| The NLP Procedure |
Hessian and CRP Jacobian Scaling
The rows and columns of the Hessian and crossproduct Jacobian matrix
can be scaled when using the trust region, Newton-Raphson, double dogleg,
and Levenberg-Marquardt optimization techniques.
Each element ![]() ,
, ![]() is divided by the
scaling factor
is divided by the
scaling factor ![]() , where the scaling vector
, where the scaling vector
![]() is iteratively updated in a way
specified by the HESCAL=
is iteratively updated in a way
specified by the HESCAL=![]() option, as follows:
option, as follows:
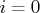
- No scaling is done (equivalent to
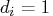 ).
).
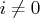
- First iteration and each restart iteration:
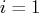
- refer to Moré (1978):
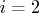
- refer to Dennis, Gay, and Welsch (1981):
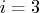
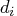 is reset in each iteration:
is reset in each iteration:
Copyright © 2008 by SAS Institute Inc., Cary, NC, USA. All rights reserved.