Introduction to Statistical Modeling with SAS/STAT Software
Residual Analysis
The model errors 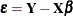 are unobservable. Yet important features of the statistical model are connected to them, such as the distribution of the
data, the correlation among observations, and the constancy of variance. It is customary to diagnose and investigate features
of the model errors
through the fitted residuals
are unobservable. Yet important features of the statistical model are connected to them, such as the distribution of the
data, the correlation among observations, and the constancy of variance. It is customary to diagnose and investigate features
of the model errors
through the fitted residuals 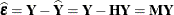 . These residuals are
projections of the data onto the null space of
. These residuals are
projections of the data onto the null space of 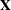 and are also referred to as the
"raw" residuals to contrast them with other forms of residuals that are transformations of
and are also referred to as the
"raw" residuals to contrast them with other forms of residuals that are transformations of 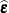 . For the classical linear model, the statistical properties of are affected by the features of that projection and can be summarized as follows:
. For the classical linear model, the statistical properties of are affected by the features of that projection and can be summarized as follows:
![\begin{align*} \mr{E}[\widehat{\bepsilon }] & = \mb{0} \\ \mr{Var}[\widehat{\bepsilon }] & = \sigma ^2\bM \\ \mr{rank}(\bM ) & = n - \mr{rank}(\bX ) \end{align*}](images/statug_intromod0460.png)
Furthermore, if 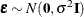 , then
, then 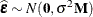 .
.
Because 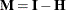 , and the "hat" matrix
, and the "hat" matrix 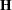 satisfies
satisfies 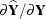 , the hat matrix is also the
leverage matrix of the model. If
, the hat matrix is also the
leverage matrix of the model. If 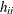 denotes the ith diagonal element of (the leverage of observation i), then the leverages are bounded in a model with intercept,
denotes the ith diagonal element of (the leverage of observation i), then the leverages are bounded in a model with intercept, 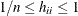 . Consequently, the variance of a raw residual is less than that of an observation:
. Consequently, the variance of a raw residual is less than that of an observation: ![$\mr{Var}[\widehat{\epsilon }_ i] = \sigma ^2(1 - h_{ii}) < \sigma ^2$](images/statug_intromod0466.png) . In applications where the variability of the data is estimated from fitted residuals, the estimate is invariably biased
low. An example is the computation of an empirical semivariogram based on fitted (detrended) residuals.
. In applications where the variability of the data is estimated from fitted residuals, the estimate is invariably biased
low. An example is the computation of an empirical semivariogram based on fitted (detrended) residuals.
More important, the diagonal entries of are not necessarily identical; the residuals are
heteroscedastic. The
"hat" matrix is also not a
diagonal matrix; the residuals are correlated. In summary, the only property that the
fitted residuals share with the model errors is a zero mean. It is thus commonplace to use transformations of the fitted residuals for diagnostic
purposes.
Raw and Studentized Residuals
A standardized residual is a raw residual that is divided by its standard deviation:
![\[ \widehat{\epsilon }_{i}^* = \frac{Y_ i - \widehat{Y}_ i}{\sqrt {\mr{Var}[Y_ i - \widehat{Y}_ i]}} = \frac{\widehat{\epsilon }_ i}{\sqrt {\sigma ^2(1-h_{ii})}} \]](images/statug_intromod0467.png)
Because 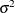 is unknown, residual standardization is usually not practical.
A studentized residual is a raw residual that is divided by its estimated standard deviation. If the estimate of the standard deviation
is based on the same data that were used in fitting the model, the residual is also called an
internally studentized residual:
is unknown, residual standardization is usually not practical.
A studentized residual is a raw residual that is divided by its estimated standard deviation. If the estimate of the standard deviation
is based on the same data that were used in fitting the model, the residual is also called an
internally studentized residual:
![\[ \widehat{\epsilon }_{is} = \frac{Y_ i - \widehat{Y}_ i}{\sqrt {\widehat{\mr{Var}}[Y_ i - \widehat{Y}_ i]}} = \frac{\widehat{\epsilon }_ i}{\sqrt {\widehat{\sigma }^2(1-h_{ii})}} \]](images/statug_intromod0468.png)
If the estimate of the residual’s variance does not involve the ith observation, it is called an
externally studentized residual. Suppose that 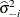 denotes the estimate of the residual variance obtained without the ith observation; then the externally studentized residual is
denotes the estimate of the residual variance obtained without the ith observation; then the externally studentized residual is
![\[ \widehat{\epsilon }_{ir} = \frac{\widehat{\epsilon }_ i}{\sqrt {\widehat{\sigma }^2_{-i}(1-h_{ii})}} \]](images/statug_intromod0470.png)
Scaled Residuals
A scaled residual is simply a raw residual divided by a scalar quantity that is not an estimate of the variance of the residual. For example, residuals divided by the standard deviation of the response variable are scaled and referred to as Pearson or Pearson-type residuals:
![\[ \widehat{\epsilon }_{ic} = \frac{Y_ i - \widehat{Y}_ i}{\sqrt {\widehat{\mr{Var}}[Y_ i]}} \]](images/statug_intromod0471.png)
In generalized linear models, where the variance of an observation is a function of the mean 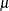 and possibly of an extra scale parameter,
and possibly of an extra scale parameter, ![$\mr{Var}[Y] = a(\mu )\phi $](images/statug_intromod0472.png) , the Pearson residual is
, the Pearson residual is
![\[ \widehat{\epsilon }_{iP} = \frac{Y_ i - \widehat{\mu }_ i}{\sqrt {a(\widehat{\mu })}} \]](images/statug_intromod0473.png)
because the sum of the squared Pearson residuals equals the Pearson 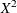 statistic:
statistic:
![\[ X^2 = \sum _{i=1}^ n \widehat{\epsilon }_{iP}^2 \]](images/statug_intromod0475.png)
When the scale parameter  participates in the scaling, the residual is also referred to as a Pearson-type residual:
participates in the scaling, the residual is also referred to as a Pearson-type residual:
![\[ \widehat{\epsilon }_{iP} = \frac{Y_ i - \widehat{\mu }_ i}{\sqrt {a(\widehat{\mu })\phi }} \]](images/statug_intromod0477.png)
Other Residuals
You might encounter other residuals in SAS/STAT software.
A "leave-one-out" residual is the difference between the observed value and the residual obtained from fitting a model in
which the observation in question did not participate. If 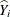 is the predicted value of the ith observation and
is the predicted value of the ith observation and 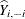 is the predicted value if
is the predicted value if 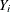 is removed from the analysis, then the "leave-one-out" residual is
is removed from the analysis, then the "leave-one-out" residual is
![\[ \widehat{\epsilon }_{i,-i} = Y_ i - \widehat{Y}_{i,-i} \]](images/statug_intromod0480.png)
Since the sum of the squared "leave-one-out" residuals is the
PRESS statistic (prediction sum of squares; Allen 1974), 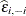 is also called the PRESS residual. The concept of the PRESS residual can be generalized if the
deletion residual can be based on the removal of sets of observations. In the classical linear model, the PRESS residual for
case deletion has a particularly simple form:
is also called the PRESS residual. The concept of the PRESS residual can be generalized if the
deletion residual can be based on the removal of sets of observations. In the classical linear model, the PRESS residual for
case deletion has a particularly simple form:
![\[ \widehat{\epsilon }_{i,-i} = Y_ i - \widehat{Y}_{i,-i} = \frac{\widehat{\epsilon }_ i}{1 - h_{ii}} \]](images/statug_intromod0482.png)
That is, the PRESS residual is simply a scaled form of the raw residual, where the scaling factor is a function of the leverage of the observation.
When data are correlated, ![$\mr{Var}[\bY ] = \bV $](images/statug_intromod0483.png) , you can scale the vector of residuals rather than scale each residual separately. This takes the covariances among the observations
into account. This form of scaling is accomplished by forming the Cholesky root
, you can scale the vector of residuals rather than scale each residual separately. This takes the covariances among the observations
into account. This form of scaling is accomplished by forming the Cholesky root 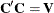 , where
, where 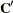 is a lower-triangular matrix. Then
is a lower-triangular matrix. Then 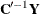 is a vector of uncorrelated variables with unit variance.
The Cholesky residuals in the model
is a vector of uncorrelated variables with unit variance.
The Cholesky residuals in the model 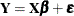 are
are
![\[ \widehat{\bepsilon }_ C = \bC ’^{-1}\left(\bY - \bX \widehat{\bbeta }\right) \]](images/statug_intromod0487.png)
In generalized linear models, the fit of a model can be measured by the scaled deviance statistic 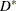 . It measures the difference between the log likelihood under the model and the maximum log likelihood that is achievable.
In models with a scale parameter , the deviance is
. It measures the difference between the log likelihood under the model and the maximum log likelihood that is achievable.
In models with a scale parameter , the deviance is 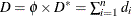 . The
deviance residuals are the signed square roots of the contributions to the deviance statistic:
. The
deviance residuals are the signed square roots of the contributions to the deviance statistic:
![\[ \widehat{\epsilon }_{id} = \mr{sign}\{ y_ i - \widehat{\mu }_ i\} \, \sqrt {d_ i} \]](images/statug_intromod0490.png)