The MVPMODEL Procedure

Overview: MVPMODEL Procedure
The MVPMODEL procedure is used in conjunction with the MVPMONITOR and MVPDIAGNOSE procedures to monitor multivariate process variation over time, to determine whether the process is stable, and to detect and diagnose changes in a stable process. Collectively these three procedures are referred to as the MVP procedures. See Chapter 10: Introduction to Multivariate Process Monitoring Procedures, for a description of how the MVP procedures work together, and Chapter 13: The MVPMONITOR Procedure, and Chapter 11: The MVPDIAGNOSE Procedure, for details about the other MVP procedures.
The MVPMODEL procedure provides computational and graphical tools for building a principal component model from multivariate
process data in which the measured variables are continuous and correlated. This model then serves as input to the other MVP
procedures, described in Chapter 11: The MVPDIAGNOSE Procedure, and Chapter 13: The MVPMONITOR Procedure. The MVPMONITOR procedure creates various multivariate control charts, including 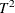 charts and SPE (squared prediction error) charts, which are used to detect and diagnose changes in the process. Multivariate
control charts can detect unusual variation that would not be detected by individually monitoring the variables with univariate
control charts, such as Shewhart charts.
charts and SPE (squared prediction error) charts, which are used to detect and diagnose changes in the process. Multivariate
control charts can detect unusual variation that would not be detected by individually monitoring the variables with univariate
control charts, such as Shewhart charts.
The MVPMODEL procedure implements principal component analysis (PCA) techniques that evolved in the field of chemometrics
for monitoring hundreds or even thousands of correlated process variables; see Kourti and MacGregor (1995, 1996) for an introduction. These techniques differ from the classical multivariate chart in which Hotelling’s statistic is computed as a distance from the multivariate mean scaled by the covariance matrix of the variables; see Alt
(1985). Instead, principal component methods compute based on a small number of principal components that model most of the variation in the data.
One advantage of PCA methods over the classical chart is that they avoid computational issues that arise when the process measurement variables are collinear and their covariance
matrix is nearly singular. A second advantage is that they offer diagnostic tools for interpreting unusual values of . A third advantage is that by projecting the data to a low-dimensional subspace, a principal component model more adequately
describes the variation in a multivariate process, which is often driven by a small number of underlying factors that are
not directly observable.