| The RELIABILITY Procedure |
| MODEL Statement |
- MODEL (variable1 variable2) <=effect-list> </options> ;
You use the MODEL statement to fit regression models, where life is modeled as a function of explanatory variables.
You can use only one MODEL statement after a PROC RELIABILITY statement. If you specify more than one MODEL statement, only the last is used.
The MODEL statement does not produce any plots, but it enables you to analyze more complicated regression models than the ANALYZE, PROBPLOT, or RELATIONPLOT statement does. The probability distribution specified in the DISTRIBUTION statement is used in the analysis. The following are examples of MODEL statements:
model time = temp voltage; model life*censor(1) = voltage width;
See the section Analysis of Accelerated Life Test Data and the section Regression Modeling for examples that use the MODEL statement to fit regression models.
If your data are right censored, you must specify a censor-variable and, in parentheses, the values of the censor-variable that correspond to censored data values.
If your data contain any interval-censored or left-censored values, you must specify variable1 and variable2 in parentheses to provide the endpoints of the interval for each observation.
The independent variables in your regression model are specified in the effect-list. The effect-list is any combination of continuous variables, classification variables, and interaction effects.
See the section Regression Models for further information on specifying the independent variables.
The elements of the MODEL statement are described as follows.
- variable
is the dependent, or response, variable. The variable must be a numeric variable in the input data set.
- censor-variable(values)
indicates which observations in the input data set are right censored. You specify the values of censor-variable that represent censored observations by placing those values in parentheses after the variable name. If your data are not right censored, then you can omit the specification of a censor-variable; otherwise, censor-variable must be a numeric variable in the input data set.
- (variable1 variable2)
is another method of specifying the dependent variable in the regession model. You can use this syntax in a situation where uncensored, interval-censored, left-censored, and right-censored values occur in the same set of data. Table 12.26 shows how you use this syntax to specify different types of censoring by using combinations of missing and nonmissing values.
Table 12.26 Specifying Censored Values Variable1
Variable2
Type of Censoring
nonmissing
nonmissing
uncensored if variable1 = variable2
nonmissing
nonmissing
interval censored if variable1 < variable2
nonmissing
missing
right censored at variable1
missing
nonmissing
left censored at variable2
For example, if T1 and T2 represent time in hours in the input data set
OBS T1 T2 1 . 6 2 6 12 3 12 24 4 24 . 5 24 24
then the statement
model (t1 t2);
specifies a model in which observation 1 is left censored at 6 hours, observation 2 is interval censored in the interval (6, 12), observation 3 is interval censored in (12,24), observation 4 is right censored at 24 hours, and observation 5 is an uncensored lifetime of 24 hours.
- effect-list
is a list of variables in the input data set representing the values of the independent variables in the model for each observation, and combinations of variables representing interaction terms. If a variable in the effect-list is also listed in a CLASS statement, an indicator variable is generated for each level of the variable. An indicator variable for a particular level is equal to 1 for observations with that level, and equal to 0 for all other observations. This type of variable is called a classification variable. Classification variables can be either character or numeric. If a variable is not listed in a CLASS statement, it is assumed to be a continuous variable, and it must be numeric.
- options
control how the model is fit and what output is produced. All options are specified after a slash (/) in the MODEL statement. The "Summary of Options" section, which follows, lists all options by function.
Summary of Options
Option |
Option Description |
|---|---|
CONFIDENCE=number |
specifies the confidence coefficient for all confidence intervals. Specify a number between 0 and 1. The default value is 0.95. |
CONVERGE=number |
specifies the convergence criterion for maximum likelihood fit. See the section Maximum Likelihood Estimation for details. |
CONVH=number |
specifies the convergence criterion for the relative Hessian convergence criterion See the section Maximum Likelihood Estimation for details. |
CORRB |
requests parameter correlation matrix |
COVB |
requests parameter covariance matrix |
INITIAL=number list |
specifies initial values for regression parameters other than the location, or intercept term |
ITPRINT |
requests iteration history for maximum likelihood fit |
LRCL |
requests likelihood ratio confidence intervals for distribution parameters |
LOCATION=number <LINIT> |
specifies fixed or initial value of the location, or intercept parameter |
MAXIT=number |
specifies maximum number of iterations allowed for maximum likelihood fit |
OBSTATS |
requests a table containing the XBETA, SURV, SRESID, and ADJRESID statistics in Table 12.28. The table also contains the dependent and independent variables in the model. |
OBSTATS(statistics) |
requests a table containing the model variables and the statistics in the specified list of statistics. Available statistics are shown in Table 12.28. |
ORDER=DATA | FORMATTED | |
specifies sort order for values of the classification variables in the effect-list |
PSTABLE=number |
specifies stable parameterization. The number must be between zero and one. See the section Stable Parameters for further information. |
READOUT |
analyzes data in readout structure. The FREQ statement must be used to specify the number of units failing in each interval, and the NENTER statement must be used to specify the number of unfailed units entering each interval |
RELATION=ARRHENIUS | RELATION=(ARRHENIUS | |
specifies type of relationship between independent and dependent variables. In the first form, the transformation specified is applied to the first continuous independent variable in the model. In the second form, the transformations specified within parentheses are applied to the first two continuous independent variables in the model, in the order listed. See Table 12.58 for definitions of the transformations. |
SCALE=number <SCINIT> |
specifies fixed or initial value of scale parameter |
SHAPE=number <SHINIT> |
specifies fixed or initial value of shape parameter |
SINGULAR=number |
specifies singularity criterion for matrix inversion |
THRESHOLD=number |
specifies a fixed threshold parameter. See Table 12.49 for the distributions with a threshold parameter. |
Option |
Option Description |
|---|---|
CENSOR |
is an indicator variable equal to 1 if an observation is censored, and 0 otherwise |
QUANTILES | QUANTILE | |
specifies distribution quantiles for each number in number list for each observation. The numbers must be between 0 and 1. Estimated quantile standard errors, and upper and lower confidence limits are also tabulated. |
XBETA |
is the linear predictor |
SURVIVAL | SURV |
is the fitted survival function, evaluated at the value of the dependent variable |
RESID |
is the raw residual |
SRESID |
is the standardized residual |
GRESID |
is the modified Cox-Snell residual |
DRESID |
is the deviance residual |
ADJRESID |
is the adjusted standardized residuals. These are adjusted for right-censored observations by adding the median of the lifetime greater than the right-censored values to the residuals. |
RESIDADJ=number |
specifies adjustment to be added to Cox-Snell residual for right-censored data values. The default is log(2) = 0.693. |
RESIDALPHA | RALPHA=number |
specifies |
CONTROL=variable |
specifies a control variable in the input data set. If the value of the control variable is 1, the observation statistics are computed. If the value of the control variable is not equal to 1, the statistics are not computed for that observation. |
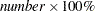 percentile residual lifetime used to adjust right-censored standardized residuals. The number must be between 0 and 1. The default value is 0.5, corresponding to the median.
percentile residual lifetime used to adjust right-censored standardized residuals. The number must be between 0 and 1. The default value is 0.5, corresponding to the median.Copyright © SAS Institute, Inc. All Rights Reserved.