The HPLMIXED Procedure

OUTPUT <OUT=SAS-data-set> <keyword <=name>>…<keyword <=name>> <options> ;
The OUTPUT statement creates a data set that contains predicted values and residual diagnostics, which are computed after the model is fit. The variables in the input data set are not included in the output data set, in order to avoid data duplication for large data sets; however, variables that are specified in the ID statement are included. By default, only predicted values are included in the output data set.
If the input data are in distributed form, in which access of data in a particular order cannot be guaranteed, the HPLMIXED procedure copies the distribution or partition key to the output data set so that its contents can be joined with the input data.
For example, suppose that the data set Scores contains the variables Score, Machine, and Person. The following statements fit a model that has fixed machine and random person effects and save the predicted and residual
values to the data set IgausOut:
proc hplmixed data = Scores; class machine person score; model score = machine; random person; output out=igausout pred=p resid=r; run;
You can specify the following syntax element in the OUTPUT statement:
- OUT=SAS-data-set
-
specifies the name of the output data set. If the OUT= option is omitted, PROC HPLMIXED uses the
DATAnconvention to name the output data set.A keyword can appear multiple times in the OUTPUT statement. Table 8.4 lists the keywords and the default names that PROC HPLMIXED assigns if you do not specify a name. In this table, y denotes the response variable.
Table 8.4: Keywords for Output Statistics
Keyword
Description
Expression
Name
PRED
Linear predictor
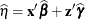
Pred
PREDPA
Marginal linear predictor
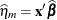
PredPA
RESIDUAL
Residual
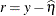
Resid
RESIDUALPA
Marginal residual
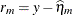
ResidPA
The marginal linear predictor and marginal residual are also referred to as the predicted population average (PREDPA) and residual population average (RESIDUALPA), respectively. You can use the following shortcuts to request statistics: PRED for PREDICTED and RESID for RESIDUAL.
You can specify the following option in the OUTPUT statement after a slash (/):
- ALLSTATS
-
requests that all statistics be computed. If you do not use a keyword to assign a name, PROC HPLMIXED uses the default name.