials. If you use the events/trials syntax in the MODEL
statement, the HPLOGISTIC procedure fits the model as if the data had arisen from a binomial distribution. For example, the
following statements fit a binomial regression model with regressors x1 and x2. The variables e and t represent the events and trials for the binomial distribution:
proc hplogistic; model e/t = x1 x2; run;
If the events/trials syntax is used, then both variables must be numeric and the value of the events variable cannot be less than 0 or exceed the value of the trials variable. A "Response Profile" table is not produced for binomial data.
The multinomial distribution is a generalization of the binary distribution and allows for more than two outcome categories. Because there are more than two possible outcomes for the multinomial distribution, the terminology of "successes," "failures," "events," and "non-events" no longer applies. With multinomial data, these outcomes are generically referred to as "categories" or levels.
Whenever the HPLOGISTIC procedure determines that the response variable has more than two levels (unless the events/trials syntax is used), the procedure fits the model as if the data had arisen from a multinomial distribution. By default, it is then assumed that the response categories are ordered and a cumulative link model is fit by applying the default or specified link function. If the response categories are unordered, then you should fit a generalized logit model by choosing LINK=GLOGIT in the MODEL statement.