XCHART Statement: CUSUM Procedure
- Overview
-
Getting Started

-
Syntax
-
Details
Basic Notation for Cusum Charts Formulas for Cumulative Sums Defining the Decision Interval for a One-Sided Cusum Scheme Defining the V-Mask for a Two-Sided Cusum Scheme Designing a Cusum Scheme Cusum Charts Compared with Shewhart Charts Methods for Estimating the Standard Deviation Output Data Sets ODS Tables ODS Graphics Input Data Sets Missing Values
-
Examples
Methods for Estimating the Standard Deviation
It is recommended practice to provide a stable estimate or standard value for  with either the SIGMA0= option or the variable _STDDEV_ in a LIMITS= data set. However, if such a value is not available, you can compute an estimate
with either the SIGMA0= option or the variable _STDDEV_ in a LIMITS= data set. However, if such a value is not available, you can compute an estimate 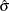 from the data, as described in this section.
from the data, as described in this section.
This section provides formulas for various methods used to estimate the standard deviation . One method is applicable with individual measurements, and three are applicable with subgrouped data. The methods can be requested with the SMETHOD= option.
Method for Individual Measurements
When the cumulative sums are calculated from individual observations
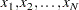 |
rather than subgroup samples of two or more observations, the CUSUM procedure estimates as 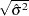 , where
, where
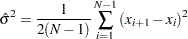 |
where 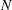 is the number of observations. Wetherill (1977) states that the estimate of the variance is biased if the measurements are autocorrelated.
is the number of observations. Wetherill (1977) states that the estimate of the variance is biased if the measurements are autocorrelated.
Note that you can compute alternative estimates (for instance, robust estimates or estimates based on variance components models) by analyzing the data with SAS modeling procedures or your own DATA step program. Such estimates can be passed to the CUSUM procedure as values of the variable _STDDEV_ in a LIMITS= data set.
NOWEIGHT Method for Subgroup Samples
This method is the default for cusum charts for subgrouped data. The estimate is
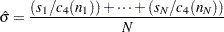 |
where 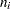 is the sample size of the
is the sample size of the 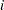 th subgroup, is the number of subgroups for which
th subgroup, is the number of subgroups for which 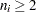 ,
,  is the sample standard deviation of the observations
is the sample standard deviation of the observations 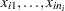 in the th subgroup.
in the th subgroup.
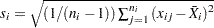 |
and
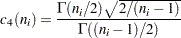 |
where 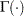 denotes the gamma function, and
denotes the gamma function, and 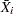 denotes the th subgroup mean. A subgroup standard deviation is included in the calculation only if . If the observations are normally distributed, then the expected value of is
denotes the th subgroup mean. A subgroup standard deviation is included in the calculation only if . If the observations are normally distributed, then the expected value of is
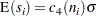 |
Thus, is the unweighted average of unbiased estimates of . This method is described in the ASTM Manual on Presentation of Data and Control Chart Analysis.
MVLUE Method for Subgroup Samples
If you specify SMETHOD=MVLUE, a minimum variance linear unbiased estimate (MVLUE) is computed, as introduced by Burr (1969, 1976). This estimate is a weighted average of unbiased estimates of of the form
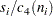 |
where
|
is the standard deviation of the |
|
is the unbiasing factor defined previously. |
|
is the |
|
is the number of subgroups for which |
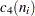
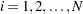 .
. The estimate is
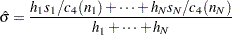 |
where 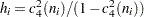 . A subgroup standard deviation is included in the calculation only if .
. A subgroup standard deviation is included in the calculation only if .
The MVLUE assigns greater weight to estimates of from subgroups with larger sample sizes and is intended for situations where the subgroup sample sizes vary. If the subgroup sample sizes are constant, the MVLUE reduces to the default estimate (NOWEIGHT).
RMSDF Method for Subgroup Samples
If you specify SMETHOD=RMSDF, a weighted root-mean-square estimate is computed:
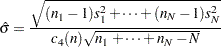 |
where
|
is the sample size of the |
|
is the number of subgroups for which |
|
is the sample standard deviation of the |
|
is the unbiasing factor defined previously. |
|
is equal to |

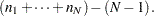
The weights in the root-mean-square expression are the degrees of freedom 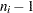 . A subgroup standard deviation is included in the calculation only if .
. A subgroup standard deviation is included in the calculation only if .
If the unknown standard deviation is constant across subgroups, the root-mean-square estimate is more efficient than the minimum variance linear unbiased estimate. However, as noted by Burr (1969), "the constancy of is the very thing under test," and if varies across subgroups, the root-mean-square estimate tends to be more inflated than the MVLUE.