The MCMC Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsHow PROC MCMC WorksBlocking of ParametersSampling MethodsTuning the Proposal DistributionDirect SamplingConjugate SamplingInitial Values of the Markov ChainsAssignments of ParametersStandard DistributionsUsage of Multivariate DistributionsSpecifying a New DistributionUsing Density Functions in the Programming StatementsTruncation and CensoringSome Useful SAS FunctionsMatrix Functions in PROC MCMCCreate Design MatrixModeling Joint LikelihoodRegenerating Diagnostics PlotsCaterpillar PlotAutocall Macros for PostprocessingGamma and Inverse-Gamma DistributionsPosterior Predictive DistributionHandling of Missing DataFunctions of Random-Effects ParametersFloating Point Errors and OverflowsHandling Error MessagesComputational ResourcesDisplayed OutputODS Table NamesODS Graphics
-
ExamplesSimulating Samples From a Known DensityBox-Cox TransformationLogistic Regression Model with a Diffuse PriorLogistic Regression Model with Jeffreys’ PriorPoisson RegressionNonlinear Poisson Regression ModelsLogistic Regression Random-Effects ModelNonlinear Poisson Regression Multilevel Random-Effects ModelMultivariate Normal Random-Effects ModelMissing at Random AnalysisNonignorably Missing Data (MNAR) AnalysisChange Point ModelsExponential and Weibull Survival AnalysisTime Independent Cox ModelTime Dependent Cox ModelPiecewise Exponential Frailty ModelNormal Regression with Interval CensoringConstrained AnalysisImplement a New Sampling AlgorithmUsing a Transformation to Improve MixingGelman-Rubin Diagnostics
- References
MODEL dependent-variable-list ~distribution <options> ;
The MODEL statement specifies the conditional distribution of the data given the parameters (the likelihood function). You specify a single dependent variable or a list of dependent variables, a tilde ~, and then a distribution with its arguments. The dependent variables can be variables from the input data set or functions of the symbols in the program. You must specify the dependent variables unless you use the GENERAL function or the DGENERAL function (see the section Specifying a New Distribution for more details).
The MODEL statement assumes that the observations are independent of each other, conditional on the model parameters. If you
want to model dependent data—that is, ![]() for
for ![]() —you can use the JOINTMODEL option in the PROC MCMC statement. See the section Modeling Joint Likelihood for more details. By default, the log-likelihood value is the sum of the individual log-likelihood value for each observation.
—you can use the JOINTMODEL option in the PROC MCMC statement. See the section Modeling Joint Likelihood for more details. By default, the log-likelihood value is the sum of the individual log-likelihood value for each observation.
You can specify multiple MODEL statements. You can define likelihood functions that are independent of each other. For example,
in the following statements, the dependent variables y1 and y2 are independent of each other:
model y1 ~ normal(alpha, var=s21); model y2 ~ normal(beta, var=s22);
Alternatively, you can use marginal and conditional distributions to define a joint log-likelihood function for multiple dependent
variables. For example, the following statements jointly define a distribution over ![]() . They specify a marginal distribution for the dependent variable
. They specify a marginal distribution for the dependent variable y1 and a conditional distribution for the dependent variable y2:
model y1 ~ normal(alpha, var=s21); model y2 ~ normal(beta * y1, var=s22);
Every program must have at least one MODEL statement. If you want to run a Monte Carlo simulation that does not require a response variable, use the GENERAL function in the MODEL statement:
model general(0);
PROC MCMC interprets the statement as a flat likelihood function with a constant log-likelihood value of 0.
PROC MCMC is a programming language that is similar to the DATA step, and the order of statement evaluation is important. For example, the MODEL statement must come after any SAS programming statements that define or modify arguments used in the construction of the log likelihood. In PROC MCMC, a symbol can be defined multiple times and used at different places. Using an expression out of order produces erroneous results that can also be hard to detect.
Do not embed the MODEL statement within programming statements. For example, suppose you have three response variables, y1, y2, and y3, and want to model each with a normal distribution. The following statements lead to erroneous output:
array Y[3] y1 y2 y3; do i = 1 to 3; model y[i] ~ normal(mu, sd=s); end;
Instead, you should do one of the following.
-
Use separate MODEL statements:
model y1 ~ normal(mu, sd=s); model y2 ~ normal(mu, sd=s); model y3 ~ normal(mu, sd=s);
-
Use the GENERAL function to construct a joint distribution of the three dependent variables and use a single MODEL statement to specify the log-likelihood function:
llike = logpdf("normal", y1, mu, s) + logpdf("normal", y2, mu, s) + logpdf("normal", y3, mu, s); model y1 y2 y3 ~ general(llike);See the section Specifying a New Distribution for more information about how to use the GENERAL function to specify an arbitrary distribution.
Missing data are allowed in the response variables; the MODEL statement augments missing data automatically. (In releases before SAS/STAT 12.1, observations with missing values were discarded prior to analysis and PROC MCMC did not attempt to model these values.) In each iteration, PROC MCMC samples missing values from their posterior distributions and incorporates them as part of the simulation. PROC MCMC creates one variable for each missing response value. There are two ways to create the missing value variable names; see the NAMESUFFIX= option for the naming convention of the variables.
Standard distributions that the MODEL statement supports are listed in the Table 55.2 (univariate) and Table 55.3 (multivariate). See the section Standard Distributions for density specifications. You can also specify all distributions except the multinomial distribution in the PRIOR and HYPERPRIOR statements. The RANDOM statement supports only a subset of the distributions (see Table 55.4).
PROC MCMC allows some distributions to be parameterized in multiple ways. For example, you can specify a normal distribution with a variance, standard deviation, or precision parameter. For distributions that have different parameterizations, you must specify an option to clearly name the ambiguous parameter. For example, in the normal distribution, you must indicate whether the second argument represents variance, standard deviation, or precision.
All univariate distributions, with the exception of binary and uniform, can have the optional LOWER= and UPPER= arguments, which specify a truncated density. See the section Truncation and Censoring for more details. Truncation is not supported for multivariate distributions.
Table 55.2: Univariate Distributions
|
Distribution Name |
Definition |
|---|---|
|
beta(<a=> |
Beta distribution with shape parameters |
|
binary(<prob|p=> p) |
Binary (Bernoulli) distribution with probability of success p. You can use the alias bern for this distribution. |
|
binomial (<n=> n, <prob|p=> p) |
Binomial distribution with count n and probability of success p |
|
cauchy (<location|loc|l=> |
Cauchy distribution with location |
|
chisq(<df=> |
|
|
dgeneral(ll) |
General log-likelihood function that you construct using SAS programming statements for single or multiple discrete parameters. Also see the function general. The name dlogden is an alias for this function. |
|
expchisq(<df=> |
Log transformation of a |
|
Log transformation of an exponential distribution with scale or inverse-scale parameter |
|
|
expGamma(<shape|sp=> a, scale|s= |
Log transformation of a gamma distribution with shape a and scale or inverse-scale |
|
expichisq(<df=> |
Log transformation of an inverse |
|
expiGamma(<shape|sp=> a, scale|s= |
Log transformation of an inverse-gamma distribution with shape a and scale or inverse-scale |
|
expsichisq(<df=> |
Log transformation of a scaled inverse |
|
Exponential distribution with scale or inverse-scale parameter |
|
|
gamma(<shape|sp=> a, scale|s= |
Gamma distribution with shape a and scale or inverse-scale |
|
geo(<prob|p=> p) |
Geometric distribution with probability p |
|
general(ll) |
General log-likelihood function that you construct using SAS programming statements for a single or multiple continuous parameters. The argument ll is an expression for the log of the distribution. If there are multiple variables specified before the tilde in a MODEL, PRIOR, or HYPERPRIOR statement, ll is interpreted as the log of the joint distribution for these variables. Note that in the MODEL statement, the response variable specified before the tilde is just a place holder and is of no consequence; the variable must have appeared in the construction of ll in the programming statements. general(constant) is equivalent to a uniform distribution on the real line. You can use the alias logden for this distribution. |
|
ichisq(<df=> |
Inverse |
|
igamma(<shape|sp=> a, scale|s= |
Inverse-gamma distribution with shape a and scale or inverse-scale |
|
laplace(<location|loc|l=> |
Laplace distribution with location |
|
logistic(<location|loc|l=> a, <scale|s=> b) |
Logistic distribution with location a and scale b |
|
lognormal(<mean|m=> |
Log-normal distribution with mean |
|
negbin(<n=> n, <prob|p=> p) |
Negative binomial distribution with count n and probability of success p. You can use the alias nb for this distribution. |
|
normal(<mean|m=> |
Normal (Gaussian) distribution with mean |
|
pareto(<shape|sp=> a, <scale|s=> b) |
Pareto distribution with shape a and scale b |
|
poisson(<mean|m=> |
Poisson distribution with mean |
|
sichisq(<df=> |
Scaled inverse |
|
t(<mean|m=> |
T distribution with mean |
|
uniform(<left|l=> a, <right|r=> b) |
Uniform distribution with range a and b. You can use the alias unif for this distribution. |
|
wald(<mean|m=> |
Wald distribution with mean parameter |
|
weibull( |
Weibull distribution with location (threshold) parameter |
Table 55.3: Multivariate Distributions
|
Distribution Name |
Definition |
|---|---|
|
dirichlet(<alpha=> |
Dirichlet distribution with parameter vector |
|
iwish(<df=> |
Inverse Wishart distribution with |
|
mvn(<mu=> |
Multivariate normal distribution with mean vector |
|
mvnar(<mu=> |
Multivariate normal distribution with mean vector |
|
multinom(<p=>p) |
Multinomial distribution with probability vector p |
The options in the MODEL statement apply only when there are missing values in the response variable. You can specify the following options:
- INITIAL=SAS-data-set | constant | numeric-list
-
specifies the initial values of the missing values. By default, PROC MCMC uses a sample average of the nonmissing values of a response variable as the starting values for all missing values in the simulation for that variable. You can use the INITIAL= option to start the Markov chain at a different place.
If you use a SAS-data-set to store initial values, the data set must consist of variable names that agree with the missing variable names that are used by PROC MCMC. The easiest way to find the names of the internally created variables is to run a default analysis with a very small number of simulations and check the variable names in the OUTPOST= data set. You can provide a subset of the initial values in the SAS-data-set, and PROC MCMC uses a default mechanism to fill in the rest of the missing initial values.
For example, the following statement creates a data set with initial values for the first three missing values of a response variable:
data RandomInit; input y_1 y_2 y_3; datalines; 2.3 3 -3 ;
The following MODEL statement uses the values in the
RandomInitdata set as the initial values of the corresponding missing values in the model:model y ~ normal(0,var=s2u) init=randominit;
Specifying a constant assigns that constant as the initial value to all missing values in that response variable. For example, the following statement assigns the value 5 to be used as an initial value for all missing
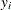 in the model:
in the model:
model y ~ normal(0,var=s2u) init=5;
If you have a multidimensional response variable, you can provide a list of numbers that have the same length as the dimension of your response array. Each number is then given to all corresponding missing variables in order. For example, the following statement assigns the value 2 to be used as an initial value for all missing
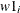 and the value 3 to be used for all missing
and the value 3 to be used for all missing 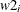 in the model:
in the model:
array w[2] w1 w2; model w ~ mvn(mu, cov) init=(2 3);
- MONITOR= (symbol-list | number-list | RANDOM(number))
-
outputs analysis for selected missing data variables. You can choose to monitor the missing values by listing the response variable names, the missing data variable names, or indices, or you can have them randomly selected by PROC MCMC.
For example, suppose that the data set contains 10 observations and the response variable
yhas missing values in observations 2, 3, 7, 9, and 10. To monitor all missing data variables (five in total), you specify the response variable name in the MONITOR= option:model y ~ normal(0,var=s2u) monitor=(y);
Suppose you want to monitor the missing data variables that correspond to the missing values in observations 2, 3, and 10. You have two options: provide either a list of variable names or a list of indices.
The following statement selects monitored variables by their variable names:
model y ~ normal(0,var=s2u) monitor=(y_2 y_3 y_10);
The variable names must match the internally created variable names for each missing value. See NAMESUFFIX= option for the naming convention of the variables. By default, the names are created by concatenating the response variable with the observation index; hence you use the
name_obsformat to construct the names. The numbers 2, 3, and 10 are the corresponding observation indices to the missing values in the input data set.The following statement selects monitored variables by indices:
model y ~ normal(0,var=s2u) monitor=(1 2 5);
The indices are not a list of the observation numbers, but rather the order by which the missing values appear in the data set: PROC MCMC reports back the first, the second, and the fifth missing value variables that it creates. The actual variable names that appear in the output are still
y_2,y_3, andy_10, honoring the control of the NAMESUFFIX= option.Lastly, PROC MCMC can randomly choose a subset of the variables to monitor. The following statement randomly selects 3 variables to monitor:
model y ~ normal(0,var=s2u) monitor=(random(3));
The list of the random indices is controlled by the SEED= option in the PROC MCMC statement. Therefore, the selected variables will be the same when the SEED= option is the same.
- NAMESUFFIX=OBSERVATION | POSITION | ORDER
-
specifies how the names of the missing data variables are created. By default, the names are created by concatenating the response variable symbol, an underscore (“_”), and the observation number of the missing value.
NAMESUFFIX=OBSERVATION constructs the parameter names by appending the observation number to the response variable symbol. This is the default. NAMESUFFIX=POSITION or NAMESUFFIX=ORDER construct the parameter names by appending the numbers 1, 2, 3, and so on, where the number indicates the order in which the missing values appear in the data set.
For example, suppose you have a response variable
ywith 10 observations in total, of which five are missing (observations 2, 3, 7, 9, and 10). By default, PROC MCMC creates five variable namesy_2,y_3,y_7,y_9, andy_10. UsingNAMESUFFIX=POSITIONchanges the names toy_1,y_2,y_3,y_4, andy_5. - NOOUTPOST
-
suppresses the output of the posterior samples of missing data variables to the posterior output data set (which is specified in the OUTPOST= option in the PROC MCMC statement). In models with a large number of missing values (for example, tens of thousands), PROC MCMC can run faster if it does not save the posterior samples.
When you specify both the NOOUTPOST option and the MONITOR= option, PROC MCMC outputs the list of variables that are monitored.
The maximum number of variables that can be saved to an OUTPOST= data set is 32,767. If the total number of parameters in your model, including the number of missing data variables, exceeds the limit, the NOOUTPOST option is evoked automatically and PROC MCMC does not save the missing value draws to the posterior output data set. You can use the MONITOR= option to select a subset of the parameters to store in the OUTPOST= data set.