The SEVERITY Procedure
- Overview
-
Getting Started

-
Syntax
-
Details
Predefined Distributions Censoring and Truncation Parameter Estimation Method Parameter Initialization Estimating Regression Effects Empirical Distribution Function Estimation Methods Statistics of Fit Defining a Distribution Model with the FCMP Procedure Predefined Utility Functions Custom Objective Functions Input Data Sets Output Data Sets Displayed Output ODS Graphics
-
Examples
Defining a Model for Gaussian Distribution Defining a Model for Gaussian Distribution with a Scale Parameter Defining a Model for Mixed-Tail Distributions Estimating Parameters Using Cramér-von Mises Estimator Fitting a Scaled Tweedie Model with Regressors Fitting Distributions to Interval-Censored Data
- References
| Output Data Sets |
PROC SEVERITY writes OUTCDF=, OUTEST=, OUTMODELINFO=, and OUTSTAT= data sets when requested with respective options. The data sets and their contents are described in the following sections.
OUTCDF= Data Set
The OUTCDF= data set records the estimates of the cumulative distribution function (CDF) of each of the specified model distributions and an estimate of the empirical distribution function (EDF).
If BY variables are specified, then the data are organized in BY groups and the data set contains variables specified in the BY statement. In addition, it contains the following variables:
- <response variable>
value of the response variable. The values are sorted. If there are multiple BY groups, the values are sorted within each BY group.- _OBSNUM_
observation number in the DATA= data set.
- _EDF_
estimate of the empirical distribution function (EDF). This estimate is computed by using the EMPIRICALCDF= option specified in the PROC SEVERITY statement.
- <distribution1>_CDF ... <distribution
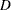 >_CDF
>_CDF -
estimate of the cumulative distribution function (CDF) for each of the candidate distributions, computed by using the final parameter estimates for that distribution. This value is missing if parameter estimation process does not converge for the given distribution. If regressor variables are specified, then the reported estimates are from a mixture distribution. See the section CDF and PDF Estimates with Regression Effects for details.
If truncation is specified, then the data set contains the following additional variables:
- <distribution1>_COND_CDF ... <distribution>_COND_CDF
estimate of the conditional CDF for each of the candidate distributions, computed by using the final parameter estimates for that distribution. This value is missing if parameter estimation process does not converge for the distribution. The conditional estimates are computed using the method described in the section Truncation and Conditional CDF Estimates.
OUTEST= Data Set
The OUTEST= data set records the estimates of the model parameters. It also contains estimates of their standard errors and optionally, their covariance structure. If BY variables are specified, then the data are organized in BY groups and the data set contains variables specified in the BY statement.
If the COVOUT option is not specified, then the data set contains the following variables:
- _MODEL_
identifying name of the distribution model. The observation contains information about this distribution.
- _TYPE_
-
type of the estimates reported in this observation. It can take one of the following two values:
- EST
point estimates of model parameters
- STDERR
standard error estimates of model parameters
- _STATUS_
status of the reported estimates. The possible values are listed in the section _STATUS_ Variable Values.
- <Parameter 1> ...<Parameter M>
-
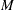 variables, named after the parameters of all candidate distributions, containing estimates of the respective parameters. is the cardinality of the union of parameter name sets from all candidate distributions. In an observation, estimates are populated only for parameters that correspond to the distribution specified by the _MODEL_ variable. If _TYPE_ is EST, then the estimates are missing if the model does not converge. If _TYPE_ is STDERR, then the estimates are missing if covariance estimates cannot be obtained.
variables, named after the parameters of all candidate distributions, containing estimates of the respective parameters. is the cardinality of the union of parameter name sets from all candidate distributions. In an observation, estimates are populated only for parameters that correspond to the distribution specified by the _MODEL_ variable. If _TYPE_ is EST, then the estimates are missing if the model does not converge. If _TYPE_ is STDERR, then the estimates are missing if covariance estimates cannot be obtained. If regressors are specified, then the estimate reported for the first parameter of each distribution is the estimate of the base value of the scale or log-transformed scale parameter. See the section Estimating Regression Effects for details.
- <Regressor 1> ...<Regressor K>
If regressors are specified in the SCALEMODEL statement, then the OUTEST= data set contains variables that are named for each regressor. The variables contain estimates for their respective regression coefficients. If a regressor is deemed to be linearly dependent on other regressors for a given BY group, then a warning message is printed to the SAS log and a special missing value of .R is written in the respective variable. If _TYPE_ is EST, then the estimates are missing if the model does not converge. If _TYPE_ is STDERR, then the estimates are missing if covariance estimates cannot be obtained.
regressors are specified in the SCALEMODEL statement, then the OUTEST= data set contains variables that are named for each regressor. The variables contain estimates for their respective regression coefficients. If a regressor is deemed to be linearly dependent on other regressors for a given BY group, then a warning message is printed to the SAS log and a special missing value of .R is written in the respective variable. If _TYPE_ is EST, then the estimates are missing if the model does not converge. If _TYPE_ is STDERR, then the estimates are missing if covariance estimates cannot be obtained.
If the COVOUT option is specified, then the OUTEST= data set contains additional observations that contain the estimates of the covariance structure. Given the symmetric nature of the covariance structure, only the lower triangular portion is reported. In addition to the variables listed and described previously, the data set contains the following variables that are either new or have a modified description:
- _TYPE_
type of the estimates reported in this observation. For observations that contain rows of the covariance structure, the value is COV.
- _STATUS_
status of the reported estimates. For observations that contain rows of the covariance structure, the status is 0 if covariance estimation was successful. If estimation fails, the status is 1 and a single observation is reported with _TYPE_=COV and missing values for all the parameter variables.
- _NAME_
Name of the parameter for the row of covariance matrix reported in the current observation.
OUTMODELINFO= Data Set
The OUTMODELINFO= data set records the information about each specified distribution. If BY variables are specified, then the data are organized in BY groups and the data set contains variables specified in the BY statement. In addition, it contains the following variables:
- _MODEL_
identifying name of the distribution model. The observation contains information about this distribution.
- _DESCRIPTION_
descriptive name of the model. This has a nonmissing value only if the DESCRIPTION function has been defined for this model.
- _PARMNAME
 ... _PARMNAME
... _PARMNAME
- variables that contain names of parameters of the distribution model, where is the maximum number of parameters across all the specified distribution models. For a given distribution with
 parameters, values of variables _PARMNAME
parameters, values of variables _PARMNAME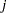 (
( ) are missing.
) are missing.
OUTSTAT= Data Set
The OUTSTAT= data set records statistics of fit and model selection information. If BY variables are specified, then the data are organized in BY groups and the data set contains variables specified in the BY statement. The data set contains the following variables:
- _MODEL_
identifying name of the distribution model. The observation contains information about this distribution.
- _NMODELPARM_
number of parameters in the distribution.
- _NESTPARM_
number of estimated parameters. This includes the regression parameters, if any regressors are specified.
- _NOBS_
number of nonmissing observations used for parameter estimation.
- _STATUS_
status of the parameter estimation process for this model. The possible values are listed in the section _STATUS_ Variable Values.
- _SELECTED_
indicator of the best distribution model. If the value is 1, then this model is the best model for the current BY group according to the specified model selection criterion. This value is missing if parameter estimation process does not converge for this model.
- Neg2LogLike
value of the log likelihood, multiplied by –2, that is attained at the end of the parameter estimation process. This value is missing if parameter estimation process does not converge for this model.
- AIC
value of the Akaike’s information criterion (AIC) that is attained at the end of the parameter estimation process. This value is missing if parameter estimation process does not converge for this model.
- AICC
value of the corrected Akaike’s information criterion (AICC) that is attained at the end of the parameter estimation process. This value is missing if parameter estimation process does not converge for this model.
- BIC
value of the Schwarz Bayesian information criterion (BIC) that is attained at the end of the parameter estimation process. This value is missing if parameter estimation process does not converge for this model.
- KS
value of the Kolmogorov-Smirnov (KS) statistic that is attained at the end of the parameter estimation process. This value is missing if parameter estimation process does not converge for this model.
- AD
value of the Anderson-Darling (AD) statistic that is attained at the end of the parameter estimation process. This value is missing if parameter estimation process does not converge for this model.
- CVM
value of the Cra
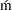 er-von Mises (CvM) statistic that is attained at the end of the parameter estimation process. This value is missing if parameter estimation process does not converge for this model.
er-von Mises (CvM) statistic that is attained at the end of the parameter estimation process. This value is missing if parameter estimation process does not converge for this model.
_STATUS_ Variable Values
The _STATUS_ variable in the OUTEST= and OUTSTAT= data sets contains a value that indicates the status of the parameter estimation process for the respective distribution model. The variable can take the following values in the OUTEST= data set for _TYPE_=EST observations and in the OUTSTAT= data set:
- 0
The parameter estimation process converged for this model.
- 301
The parameter estimation process might not have converged for this model because there is no improvement in the objective function value. This might indicate that the initial values of the parameters are optimal, or you can try different convergence criteria in the NLOPTIONS statement.
- 302
The parameter estimation process might not have converged for this model because the number of iterations exceeded the maximum allowed value. You can try setting a larger value for the MAXITER= options in the NLOPTIONS statement.
- 303
The parameter estimation process might not have converged for this model because the number of objective function evaluations exceeded the maximum allowed value. You can try setting a larger value for the MAXFUNC= options in the NLOPTIONS statement.
- 304
The parameter estimation process might not have converged for this model because the time taken by the process exceeded the maximum allowed value. You can try setting a larger value for the MAXTIME= option in the NLOPTIONS statement.
- 400
The parameter estimation process did not converge for this model.
The _STATUS_ variable can take the following values in the OUTEST= data set for _TYPE_=STDERR and _TYPE_=COV observations:
- 0
The covariance and standard error estimates are available and valid.
- 1
The covariance and standard error estimates are not available, because the process of computing covariance estimates failed.