The CORR Procedure
- Overview
- Getting Started
-
Syntax

-
DetailsPearson Product-Moment CorrelationSpearman Rank-Order CorrelationKendall’s Tau-b Correlation CoefficientHoeffding Dependence CoefficientPartial CorrelationFisher’s z TransformationPolychoric CorrelationPolyserial CorrelationCronbach’s Coefficient AlphaConfidence and Prediction EllipsesMissing ValuesIn-Database ComputationOutput TablesOutput Data SetsODS Table NamesODS Graphics
-
ExamplesComputing Four Measures of AssociationComputing Correlations between Two Sets of VariablesAnalysis Using Fisher’s z TransformationApplications of Fisher’s z TransformationComputing Polyserial CorrelationsComputing Cronbach’s Coefficient AlphaSaving Correlations in an Output Data SetCreating Scatter PlotsComputing Partial Correlations
- References
PROC CORR Statement
PROC CORR <options> ;
Table 2.1 summarizes the options available in the PROC CORR statement.
Table 2.1: Summary of PROC CORR Options
|
Option |
Description |
|---|---|
|
Data Sets |
|
|
Specifies the input data set |
|
|
Specifies the output data set with Hoeffding’s |
|
|
Specifies the output data set with Kendall correlation statistics |
|
|
Specifies the output data set with Pearson correlation statistics |
|
|
Specifies the output data set with Spearman correlation statistics |
|
|
Statistical Analysis |
|
|
Excludes observations with nonpositive weight values from the analysis |
|
|
Requests correlation statistics using Fisher’s |
|
|
Requests Hoeffding’s measure of dependence, |
|
|
Requests Kendall’s tau-b |
|
|
Excludes observations with missing analysis values from the analysis |
|
|
Requests Pearson product-moment correlation |
|
|
Requests polychoric correlation |
|
|
Requests polyserial correlation |
|
|
Requests Spearman rank-order correlation |
|
|
Pearson Correlation Statistics |
|
|
Computes Cronbach’s coefficient alpha |
|
|
Computes covariances |
|
|
Computes corrected sums of squares and crossproducts |
|
|
Computes correlation statistics based on Fisher’s |
|
|
Specifies the singularity criterion |
|
|
Computes sums of squares and crossproducts |
|
|
Specifies the divisor for variance calculations |
|
|
ODS Output Graphics |
|
|
Displays the scatter plot matrix |
|
|
Displays scatter plots for pairs of variables |
|
|
Printed Output |
|
|
Displays the specified number of ordered correlation coefficients |
|
|
Suppresses Pearson correlations |
|
|
Suppresses all printed output |
|
|
Suppresses |
|
|
Suppresses descriptive statistics |
|
|
Displays ordered correlation coefficients |
|
The following options can be used in the PROC CORR statement. They are listed in alphabetical order.
- ALPHA
-
calculates and prints Cronbach’s coefficient alpha. PROC CORR computes separate coefficients using raw and standardized values (scaling the variables to a unit variance of 1). For each VAR statement variable, PROC CORR computes the correlation between the variable and the total of the remaining variables. It also computes Cronbach’s coefficient alpha by using only the remaining variables.
If a WITH statement is specified, the ALPHA option is invalid. When you specify the ALPHA option, the Pearson correlations will also be displayed. If you specify the OUTP= option, the output data set also contains observations with Cronbach’s coefficient alpha. If you use the PARTIAL statement, PROC CORR calculates Cronbach’s coefficient alpha for partialled variables. See the section Partial Correlation for details.
- BEST=n
-
prints the
 highest correlation coefficients for each variable,
highest correlation coefficients for each variable, 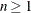 . Correlations are ordered from highest to lowest in absolute value. Otherwise, PROC CORR prints correlations in a rectangular
table, using the variable names as row and column labels.
. Correlations are ordered from highest to lowest in absolute value. Otherwise, PROC CORR prints correlations in a rectangular
table, using the variable names as row and column labels.
If you specify the HOEFFDING option, PROC CORR displays the
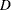 statistics in order from highest to lowest.
statistics in order from highest to lowest.
- COV
-
displays the variance and covariance matrix. When you specify the COV option, the Pearson correlations will also be displayed. If you specify the OUTP= option, the output data set also contains the covariance matrix with the corresponding _TYPE_ variable value 'COV.' If you use the PARTIAL statement, PROC CORR computes a partial covariance matrix.
- CSSCP
-
displays a table of the corrected sums of squares and crossproducts. When you specify the CSSCP option, the Pearson correlations will also be displayed. If you specify the OUTP= option, the output data set also contains a CSSCP matrix with the corresponding _TYPE_ variable value 'CSSCP.' If you use a PARTIAL statement, PROC CORR prints both an unpartial and a partial CSSCP matrix, and the output data set contains a partial CSSCP matrix.
- DATA=SAS-data-set
-
names the SAS data set to be analyzed by PROC CORR. By default, the procedure uses the most recently created SAS data set.
-
EXCLNPWGT
EXCLNPWGTS -
excludes observations with nonpositive weight values from the analysis. By default, PROC CORR treats observations with negative weights like those with zero weights and counts them in the total number of observations.
- FISHER <( fisher-options )>
-
requests confidence limits and
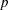 -values under a specified null hypothesis,
-values under a specified null hypothesis, 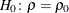 , for correlation coefficients by using Fisher’s
, for correlation coefficients by using Fisher’s  transformation. These correlations include the Pearson correlations and Spearman correlations.
transformation. These correlations include the Pearson correlations and Spearman correlations.
The following fisher-options are available:
-
ALPHA=

-
specifies the level of the confidence limits for the correlation,
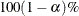 . The value of the ALPHA= option must be between 0 and 1, and the default is ALPHA=0.05.
. The value of the ALPHA= option must be between 0 and 1, and the default is ALPHA=0.05.
- BIASADJ=YES | NO
-
specifies whether or not the bias adjustment is used in constructing confidence limits. The BIASADJ=YES option also produces a new correlation estimate that uses the bias adjustment. By default, BIASADJ=YES.
-
RHO0=
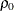
-
specifies the value
in the null hypothesis 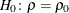 , where
, where 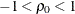 . By default, RHO0=0.
. By default, RHO0=0.
- TYPE=LOWER | UPPER | TWOSIDED
-
specifies the type of confidence limits. The TYPE=LOWER option requests a lower confidence limit from the lower alternative
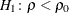 , the TYPE=UPPER option requests an upper confidence limit from the upper alternative
, the TYPE=UPPER option requests an upper confidence limit from the upper alternative 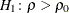 , and the default TYPE=TWOSIDED option requests two-sided confidence limits from the two-sided alternative
, and the default TYPE=TWOSIDED option requests two-sided confidence limits from the two-sided alternative 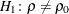 .
.
-
ALPHA=
- HOEFFDING
-
requests a table of Hoeffding’s
statistics. This statistic is 30 times larger than the usual definition and scales the range between  0.5 and 1 so that large positive values indicate dependence. The HOEFFDING option is invalid if a WEIGHT or PARTIAL statement
is used.
0.5 and 1 so that large positive values indicate dependence. The HOEFFDING option is invalid if a WEIGHT or PARTIAL statement
is used.
- KENDALL
-
requests a table of Kendall’s tau-b coefficients based on the number of concordant and discordant pairs of observations. Kendall’s tau-b ranges from
1 to 1.
The KENDALL option is invalid if a WEIGHT statement is used. If you use a PARTIAL statement, probability values for Kendall’s partial tau-b are not available.
- NOCORR
-
suppresses displaying of Pearson correlations. If you specify the OUTP= option, the data set type remains CORR. To change the data set type to COV, CSSCP, or SSCP, use the TYPE= data set option.
- NOMISS
-
excludes observations with missing values from the analysis. Otherwise, PROC CORR computes correlation statistics by using all of the nonmissing pairs of variables. Using the NOMISS option is computationally more efficient.
- NOPRINT
-
suppresses all displayed output, which also includes output produced with ODS Graphics. Use the NOPRINT option if you want to create an output data set only.
- NOPROB
-
suppresses displaying the probabilities associated with each correlation coefficient.
- NOSIMPLE
-
suppresses printing simple descriptive statistics for each variable. However, if you request an output data set, the output data set still contains simple descriptive statistics for the variables.
- OUTH=output-data-set
-
creates an output data set that contains Hoeffding’s
statistics. The contents of the output data set are similar to those of the OUTP= data set. When you specify the OUTH= option,
the Hoeffding’s statistics will be displayed.
- OUTK=output-data-set
-
creates an output data set that contains Kendall correlation statistics. The contents of the output data set are similar to those of the OUTP= data set. When you specify the OUTK= option, the Kendall correlation statistics will be displayed.
-
OUTP=output-data-set
OUT=output-data-set -
creates an output data set that contains Pearson correlation statistics. This data set also includes means, standard deviations, and the number of observations. The value of the _TYPE_ variable is 'CORR.' When you specify the OUTP= option, the Pearson correlations will also be displayed. If you specify the ALPHA option, the output data set also contains six observations with Cronbach’s coefficient alpha.
- OUTS=SAS-data-set
-
creates an output data set that contains Spearman correlation coefficients. The contents of the output data set are similar to those of the OUTP= data set. When you specify the OUTS= option, the Spearman correlation coefficients will be displayed.
- PEARSON
-
requests a table of Pearson product-moment correlations. The correlations range from
1 to 1. If you do not specify the HOEFFDING, KENDALL, SPEARMAN, POLYCHORIC, POLYSERIES, OUTH=, OUTK=, or OUTS= option, the
CORR procedure produces Pearson product-moment correlations by default. Otherwise, you must specify the PEARSON, ALPHA, COV,
CSSCP, SSCP, or OUT= option for Pearson correlations. Also, if a scatter plot or a scatter plot matrix is requested, the Pearson
correlations will be displayed.
-
PLOTS <( MAXPOINTS=NONE |
)> = plot-request
PLOTS <( MAXPOINTS=NONE |
)> = ( plot-request < …plot-request )
-
requests statistical graphics via the Output Delivery System (ODS).
ODS Graphics must be enabled before plots can be requested. For example:
ods graphics on; proc corr data=Fitness plots=matrix(histogram); run; ods graphics off;
For more information about enabling and disabling ODS Graphics, see the section “Enabling and Disabling ODS Graphics” in Chapter 21: Statistical Graphics Using ODS in SAS/STAT 12.1 User's Guide.
The global plot option MAXPOINTS= specifies that plots with elements that require processing more than
points be suppressed. The default is MAXPOINTS=5000. This limit is ignored if you specify MAXPOINTS=NONE. The plot request
options include the following:
When a scatter plot or a scatter plot matrix is requested, the Pearson correlations will also be displayed.
The available matrix-options are as follows:
- HIST | HISTOGRAM
-
displays histograms of variables in the VAR list (specified in the VAR statement) in the symmetric matrix plot.
- NVAR=ALL | n
-
specifies the maximum number of variables in the VAR list to be displayed in the matrix plot, where
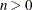 . The NVAR=ALL option uses all variables in the VAR list. By default, NVAR=5.
. The NVAR=ALL option uses all variables in the VAR list. By default, NVAR=5.
- NWITH=ALL | n
-
specifies the maximum number of variables in the WITH list (specified in the WITH statement) to be displayed in the matrix plot, where
. The NWITH=ALL option uses all variables in the WITH list. By default, NWITH=5.
If the resulting maximum number of variables in the VAR or WITH list is greater than 10, only the first 10 variables in the list are displayed in the scatter plot matrix.
The available scatter-options are as follows:
-
ALPHA=
-
specifies the
values for the confidence or prediction ellipses to be displayed in the scatter plots, where 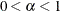 . For each value specified, a (
. For each value specified, a (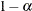 ) confidence or prediction ellipse is created. By default,
) confidence or prediction ellipse is created. By default, 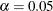 .
.
- ELLIPSE=PREDICTION | CONFIDENCE | NONE
-
requests prediction ellipses for new observations (ELLIPSE=PREDICTION), confidence ellipses for the mean (ELLIPSE=CONFIDENCE), or no ellipses (ELLIPSE=NONE) to be created in the scatter plots. By default, ELLIPSE=PREDICTION.
- NOINSET
-
suppresses the default inset of summary information for the scatter plot. The inset table contains the number of observations (Observations) and correlation.
- NVAR=ALL | n
-
specifies the maximum number of variables in the VAR list (specified in the VAR statement) to be displayed in the plots, where
. The NVAR=ALL option uses all variables in the VAR list. By default, NVAR=5.
- NWITH=ALL | n
-
specifies the maximum number of variables in the WITH list (specified in the WITH statement) to be displayed in the plots, where
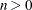 . The NWITH=ALL option uses all variables in the WITH list. By default, NWITH=5.
. The NWITH=ALL option uses all variables in the WITH list. By default, NWITH=5.
If the resulting maximum number of variables in the VAR or WITH list is greater than 10, only the first 10 variables in the list are displayed in the scatter plots.
- POLYCHORIC <( options )>
-
requests a table of polychoric correlation coefficients. A polychoric correlation measures the correlation between two unobserved, continuous variables that have a bivariate normal distribution. Information about each unobserved variable is obtained through an observed ordinal variable that is derived from the unobserved variable by classifying its values into a finite set of discrete, ordered values. If you specify a WEIGHT statement, the POLYCHORIC option is not applicable.
You can specify the following options for computing polychoric correlation:
- POLYSERIAL <( options )>
-
requests a table of polyserial correlation coefficients. A polyserial correlation measures the correlation between two continuous variables with a bivariate normal distribution, where one variable is observed and the other is unobserved. Information about the unobserved variable is obtained through an observed ordinal variable that is derived from the unobserved variable by classifying its values into a finite set of discrete, ordered values. If you specify a WEIGHT statement, the POLYSERIAL option is not applicable.
You can specify the following options for computing polyserial correlation:
- RANK
-
displays the ordered correlation coefficients for each variable. Correlations are ordered from highest to lowest in absolute value. If you specify the HOEFFDING option, the
statistics are displayed in order from highest to lowest.
- SINGULAR=p
-
specifies the criterion for determining the singularity of a variable if you use a PARTIAL statement. A variable is considered singular if its corresponding diagonal element after Cholesky decomposition has a value less than p times the original unpartialled value of that variable. By default, SINGULAR=1E
8. The range of p is between 0 and 1.
- SPEARMAN
-
requests a table of Spearman correlation coefficients based on the ranks of the variables. The correlations range from
1 to 1. If you specify a WEIGHT statement, the SPEARMAN option is invalid.
- SSCP
-
displays a table of the sums of squares and crossproducts. When you specify the SSCP option, the Pearson correlations are also displayed. If you specify the OUTP= option, the output data set contains a SSCP matrix and the corresponding _TYPE_ variable value is 'SSCP.' If you use a PARTIAL statement, the unpartial SSCP matrix is displayed, and the output data set does not contain an SSCP matrix.
- VARDEF=DF | N | WDF | WEIGHT | WGT
-
specifies the variance divisor in the calculation of variances and covariances. The default is VARDEF=DF.
Table 2.2 displays available values and associated divisors for the VARDEF= option, where n is the number of nonmissing observations, k is the number of variables specified in the PARTIAL statement, and
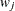 is the weight associated with the
is the weight associated with the 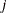 th nonmissing observation.
th nonmissing observation.
Table 2.2: Possible Values for the VARDEF= Option
Value
Description
Divisor
DF
Degrees of freedom
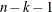
N
Number of observations

WDF
Sum of weights minus one
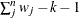
WEIGHT | WGT
Sum of weights