PCHART Statement: SHEWHART Procedure

Constructing Charts for Proportion Nonconforming (p Charts)
The following notation is used in this section:
|
p |
expected proportion of nonconforming items produced by the process |
|
|
|
proportion of nonconforming items in the ith subgroup |
|
|
|
number of nonconforming items in the ith subgroup |
|
|
|
number of items in the ith subgroup |
|
|
|
average proportion of nonconforming items taken across subgroups:
|
|
|
N |
number of subgroups |
|
|
|
incomplete beta function:
for |
Plotted Points
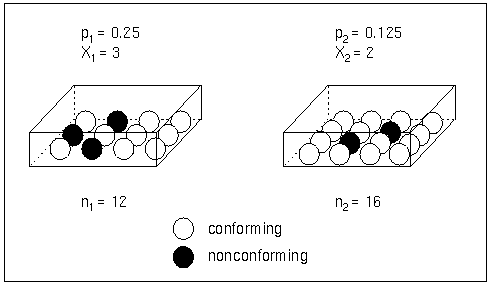
Each point on a p chart represents the observed proportion (![]() ) of nonconforming items in a subgroup. For example, suppose the second subgroup (see Figure 17.68) contains 16 items, of which two are nonconforming. The point plotted for the second subgroup is
) of nonconforming items in a subgroup. For example, suppose the second subgroup (see Figure 17.68) contains 16 items, of which two are nonconforming. The point plotted for the second subgroup is ![]() .
.
Figure 17.68: Proportions Versus Counts
Note that an ![]() chart displays the number (count) of nonconforming items
chart displays the number (count) of nonconforming items ![]() . You can use the NPCHART statement to create
. You can use the NPCHART statement to create ![]() charts; see NPCHART Statement: SHEWHART Procedure.
charts; see NPCHART Statement: SHEWHART Procedure.
Central Line
By default, the central line on a p chart indicates an estimate of p that is computed as ![]() . If you specify a known value (
. If you specify a known value (![]() ) for p, the central line indicates the value of
) for p, the central line indicates the value of ![]() .
.
Control Limits
You can compute the limits in the following ways:
-
as a specified multiple (k) of the standard error of
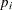 above and below the central line. The default limits are computed with k = 3 (these are referred to as
above and below the central line. The default limits are computed with k = 3 (these are referred to as 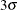 limits).
limits).
-
as probability limits defined in terms of
 , a specified probability that
, a specified probability that 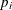 exceeds the limits
exceeds the limits
The lower and upper control limits, LCL and UCL, respectively, are computed as
|
|
|
|
|
|
|
|
A lower probability limit for ![]() can be determined using the fact that
can be determined using the fact that
![\[ \begin{array}{ll} P\{ p_ i < \mbox{LCL}\} & = 1 - P\{ p_ i \geq \mbox{LCL}\} \\ & = 1 - P\{ X_ i \geq n_ i\mbox{LCL}\} \\ & = 1 - I_{\bar{p}}(n_ i\mbox{LCL},n_ i+1-n_ i\mbox{LCL}) \\ & = I_{1- \bar{p}}(n_ i+1-n_ i\mbox{LCL},n_ i\mbox{LCL}) \\ \end{array} \]](images/qcug_shewhart0222.png) |
Refer to Johnson, Kotz, and Kemp (1992). This assumes that the process is in statistical control and that ![]() is binomially distributed. The lower probability limit LCL is then calculated by setting
is binomially distributed. The lower probability limit LCL is then calculated by setting
|
|
and solving for LCL. Similarly, the upper probability limit for ![]() can be determined using the fact that
can be determined using the fact that
|
|
The upper probability limit UCL is then calculated by setting
|
|
and solving for UCL. The probability limits are asymmetric around the central line. Note that both the control limits and
probability limits vary with ![]() .
.
You can specify parameters for the limits as follows:
-
Specify k with the SIGMAS= option or with the variable
_SIGMAS_in a LIMITS= data set. -
Specify
with the ALPHA= option or with the variable _ALPHA_in a LIMITS= data set. -
Specify a constant nominal sample size
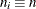 for the control limits with the LIMITN= option or with the variable
for the control limits with the LIMITN= option or with the variable _LIMITN_in a LIMITS= data set. -
Specify
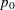 with the P0= option or with the variable
with the P0= option or with the variable _P_in a LIMITS= data set.