The ADAPTIVEREG Procedure

Example 25.3 Predicting E-Mail Spam
This example shows how you can use PROC ADAPTIVEREG to fit a classification model for a data set with a binary response. It illustrates how you can use the PARTITION statement to create subsets of data for training and testing purposes. It also demonstrates how to use the OUTPUT statement. Finally, it shows how you can improve the modeling speed by changing some default settings.
This example concerns a study on classifying whether an e-mail is junk e-mail (coded as 1) or not (coded as 0). The data were collected in Hewlett-Packard labs and donated by George Forman. The data set contains 4,601 observations with 58 variables. The response variable is a binary indicator of whether an e-mail is considered spam or not. The 57 variables are continuous variables that record frequencies of some common words and characters in e-mails and lengths of uninterrupted sequences of capital letters. The data set is publicly available at the UCI Machine Learning repository (Asuncion and Newman 2007).
This example shows how you can use PROC ADAPTIVEREG to build a model with good predictive power and then use it to classify observations in independent data sets. PROC ADAPTIVEREG enables you to partition your data into subsets for training, validation, and testing. The training set is used to build models, the validation set is used to estimate prediction errors and select models, and the testing set is used independently to evaluate the final model. When the sample size is not large enough, sample reusing approaches are used instead, such as bootstrap and cross validation. For this data set, the sample size is sufficient to support a random partitioning. Because the GCV model selection criterion itself serves as an estimate of prediction error, this data set is split into two separate subsets. The training set is used to build the classification model, and the test set is used to evaluate the model. The PARTITION statement performs the random partitioning for you, as shown in the following statements:
proc adaptivereg data=sashelp.junkmail seed=10359;
model class = Address Addresses All Bracket Business
CS CapAvg CapLong CapTotal Conference
Credit Data Direct Dollar Edu
Email Exclamation Font Free George
HP HPL Internet Lab Labs
Mail Make Meeting Money Order
Original Our Over PM Paren
Parts People Pound Project RE
Receive Remove Report Semicolon Table
Technology Telnet Will You Your
_000 _85 _415 _650 _857
_1999 _3D / additive dist=binomial;
partition fraction(test=0.333);
output out=spamout p(ilink);
run;
The FRACTION
option in the PARTITION
statement specifies that 33.3% of observations in the sashelp.junkmail data set are randomly selected to form the testing set while the rest of the data form the training set. If you want to use
the same partitioning for further analysis, you can specify the seed for the random number generator so that the exact same
random number stream can be duplicated. For the preceding statements, the seed is 10359, which is specified in the PROC ADAPTIVEREG
statement. The response variable is a two-level variable. The ADDITIVE
option specifies that this is an additive model without interactions between spline basis functions; this option makes the
predictive model more interpretable. The DIST=BINOMIAL option specifies the distribution of the response variable. The ILINK
option in the OUTPUT
statement requests predicted probabilities for each observation.
The "Model Information" table in Output 25.3.1 includes the distribution, link function, and the random number seed.
Output 25.3.1: Model Information
The "Number of Observations" table in Output 25.3.2 lists the total number of observations used. It also lists number of observations for the training set and the test set.
Output 25.3.2: Number of Observations
The response variable is a binary classification variable. PROC ADAPTIVEREG produces the "Response Profile" table in Output 25.3.3. The table shows the response level frequencies for the training set and the probability that PROC ADAPTIVEREG models.
Output 25.3.3: Response Profile
The "Fit Statistics" table in Output 25.3.3 shows that the final model for the training set contains large effective degrees freedom.
Output 25.3.4: Fit Statistics
To classify e-mails from the test set, the following rule is used. For each observation, the e-mail is classified as spam
if the predicted probability of Class = '0' is greater than the predicted probability of Class = '1', and ham (a good e-mail) otherwise. Because the response is binary, you can classify an e-mail as spam if the predicted
probability of Class = '0' is less than 0.5. The following statements evaluate classification errors:
data test; set spamout(where=(_ROLE_='TEST')); if ((pred>0.5 & class=0) | (pred<0.5 & class=1)) then Error=0; else error=1; run;
proc freq data=test; tables class*error/nocol; run;
Output 25.3.5 shows the misclassification errors for all observations and observations of each response category. Compared to the results from other statistical learning algorithms that use different training subsets (Hastie, Tibshirani, and Friedman 2001), these results from PROC ADAPTIVEREG are competitive.
Output 25.3.5: Crosstabulation Table for Test Set Prediction
It takes approximately 300MB of memory and about 102 seconds to fit the model on a workstation with a 12-way 2.6GHz AMD Opteron
processor. The following analyses illustrate how you can change some default settings to improve the modeling speed without
sacrificing much predictive capability. As discussed in the section Computational Resources, the computation cost for PROC ADAPTIVEREG is proportional to 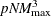 . For the same data set, you can significantly increase the modeling speed by reducing the maximum number of basis functions
that are allowed for the forward selection.
. For the same data set, you can significantly increase the modeling speed by reducing the maximum number of basis functions
that are allowed for the forward selection.
PROC ADAPTIVEREG uses 115 as the maximum number of basis functions. Suppose you want to set the maximum number to 61, which is approximately half the default value. The following program fits a multivariate adaptive regression splines model with MAXBASIS= set to 61. The same random number seed is used to get the exact same data partitioning.
proc adaptivereg data=sashelp.junkmail seed=10359;
model class = Address Addresses All Bracket Business
CS CapAvg CapLong CapTotal Conference
Credit Data Direct Dollar Edu
Email Exclamation Font Free George
HP HPL Internet Lab Labs
Mail Make Meeting Money Order
Original Our Over PM Paren
Parts People Pound Project RE
Receive Remove Report Semicolon Table
Technology Telnet Will You Your
_000 _85 _415 _650 _857
_1999 _3D / maxbasis=61 additive dist=binomial;
partition fraction(test=0.333);
output out=spamout2 p(ilink);
run;
The "Fit Statistics" table in Output 25.3.6 displays summary statistics for the second model. The log likelihood of the second model is smaller than that of the first model, which is expected because the effective degrees of freedom is 95, much smaller than the effective degrees of freedom of the first model. This means that the fitted model is much simpler than the first model. Both the GCV and GCV R-square values show that the estimated prediction capability of the second model is slightly less than the first model.
Output 25.3.6: Fit Statistics
By predicting observations in the test set, the second model has an overall misclassification error of 5.28%, which is slightly lower than that of the first model. This shows that the predictive power of the second model is actually greater than of the first model due to reduced model complexity. The computation takes around 21 seconds on the same workstation and consumes approximately 170MB of memory. This is a significant improvement in both computation speed and memory cost.
You can further improve the modeling speed by using the FAST option in the MODEL statement. The FAST option avoids evaluating certain combinations of parent basis functions and variables. For example, you can specify the FAST(K=20) option so that in each forward selection iteration, PROC ADAPTIVEREG uses only the top 20 parent basis functions (based on their maximum improvement from the previous iteration) to construct and evaluate new basis functions. The underlying assumption, as discussed in the section Fast Algorithm, is that parent basis functions that offer low improvement at previous steps are less likely to yield new basis functions that offer large improvement at the current step. The following statements illustrate the FAST option:
proc adaptivereg data=sashelp.junkmail seed=10359;
model class = Address Addresses All Bracket Business
CS CapAvg CapLong CapTotal Conference
Credit Data Direct Dollar Edu
Email Exclamation Font Free George
HP HPL Internet Lab Labs
Mail Make Meeting Money Order
Original Our Over PM Paren
Parts People Pound Project RE
Receive Remove Report Semicolon Table
Technology Telnet Will You Your
_000 _85 _415 _650 _857
_1999 _3D / maxbasis=61 fast(k=20) additive dist=binomial;
partition fraction(test=0.333);
output out=spamout3 p(ilink);
run;
The fitted model is the same as the second model. The computation time on the same workstation is even less at 19 seconds. You should tune the parameters for the FAST option with care because the underlying assumption does not always hold.
With this investigation, the second model can serve as a good classifier. It contains 26 variables. The "Variable Importance"
table (Output 25.3.7) lists all variables and their importance values in descending order. Two variables in the model, George and Hp, are important factors in classifying e-mails as not spam. George Forman, the donor of the original data set, collected e-mails
from filed work and personal e-mails at Hewlett-Packard labs. Thus these two variables are strong indicators of e-mails that
are not spam. This confirms the results from the fitted multivariate adaptive regression splines model by PROC ADAPTIVEREG.
Output 25.3.7: Variable Importance
| Variable Importance | ||
|---|---|---|
| Variable | Number of Bases |
Importance |
| George | 1 | 100.00 |
| HP | 1 | 78.35 |
| Edu | 3 | 61.25 |
| Remove | 2 | 49.21 |
| Exclamation | 3 | 44.14 |
| Free | 2 | 34.18 |
| Meeting | 3 | 32.57 |
| _1999 | 2 | 29.71 |
| Dollar | 2 | 28.30 |
| Money | 3 | 26.39 |
| CapLong | 3 | 24.41 |
| Our | 2 | 19.46 |
| Semicolon | 2 | 14.98 |
| RE | 2 | 13.52 |
| Business | 3 | 13.48 |
| Over | 3 | 12.63 |
| CapTotal | 3 | 12.50 |
| Will | 1 | 10.81 |
| Pound | 2 | 9.73 |
| Internet | 1 | 5.88 |
| _000 | 1 | 4.57 |
| You | 2 | 3.17 |