The SURVEYMEANS Procedure

The SURVEYMEANS procedure produces output that is described in the following sections.
The "Data Summary" table provides information about the input data set and the sample design. This table displays the total number of valid observations, where an observation is considered valid if it has nonmissing values for all procedure variables other than the analysis variables—that is, for all specified STRATA , CLUSTER , DOMAIN , POSTSTRATA , and WEIGHT variables. This number might differ from the number of nonmissing observations for an individual analysis variable, which the procedure displays in the "Statistics" table. See the section Missing Values for more information.
PROC SURVEYMEANS displays the following information in the "Data Summary" table:
-
Number of Strata, if you specify a STRATA statement
-
Number of Poststrata, if you specify a POSTSTRATA statement
-
Number of Clusters, if you specify a CLUSTER statement
-
Number of Observations, which is the total number of valid observations
-
Sum of Weights, which is the sum over all valid observations, if you specify a WEIGHT statement
If you use a CLASS statement to name classification variables for categorical analysis, or if you list any character variables in the VAR statement, then PROC SURVEYMEANS displays a "Class Level Information" table. This table contains the following information for each classification variable:
-
CLASS Variable, which lists each CLASS variable name
-
Levels, which is the number of values or levels of the classification variable
-
Values, which lists the values of the classification variable. The values are separated by a white space character; therefore, to avoid confusion, you should not include a white space character within a classification variable value.
If you specify the LIST option in the STRATA statement, PROC SURVEYMEANS displays a "Stratum Information" table. This table displays the number of valid observations in each stratum, as well as the number of nonmissing stratum observations for each analysis variable. The "Stratum Information" table provides the following for each stratum:
-
Stratum Index, which is a sequential stratum identification number
-
STRATA variable(s), which lists the levels of STRATA variables for the stratum
-
Population Total, if you specify the TOTAL= option
-
Sampling Rate, if you specify the TOTAL= or RATE= option. If you specify the TOTAL= option, the sampling rate is based on the number of valid observations in the stratum.
-
N Obs, which is the number of valid observations
-
Variable, which lists each analysis variable name
-
Levels, which identifies each level for categorical variables
-
N, which is the number of nonmissing observations for the analysis variable
-
Clusters, which is the number of clusters, if you specify a CLUSTER statement
If the variance method is not Taylor series or if the NOMCAR option is used, by default, PROC SURVEYMEANS displays the following variance estimation specifications in the "Variance Estimation" table:
-
Method, which is the variance estimation method
-
Replicate Weights Data Set, which is the name of the SAS data set that contains the replicate weights
-
Number of Replicates, which is the number of replicates if you specify the VARMETHOD=BRR or VARMETHOD=JACKKNIFE option
-
Hadamard Data Set, which is the name of the SAS data set for the HADAMARD matrix if you specify the VARMETHOD=BRR(HADAMARD=) method-option
-
Fay Coefficient, which is the value of the FAY coefficient if you specify the VARMETHOD=BRR(FAY) method-option
-
Missing Levels Included (MISSING), if you specify the MISSING option
-
Missing Levels Included (NOMCAR), if you specify the NOMCAR option
The "Statistics" table displays all of the statistics that you request with statistic-keywords in the PROC SURVEYMEANS statement, except DECILES, MEDIAN, Q1, Q3, and QUARTILES, which are displayed in the "Quantiles" table. If you do not specify any statistic-keywords, then by default this table displays the following information for each analysis variable: the sample size, the mean, the standard error of the mean, and the confidence limits for the mean. The "Statistics" table can contain the following information for each analysis variable, depending on which statistic-keywords you request:
-
Variable name
-
Variable Label
-
Level, which identifies each level for categorical variables
-
N, which is the number of nonmissing observations
-
N Miss, which is the number of missing observations
-
Minimum
-
Maximum
-
Range
-
Number of Clusters
-
Sum of Weights
-
DF, which is the degrees of freedom for the t test
-
Mean
-
Std Error of Mean, which is the standard error of the mean
-
Var of Mean, which is the variance of the mean
-
t Value, for testing
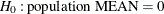
-
Pr
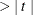 , which is the two-sided p-value for the t test
, which is the two-sided p-value for the t test
-
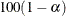 % CL for Mean, which are two-sided confidence limits for the mean
% CL for Mean, which are two-sided confidence limits for the mean
-
% Upper CL for Mean, which is a one-sided upper confidence limit for the mean
-
% Lower CL for Mean, which is a one-sided lower confidence limit for the mean
-
Coeff of Variation, which is the coefficient of variation for the mean
-
Sum
-
Std Dev, which is the standard deviation of the sum
-
Var of Sum, which is the variance of the sum
-
% CL for Sum, which are two-sided confidence limits for the sum
-
% Upper CL for Sum, which is a one-sided upper confidence limit for the sum
-
% Lower CL for Sum, which is a one-sided lower confidence limit for the Sum
-
Coeff of Variation for sum, which is the coefficient of variation for the sum
The "Quantiles" table displays all the quantiles that you request with either statistic-keywords such as DECILES, MEDIAN, Q1, Q3, and QUARTILES, or the PERCENTILE= option, or the QUANTILE= option in the PROC SURVEYMEANS statement.
The "Quantiles" table contains the following information for each quantile:
-
Variable name
-
Variable Label
-
Percentile, which is the requested quantile in the format of %
-
Percentile Label, which is the corresponding common name for a percentile if it exists—for example, Median for 50th percentile
-
Estimate, which is the estimate for a requested quantile with respect to the population distribution
-
Std Error, which is the standard error of the quantile
-
% Confidence Limits, which are two-sided confidence limits for the quantile
If you specify a DOMAIN statement, the procedure displays domain statistics in a "Domain Analysis" table. A "Domain Analysis" table displays all the requested statistics for each level of the domain request. The procedure produces a separate "Domain Analysis" for each separate domain request. For example, the DOMAIN statement
domain A B*C*D A*C C;
specifies four domain requests:
-
A: all the levels ofA -
C: all the levels ofC -
A*C: all the interactive levels ofAandC -
B*C*D: all the interactive levels ofB,C, andD
The procedure displays four "Domain Analysis" tables, one for each domain definition. If you use an ODS OUTPUT statement to
create an output data set for domain analysis, the output data set contains a variable Domain whose values are these domain definitions. It contains all the columns in the "Statistics" table plus columns of domain variable
values.
If you specify a DOMAIN statement, and if you request statistics by specifying either statistic-keywords such as DECILES, MEDIAN, Q1, Q3, and QUARTILES, or the PERCENTILE= option, or the QUANTILE= option in the PROC SURVEYMEANS statement, then the procedure displays domain quantiles in a "Domain Quantiles" table. This table displays all the quantile statistics for each level of the domain request. It contains all the columns in the "Quantiles" table plus columns of DOMAIN variable values.
The "Ratio Analysis" table displays statistics for all the ratios that you request in the RATIO statement. If you do not specify any statistic-keywords in the PROC SURVEYMEANS statement, then by default this table displays the ratios and standard errors. The "Ratio Analysis" table can contain the following information for each ratio, depending on which statistic-keywords you request:
-
Numerator, which identifies the numerator variable of the ratio
-
Denominator, which identifies the denominator variable of the ratio
-
N, which is the number of observations used in the ratio analysis
-
number of Clusters
-
Sum of Weights
-
DF, which is the degrees of freedom for the t test
-
Ratio
-
Std Err of Ratio, which is the standard error of the ratio
-
Var, which is the variance of the ratio
-
t Value, for testing
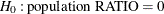
-
Pr
, which is the two-sided p-value for the t test
-
% CL for Ratio, which are two-sided confidence limits for the Ratio
-
Upper
% CL for Ratio, which are one-sided upper confidence limits for the Ratio
-
Lower
% CL for Ratio, which are one-sided lower confidence limits for the Ratio
When you use the ODS OUTPUT statement to create an output data set, if you use labels for your RATIO statement, these labels
are saved in the variable Ratio Statement in the output data set.
If you specify a DOMAIN statement with a RATIO statement, the procedure displays domain ratios in a "Domain Ratio Analysis" table. A "Domain Ratio Analysis" table displays all the ratio statistics for each level of the domain request. It contains all the columns in the "Ratio Analysis" table plus columns of domain variable values.
If you specify the VARMETHOD=BRR(PRINTH) method-option in the PROC SURVEYMEANS statement, PROC SURVEYMEANS displays the Hadamard matrix that is used to construct replicates for BRR variance estimation.
If you provide a Hadamard matrix with the VARMETHOD=BRR(HADAMARD=) method-option but the procedure does not use the entire matrix, the procedure displays only the rows and columns that are actually used to construct replicates.
The "Geometric Means" table displays all the statistics related to geometric mean that you request with statistic-keywords in the PROC SURVEYMEANS statement. The "Geometric Means" table can contain the following information for each analysis variable, depending on which statistic-keywords you request:
-
Variable Name
-
Variable Label
-
Geometric Mean
-
Std Error of Geometric Mean
-
% CL for Geometric Mean, which are two-sided confidence limits for the geometric mean
-
% Lower CL for Geometric Mean, which is a one-sided lower confidence limit for the geometric mean
-
% Upper CL for Geometric Mean, which is a one-sided upper confidence limit for the geometric mean
If you specify a DOMAIN statement and request any statistics related to geometric mean with statistic-keywords in the PROC SURVEYMEANS statement, the procedure displays these statistics for each domain level in a "Domain Geometric Means" table. It contains all the columns in the "Geometric Means" table plus columns of domain variable values.