The SEVERITY Procedure
- Overview
-
Getting Started

-
Syntax
-
Details
Predefined Distributions Censoring and Truncation Parameter Estimation Method Parameter Initialization Estimating Regression Effects Empirical Distribution Function Estimation Methods Statistics of Fit Defining a Distribution Model with the FCMP Procedure Predefined Utility Functions Custom Objective Functions Input Data Sets Output Data Sets Displayed Output ODS Graphics
-
Examples
Defining a Model for Gaussian Distribution Defining a Model for Gaussian Distribution with a Scale Parameter Defining a Model for Mixed-Tail Distributions Estimating Parameters Using Cramér-von Mises Estimator Fitting a Scaled Tweedie Model with Regressors Fitting Distributions to Interval-Censored Data
- References
| PROC SEVERITY Statement |
You can specify two types of options in the PROC SEVERITY statement. One set of options controls input and output. The other set of options controls the model estimation and selection process.
- COVOUT
specifies that the OUTEST= data set contain the estimate of the covariance structure of the parameters. This option has no effect if the OUTEST= option is not specified. Details of how the covariance is reported in OUTEST= data set are provided in the section OUTEST= Data Set.
- DATA=SAS-data-set
names the input data set. If the DATA= option is not specified, then the most recently created SAS data set is used.
- INEST=SAS-data-set
names the input data set that contains the initial values of the parameter estimates to start the optimization process. The initial values specified in the INIT= option in the DIST statement take precedence over any initial values specified in this data set. Details of the variables in this data set are provided in the section INEST= Data Set.
- NOPRINT
turns off all displayed and graphical output. If specified, any value specified for the PRINT= and PLOTS= options is ignored.
- OUTCDF=SAS-data-set
names the output data set to contain estimates of the cumulative distribution function (CDF) value at each of the observations. The information is output for each specified model whose parameter estimation process converges. The data set also contains the estimates of the empirical distribution function (EDF). Details of the variables in this data set are provided in the section OUTCDF= Data Set.
- OUTEST=SAS-data-set
names the output data set to contain estimates of the parameter values and their standard errors for each model whose parameter estimation process converges. Details of the variables in this data set are provided in the section OUTEST= Data Set.
- OUTMODELINFO=SAS-data-set
names the output data set to contain the status of each fitted model. The status information includes the convergence status of the optimization process that is used to estimate the parameters, the status of estimating the covariance matrix, and whether a model is the best according to the specified selection criterion. Details of the variables in this data set are provided in the section OUTMODELINFO= Data Set.
- OUTSTAT=SAS-data-set
names the output data set to contain the values of statistics of fit for each model whose parameter estimation process converges. Details of the variables in this data set are provided in the section OUTSTAT= Data Set.
- PLOTS <(global-plot-options)> <=plot-request-option>
- PLOTS <(global-plot-options)> <=(plot-request-options ...)>
-
specifies the desired graphical output. The global-plot-options and plot-request-options are separated by spaces.
The following global-plot-options are available:
- HISTOGRAM
plots the histogram of the response variable on the PDF plots.
- KERNEL
plots the kernel estimate of the probability density of the response variable on the PDF plots.
- MARKCENSORED
marks right-censored observations, if any, in the PDF and CDF plots. This option has no effect if right-censoring is not specified in the LOSS statement or if both right-censoring and left-censoring are specified.
- MARKTRUNCATED
marks left-truncated observations, if any, in the PDF and CDF plots. This option has no effect if left-truncation is not specified in the LOSS statement. This option does not mark observations that are right-truncated but not left-truncated.
- ONLY
turns off the default graphical output and prepares only the requested plots.
The following plot-request-options are available:
- ALL
displays all the graphical output.
- CDF
prepares a plot that compares the cumulative distribution function (CDF) estimates of all the candidate distribution models and the empirical distribution function (EDF) estimate. The plot does not contain CDF estimates for models whose parameter estimation process does not converge.
- CDFPERDIST
prepares a plot of the CDF estimates of each candidate distribution model. A plot is not prepared for models whose parameter estimation process does not converge.
- NONE
displays none of the graphical output. If specified, this option overrides all the other plot request options. The default graphical output is also suppressed.
prepares a plot that compares the probability density function (PDF) estimates of all the candidate distribution models. The plot does not contain PDF estimates for models whose parameter estimation process does not converge.
- PDFPERDIST
prepares a plot of the PDF estimates of each candidate distribution model. A plot is not prepared for models whose parameter estimation process does not converge.
- PP
prepares the probability-probability plot (known as the P-P plot) that compares the CDF estimate of each candidate distribution model against the empirical distribution function (EDF). The data shown in this plot are used for computing the EDF-based statistics of fit.
If the PLOTS= option is not specified or the ONLY global-plot-option is not specified, then the default graphical output is equivalent to specifying PLOTS=(CDF PDF).
- PRINT <(global-display-option)> <=display-option>
- PRINT <(global-display-option)> <=(display-options ...)>
-
specifies the desired displayed output. The display-options are separated by spaces.
The following global-display-option is available:
- ONLY
turns off the default displayed output and displays only the requested output.
The following display-options are available:
- ALL
displays all the output.
- ALLFITSTATS
displays the comparison of all the statistics of fit for all the models in one table. The table does not include the models whose parameter estimation process does not converge.
- CONVSTATUS
displays the convergence status of the parameter estimation process.
- DESCSTATS
displays the descriptive statistics for the response variable and the regressor variables, if they are specified.
- ESTIMATES | PARMEST
displays the final estimates of parameters. The estimates are not displayed for models whose parameter estimation process does not converge.
- INITIALVALUES
displays the initial values and bounds used for estimating each model.
- NLOHISTORY
displays the iteration history of the nonlinear optimization process used for estimating the parameters.
- NLOSUMMARY
displays the summary of the nonlinear optimization process used for estimating the parameters.
- NONE
displays none of the output. If specified, this option overrides all the other display options. The default displayed output is also suppressed.
- SELECTION | SELECT
displays the model selection table.
- STATISTICS | FITSTATS
displays the statistics of fit for each model. The statistics of fit are not displayed for models whose parameter estimation process does not converge.
If the PRINT= option is not specified or the ONLY global-display-option is not specified, then the default displayed output is equivalent to specifying PRINT=(SELECTION CONVSTATUS NLOSUMMARY STATISTICS ESTIMATES).
- VARDEF=option
- specifies the denominator to use for computing the covariance estimates. You can specify one of the following values for option:
- DF
specifies that the number of nonmissing observations minus the model degrees of freedom (number of parameters) be used.
- N
specifies that the number of nonmissing observations be used.
- VERBOSE=verbosity-level
specifies the amount of messages printed to the SAS log by PROC SEVERITY. A higher number prints messages with the same or more detail.
- CRITERION | CRITERIA | CRIT=criterion-option
-
specifies the model selection criterion.
If two or more models are specified for estimation, then the one with the best value for the selection criterion is chosen as the best model. If the OUTMODELINFO= data set is specified, then the best model’s observation has a value of 1 for the _SELECTED_ variable. You can specify one of the following criterion-options:
- AD
specifies the Anderson-Darling (AD) statistic value, which is computed by using the empirical distribution function (EDF) estimate, as the selection criterion. A lower value is deemed better.
- AIC
specifies the Akaike’s information criterion (AIC) as the selection criterion. A lower value is deemed better.
- AICC
specifies the finite-sample corrected Akaike’s information criterion (AICC) as the selection criterion. A lower value is deemed better.
- BIC
specifies Schwarz Bayesian information criterion (BIC) as the selection criterion. A lower value is deemed better.
- CUSTOM
specifies the custom objective function as the selection criterion. You can specify this only if you also specify the OBJECTIVE= option. A lower value is deemed better.
- CVM
specifies the Cra
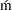 er-von Mises (CvM) statistic value, which is computed by using the empirical distribution function (EDF) estimate, as the selection criterion. A lower value is deemed better.
er-von Mises (CvM) statistic value, which is computed by using the empirical distribution function (EDF) estimate, as the selection criterion. A lower value is deemed better. - KS
specifies the Kolmogorov-Smirnov (KS) statistic value, which is computed by using the empirical distribution function (EDF) estimate, as the selection criterion. A lower value is deemed better.
- LOGLIKELIHOOD | LL
specifies
 as the selection criterion, where
as the selection criterion, where 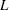 is the likelihood of the data. A lower value is deemed better. This is the default.
is the likelihood of the data. A lower value is deemed better. This is the default.
More details about these criterion-options are provided in the section Statistics of Fit.
- EMPIRICALCDF | EDF=method
-
specifies the method to use for computing the nonparametric or empirical estimate of the cumulative distribution function of the data. You can specify one of the following values for method:
- AUTOMATIC | AUTO
specifies that the method be chosen automatically based on the data specification. This option is the default. If no censoring or truncation is specified, then the standard empirical estimation method (STANDARD) is chosen. If right-censoring or left-censoring are both specified, then Turnbull’s estimation method (TURNBULL) is chosen. For all other combinations of censoring and truncation, the Kaplan-Meier method (KAPLANMEIER) is chosen.
- KAPLANMEIER | KM
specifies that the product limit estimator proposed by Kaplan and Meier (1958) be used. You cannot specify this method when both right-censoring and left-censoring are specified.
- MODIFIEDKM | MKM <(options)>
-
specifies that the modified product limit estimator be used. This method allows Kaplan-Meier’s product limit estimates to be more robust by ignoring the contributions to the estimate due to small risk-set sizes. The risk set is the set of observations at the risk of failing, where an observation is said to fail if it has not been processed yet and might experience censoring or truncation. The minimum risk-set size that makes it eligible to be included in the estimation can be specified either as an absolute lower bound on the size (RSLB= option) or a relative lower bound determined by the formula
 proposed by Lai and Ying (1991). Values of
proposed by Lai and Ying (1991). Values of  and
and  can be specified by using the C= and ALPHA= options, respectively. By default, the relative lower bound is used with values of
can be specified by using the C= and ALPHA= options, respectively. By default, the relative lower bound is used with values of 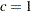 and
and 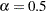 . However, you can modify the default by using the following options:
. However, you can modify the default by using the following options: - ALPHA | A=number
specifies the value to use for
when the lower bound on the risk set size is defined as . This value must satisfy  .
. - C=number
specifies the value to use for
when the lower bound on the risk set size is defined as . This value must satisfy  .
. - RSLB=number
specifies the absolute lower bound on the risk set size to be included in the estimate.
You cannot specify this method when both right-censoring and left-censoring are specified.
- STANDARD | STD
specifies that the standard empirical estimation method be used. This ignores any censoring or truncation information even if specified, and can thus result in estimates that are more biased than those obtained with other methods more suitable for such data. You cannot specify this method when both right-censoring and left-censoring are specified.
-
TURNBULL | EM <(options)>
Experimental -
specifies that the Turnbull’s method be used. This method is used when both right-censoring and left-censoring are specified. An iterative expectation-maximization (EM) algorithm proposed by Turnbull (1976) is used to compute the empirical estimates. If truncation is also specified, then the modification suggested by Frydman (1994) is used. You can modify the default behavior of the EM algorithm by using the following options:
- ENSUREMLE
specifies that the final EDF estimates be maximum likelihood estimates. The Kuhn-Tucker conditions are computed for the likelihood maximization problem and checked to ensure that EM algorithm converges to maximum likelihood estimates. The method generalizes the method proposed by Gentleman and Geyer (1994) by taking into account the truncation information, if specified.
- EPS=number
specifies the maximum relative error to be allowed between estimates of two consecutive iterations. This criterion is used to check the convergence of the algorithm. If you do not specify this option, then PROC SEVERITY uses a default value of 1.0E–8.
- MAXITER=number
specifies the maximum number of iterations to attempt to find the empirical estimates. If you do not specify this option, then PROC SEVERITY uses a default value of 500.
- ZEROPROB=number
specifies the threshold below which an empirical estimate of the probability is considered zero. This option is used to decide if the final estimate is a maximum likelihood estimate. This option does not have an effect if you do not specify the ENSUREMLE option. If you specify the ENSUREMLE option, but do not specify this option, then PROC SEVERITY uses a default value of 1.0E–8.
More details about each of the methods are provided in the section Empirical Distribution Function Estimation Methods.
-
OBJECTIVE=symbol-name
Experimental -
names the symbol that represents the objective function in the specified SAS programming statements. For each model to be estimated, PROC SEVERITY executes the programming statements to compute the value of this symbol for each observation. The values are added across all observations to obtain the value of the objective function. The optimization algorithm estimates the model parameters such that the objective function value is minimized. A separate optimization problem is solved for each candidate distribution. If a BY statement is specified, then a separate optimization problem is solved for each candidate distribution within each BY group.
More details about writing SAS programming statements to define your own objective function are provided in the section Custom Objective Functions.