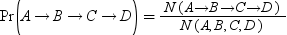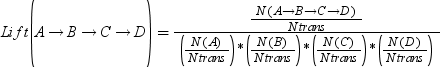IMSTAT Procedure (Analytics)
- Syntax
 Procedure SyntaxPROC IMSTAT (Analytics) StatementAGGREGATE StatementARM StatementASSESS StatementBOXPLOT StatementCLUSTER StatementCORR StatementCROSSTAB StatementDECISIONTREE StatementDISTINCT StatementFORECAST StatementFREQUENCY StatementGENMODEL StatementGLM StatementGROUPBY StatementHISTOGRAM StatementKDE StatementLOGISTIC StatementMDSUMMARY StatementOPTIMIZE StatementPERCENTILE StatementRANDOMWOODS StatementREGCORR StatementSUMMARY StatementTEXTPARSE StatementTOPK StatementQUIT Statement
Procedure SyntaxPROC IMSTAT (Analytics) StatementAGGREGATE StatementARM StatementASSESS StatementBOXPLOT StatementCLUSTER StatementCORR StatementCROSSTAB StatementDECISIONTREE StatementDISTINCT StatementFORECAST StatementFREQUENCY StatementGENMODEL StatementGLM StatementGROUPBY StatementHISTOGRAM StatementKDE StatementLOGISTIC StatementMDSUMMARY StatementOPTIMIZE StatementPERCENTILE StatementRANDOMWOODS StatementREGCORR StatementSUMMARY StatementTEXTPARSE StatementTOPK StatementQUIT Statement - Overview
- Examples Calculating Percentiles and QuartilesRetrieving Box ValuesRetrieving Box Plot Values with the NOUTLIERLIMIT= OptionRetrieving Distinct Value Counts and GroupingPerforming a Cluster AnalysisPerforming a Pairwise CorrelationCrosstabulation with Measures of Association and Chi-Square TestsTraining and Validating a Decision TreeStoring and Scoring a Decision TreePerforming a Multi-Dimensional SummaryFitting a Regression ModelForecasting and Automatic ModelingForecasting with Goal SeekingAggregating Time Series Data
ARM Statement
The ARM statement is used to perform associative rule mining (ARM). You can use it to derive frequent itemsets, perform association rule mining, and sequence mining.
Syntax
Required Arguments
item-variable
specifies the name of the variable in the active table that identifies items.
transaction-variable
specifies the name of the variable in the active table that identifies transactions.
Optional Argument
variable-list
specifies one or more numeric variables. If you do not specify this option, then all numeric variables in the table are used.
ARM Statement Options
AGGREGATE=aggregation-method
lists the aggregator for which the score of an itemset at each occurrence in a data set is aggregated into a final score of such itemset. If the WEIGHT= variable is not specified, then the aggregator specification is ignored.
| MAX | maximum value |
| MEAN | arithmetic mean |
| MIN | minimum value |
| SUM | sum of the nonmissing values |
| Alias | AGG= |
| Default | SUM |
| Interaction | You must specify the WEIGHT= option to use this option. |
FREQ=variable
specifies the numeric frequency variable to use for computing the score of each frequent itemset along with WEIGHT= option. When the FREQ= variable is not specified, the score of a frequent itemset equates the value of the WEIGHT= variable scaled by 1. Negative values for the specified variable are considered missing.
ITEMAGG=aggregation-method
lists the aggregator for which the values of the WEIGHT= variable, and optionally the FREQ= variable, are rolled up into the score of an itemset at each occurrence in the data set, provided that a WEIGHT= variable is specified. If the WEIGHT= variable is not specified, then the aggregator specification is ignored. The aggregation methods are identical to the list in the AGGREGATE= option.
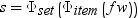
ITEMFMT=("format-specification")
ITEMSTBL
specifies to save the derived frequent itemsets in a temporary table. By default, the frequent itemsets are not saved.
MAXITEMS=n
specifies the maximal number of items to allow in a frequent itemset. The value must be greater than or equal to 1. If an invalid value is specified, then it is replaced with 1, the default value.
| Default | 1 |
MINITEMS=n
specifies the minimal number of items to allow in a frequent itemset. The value must be greater than or equal to zero. If an invalid value is specified, then it is replaced with 0, the default value.
| Default | 0 |
NOMISSING
specifies that missing values of the ITEM= and TRAN= variables are excluded from analysis. By default, missing values of the ITEM= variable are considered a separate item. Missing values of the TRAN= variable are considered a separate transaction.
| Alias | NOMISS |
PARTITION <=partition-key>
specifies to use partitioning variables. When only PARTITION is specified and the table is partitioned first by the TRAN= variable, and the TRANFMT= option is specified, the associative rule mining is performed separately for each value of the partition key. If a value for partition-key is specified, then the associative rule mining is performed on that partition only.
RELSUPPORT
specifies that the values for LOWER= and UPPER= in the SUPPORT option are relative to the most frequent itemset. For example, if 500 is the support of the most frequent itemset, then specifying RELSUPPORT SUPPORT(LOWER=0.1 UPPER=0.5) means the minimum and the maximum supports for the analysis are 50 and 250, respectively. When using this option, the values for LOWER= and UPPER= must be between 0 and 1. Otherwise, they are set to the default values 0.05 and 1.0, respectively.
RULES(<suboptions>)
specifies the requirements for how association rules are generated from frequent itemsets. The following suboptions are available:
AGGREGATE=aggregation-method
lists the aggregator for which the score of a rule at each occurrence in a data set is aggregated into a final score of such rule. If the WEIGHT= variable is not specified, then the aggregator specification is ignored.
| MAX | maximum value |
| MEAN | arithmetic mean |
| MIN | minimum value |
| SUM | sum of the nonmissing values |
| Alias | AGG= |
| Default | SUM |
| Interaction | You must specify the WEIGHT= option to use this option. |
CONFIDENCE(<LOWER=lower-value> <UPPER=upper-value>)
specifies the minimal and maximal confidence values of the association rules have to fulfill. The default value for LOWER= is 0.5.
| Range | 0 to 1 |
FREQ=variable-name
specifies the numeric frequency variable to use for computing the score of each association rule along with ORDER= option. When a FREQ= variable is not specified, the score of an association rule equates the value of the ORDER= variable scaled by 1. Negative values for the specified variable are considered missing.
ITEMAGG=aggregation-method
lists the aggregator for which the values of the WEIGHT= variable, and optionally the FREQ= variable, are rolled up into the score of a rule at each occurrence in the data set, provided that a WEIGHT= variable is specified. If you do not specify a WEIGHT= variable, then the aggregator specification is ignored. The aggregation methods are identical to the list in the AGGREGATE= option.
NUMLHS(<LOWER=lower-value> <UPPER=upper-value>)
specifies the minimum and maximum number of items in the left-hand side (LHS) of a rule to allow. If you specify UPPER= < LOWER=, the server swaps the values.
NUMRHS(<LOWER=lower-value> <UPPER=upper-value>)
specifies the minimum and maximum number of items in the right-hand side (RHS) of a rule to allow. If you specify UPPER= < LOWER=, the server swaps the values.
SCORE(<LOWER=lower-value> <UPPER=upper-value>)
specifies the minimum and maximum scores of the association rules that are derived. If you specify UPPER= < LOWER=, the server swaps the values. If you specify the same value for LOWER= and UPPER=, the server adds ε (0.1110223024625157e-12) to value and uses the result for UPPER=.
WEIGHT=variable-name
specifies the numeric weight variable to use for computing the score of each association rule, along with FREQ= variable. If you do not specify a WEIGHT= variable, then the AGGREGATE=, FREQ=, and ITEMAGG= options are ignored.
SAVE=table-name
saves the result table so that you can use it in other IMSTAT procedure statements like STORE, REPLAY, and FREE. The value for table-name must be unique within the scope of the procedure execution. The name of a table that has been freed with the FREE statement can be used again in subsequent SAVE= options.
SCORE(<LOWER=lower-value> <UPPER=upper-value>)
specifies the minimum and maximum scores of the frequent itemsets that are derived. If you specify UPPER= < LOWER=, the server swaps the values. If you specify the same value for LOWER= and UPPER=, the server adds ε (0.1110223024625157e-12) to value and uses the result for UPPER=.
SEQUENCES(TIME=t <sub-options>)
specifies the requirements for how sequences are generated from the original table. The sequences do not necessarily depend on previously generated frequent itemsets. You can specify the following sub-options in SEQUENCES option:
ADJACENT
specifies that any two events of a sequence must be adjacent to each other in time in a transaction.
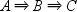 and the second is
and the second is 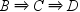 . The transaction does not support sequence
. The transaction does not support sequence 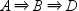 because events B and D do not happen consecutively
in this transaction. By default, ADJACENT option is not enabled so
that the transaction would support the third sequence, , when the chain length is 3.
because events B and D do not happen consecutively
in this transaction. By default, ADJACENT option is not enabled so
that the transaction would support the third sequence, , when the chain length is 3.
AGGREGATE=aggregation-method
lists the aggregator for which the score of a sequence at each occurrence in a data set is aggregated into a final score of such sequence. If the WEIGHT= variable is not specified, then the aggregator specification is ignored.
| MAX | maximum value |
| MEAN | arithmetic mean |
| MIN | minimum value |
| SUM | sum of the nonmissing values |
| Alias | AGG= |
| Default | SUM |
| Interaction | You must specify the WEIGHT= option to use this option. |
FREQ=variable-name
specifies the numeric frequency variable to use for computing the score of each sequence along with WEIGHT= option. When a FREQ= variable is not specified, the score of a sequence equates the value of the WEIGHT= variable scaled by 1. Negative values for the specified variable are considered missing.
INCLUDEMISSTIME
indicates that records with a missing value for the TIME= variable are considered for sequence analysis. If this option is specified, then the missing value for the TIME= variable is treated as the smallest value in a sequence.
ITEMAGG=aggregation-method
lists the aggregator for which the values of the WEIGHT= variable, and optionally the FREQ= variable, are rolled up into the score of a rule at each occurrence in the data set, provided that a WEIGHT= variable is specified. If the WEIGHT= variable is not specified, then the aggregator specification is ignored. The aggregation methods are identical to the list in the AGGREGATE= option.
ITEMSETFILTER=SINGLETONS | ALLITEMS | NONE
specifies how the sequences are filtered by frequent itemsets. The SINGLETONS setting means that each item of any sequence has to be a frequent singleton. The ALLITEMS setting means the set of all distinct items of any sequence have to be a frequent itemset. The NONE setting indicates that sequences are not influenced by what frequent itemsets are derived.
proc imstat data=example.assocs;
arm item=Product tran=Customer / maxItems=6 support(lower=150) itemsTbl
sequs(time=Time minItems=4 maxItems=6 minWindow=0
support(lower=110 upper=140) filter=none);
| Alias | FILTER= |
| Default | SINGLETONS |
LASRRULE=table-name
specifies an in-memory table that contains trained association rules. The rules are used to score the current active transaction table.
LASRSEQU=table-name
specifies an in-memory table that contains trained sequences. The sequences are used to score the current active transaction table.
MAXITEMS=n
specifies the maximal number of items to allow in any sequence. The value must be greater than or equal to 1. If an invalid value is specified, then it is replaced with 1, the default value.
MAXDURATION=t
specifies the maximum duration to allow between the onset time of the first item and the time of the last item in a sequence. If the difference is greater than t, then the sequence is excluded from the result set. The value must be greater than or equal to zero.
MAXWINDOW=t
specifies the maximum difference to allow between the onset of any two adjacent items in a sequence. If the difference is greater than t, then the two items cannot be part of the same sequence. The value must be greater than or equal to zero.
MINDURATION=t
specifies the minimum difference to allow between the onset time of the last item and the first item in a sequence. If the difference is less than t, then the sequence is excluded from the result set. The value must be greater than or equal to zero. If you specify a value for MAXDURATION= that is less than MINDURATION=, the server swaps the values.
MINITEMS=n
specifies the minimal number of items to allow in a sequence. The value must be greater than or equal to 1. If an invalid value is specified, then it is replaced with 1, the default value.
| Default | 1 |
MINWINDOW=t
specifies the minimum difference to allow between the onset of any two adjacent items in a sequence. If the difference is less than or equal to t, then the two items are treated as happening at the same time. The value must be greater than or equal to zero.
NODUP
specifies that duplicated items within a sequence are not allowed.
NOMERGE
specifies that a transaction
supports only one sequence with the same number of events in that
transaction. In the transaction table
that is shown in the ADJACENT option, the transaction supports only one sequence, 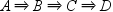 . By default, the NOMERGE option
is not enabled.
. By default, the NOMERGE option
is not enabled.
| Interaction | Specifying this option implies the ADJACENT option. |
SCORE(<LOWER=lower-value> <UPPER=upper-value>)
specifies the minimum and maximum scores of the sequences that are derived. If you specify UPPER= < LOWER=, the server swaps the values. If you specify the same value for LOWER= and UPPER=, the server adds ε (0.1110223024625157e-12) to the value and uses the result for UPPER=.
SUPPORT(<LOWER=lower-value> <UPPER=upper-value>)
specifies the minimum and maximum support of one sequence allowed in the analysis. By default, LOWER=1 and UPPER= is not set. Valid values for LOWER= and UPPER= are integers greater than 0. If you specify an invalid value for LOWER= or UPPER=, the server sets LOWER=1. The value for LOWER= must be less than or equal to the UPPER= value. If you specify UPPER= < LOWER=, the server swaps the values. Note that
| Default | LOWER=1 |
| Note | This option does not overwrite the SUPPORT option that is specified for deriving frequent itemsets. |
TIME=t
specifies the numeric variable to use for sorting the items in a sequence. This option is required for sequence analysis.
TIMEAGG=aggregation-method
specifies how to aggregate the time values when two adjacent events are the same in a sequence.
| MAX | maximum value |
| MEAN | arithmetic mean |
| MIN | minimum value |
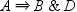
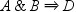
WEIGHT=variable-name
specifies the numeric weight variable to use for computing the score of each sequence, along with FREQ= variable. If you do not specify a WEIGHT= variable, then the AGGREGATE=, FREQ=, and ITEMAGG= options are ignored.
WINDOWAGG=aggregation-method
is used with the MINWINDOW= and MAXWINDOW= options. It lists the aggregator for which the values of the TIME= variable to update the anchor time. The default value is MEAN.
| MAX | maximum value |
| MEAN | arithmetic mean |
| MIN | minimum value |
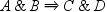
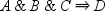
SEQUSTBL
specifies to save the derived sequences from frequent itemsets to a temporary table. By default, the ARM statement does not save sequences.
| Example | Sequences Table |
SUPPORT(<LOWER=lower-value> <UPPER=upper-value>)
specifies the minimum and maximum frequencies to allow for derived frequent itemsets. If RELSUPPORT is not specified, then LOWER= and UPPER= are the minimum and maximum frequencies of frequent items that appeared in the transactions. If RELSUPPORT is specified, then specify the two values as the ratios for the minimum and maximum frequencies of frequent itemsets to the frequency of the most frequent itemset.
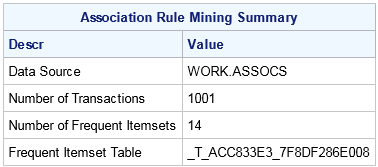
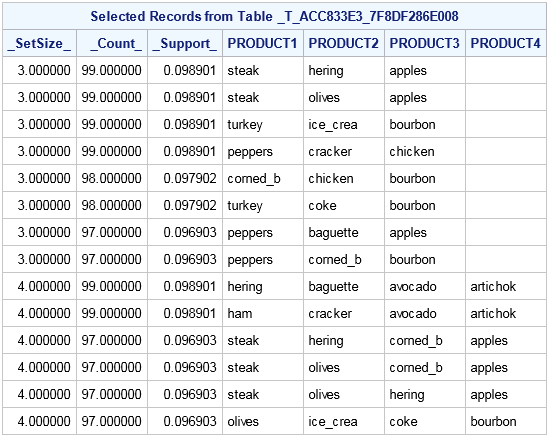
proc imstat data=example.assocs;
arm item=Product tran=Customer / minItems=3 maxItems=4
support(lower=97 upper100) itemsTbl;
run;
table example.&_tempARMItems_;
fetch / orderby=(_SetSize_ _Count) desc=_Count_;
run;
TEMPEXPRESS="SAS-expressions"
TEMPEXPRESS=file-reference
specifies either a quoted string that contains the SAS expression that defines the temporary variables or a file reference to an external file with the SAS statements.
| Alias | TE= |
TEMPNAMES=variable-name
TEMPNAMES=(variable-list)
specifies the list of temporary variables for the request. Each temporary variable must be defined through SAS statements that you supply with the TEMPEXPRESS= option.
| Alias | TN= |
TRANFMT=("format-specification")
WEIGHT=variable
specifies the numeric weight variable to use for computing the score of each frequent itemset, along with FREQ= variable. If you do not specify a WEIGHT= variable, then the AGGREGATE=, FREQ=, and ITEMAGG= options are ignored.
Details
Overview
Frequent Itemsets Table
data example.aggdata;
input customer product $ time price amount product_id;
datalines;
1 e 0 2.49 2 1
1 t 1 2999.00 1 2
1 e 2 2.49 2 1
1 t 3 499.00 1 2
1 e 4 3.49 3 1
1 t 5 199.00 1 2
2 t 0 199.00 1 2
2 e 1 3.49 2 1
2 h 2 50.00 1 3
2 e 3 3.49 1 1
2 t 4 499.00 1 2
2 e 5 3.49 1 1
;
run;
proc imstat data=example.aggdata;
arm item=product tran=customer / maxitems=3 freq=amount
weight=price itemagg=SUM agg=MIN itemstbl;
run;
table example.&_tempARMItems_;
fetch / orderby=(_SetSize_);
run;
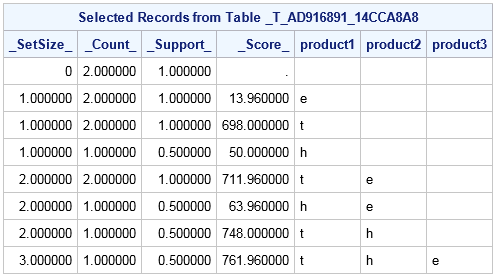
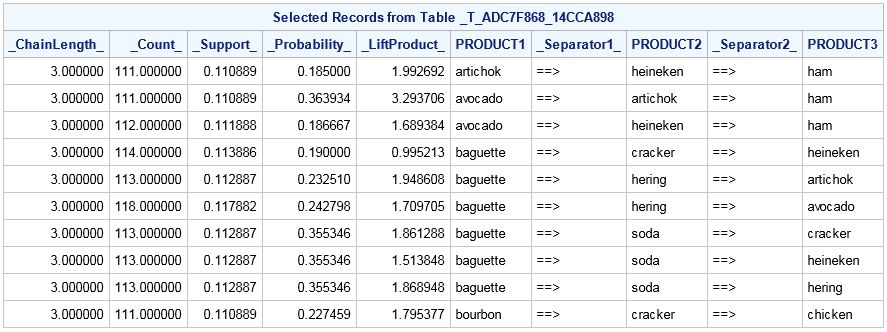
Association Rules Table
proc imstat data=example.assocs;
arm item=Product tran=Customer / minItems=3 maxItems=4 itemsTbl
support(LOWER=125 UPPER=130) weight=TIME
rules(confidence(LOWER=0.8) score(LOWER=1) weight=TIME) rulesTbl;
run;
table example.&_tempARMRules_;
fetch _SetSize_ -- _Rule_ / to=10;
run;
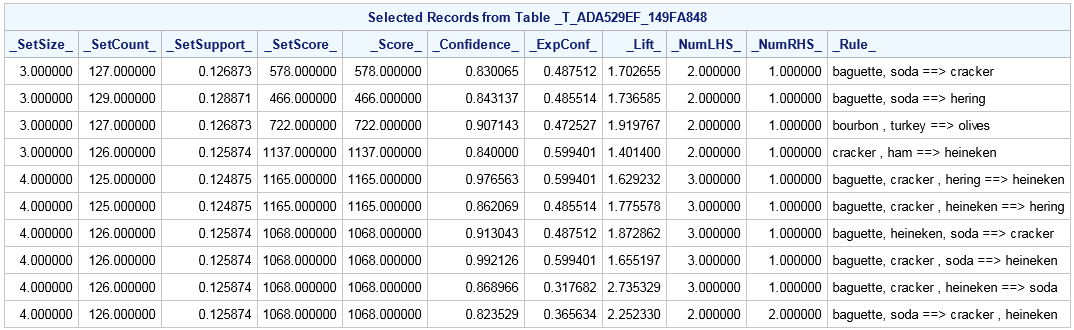
Sequences Table
proc imstat data=example.assocs;
arm item=Product tran=Customer / maxItems=3
sequences(time=time minItems=3 maxItems=3 support(lower=110 upper=120))
sequstbl;
run;
table example.&_tempARMSequs_;
fetch / to=10;
run;