マクロ処理を使用しないステートメントの処理方法
入力スタックからワードとシンボルを抽出するためにSASが使用するプロセスを、トークン化と呼びます。トークン化は、ワードスキャナと呼ばれるSASのコンポーネントによって実行されます。その説明は、トークン化前のサンプルプログラムに示します。ワードスキャナは、入力スタックの先頭の文字から開始して、各文字を順番に調べます。一般的なトークンは、次の4種類です。
リテラル
引用符で囲まれた文字列。
数値
10進数、日付値、時間値、および16進数。
名前
アンダースコアまたは文字で始まる文字列。
特殊
SASで特殊な意味を持つ文字または文字のグループ。特殊文字の例としては、* / + - ** ; $ ( ) . & % =などがあります。
* / + - ** ; $ ( ) .& % =
前の図では、入力スタック内の最初のSASステートメントには、8つのトークン(4つの名前と4つの特殊文字)が含まれています。
data sales(drop=lastyr);
ワードスキャナは、空白または新しいトークンの先頭を検出すると、そのトークンを入力スタックから削除して、キューの最後尾に転送します。
この例では、ワードスキャナは、入力スタックから最初のトークンを取り出すと、そのトークンをDATAステップの開始として認識します。ワードスキャナによってDATAステップコンパイラが起動され、トークンの要求を開始します。このコンパイラは、次の図に示すように、キューの先頭からトークンを取り出します。
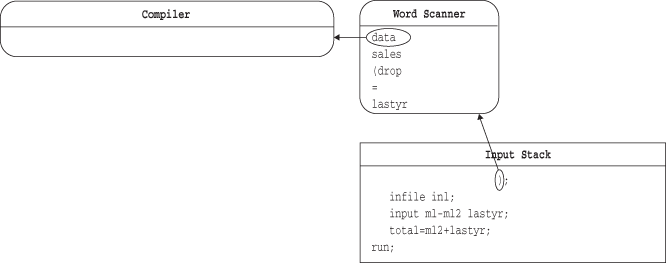
コンパイラは、DATAステップの終了(この場合、RUNステートメント)を認識するまで、トークンを取り出し続けます。DATAステップの終了は、DATAステップの境界とも呼ばれます。これを次の図に示します。DATAステップコンパイラがDATAステップの終了を認識すると、DATAステップが実行されて完了します。
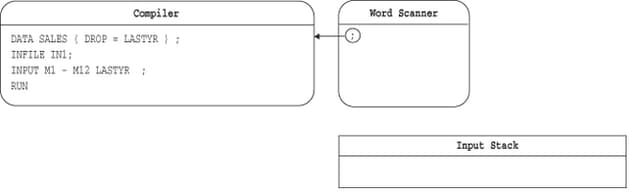
マクロプロセッサ処理を使用しないほとんどのSASプログラムでは、コンパイラが受信するすべての情報は、サブミットされたプログラムからもたらされます。