The PLS Procedure

PROC PLS Statement
PROC PLS <options> ;
The PROC PLS statement invokes the PLS procedure. Optionally, you can also indicate the analysis data and method in the PROC PLS statement. Table 70.1 summarizes the options available in the PROC PLS statement.
Table 70.1: PROC PLS Statement Options
|
Option |
Description |
|---|---|
|
Displays the centering and scaling information |
|
|
Specifies the cross validation method to be used |
|
|
Specifies that van der Voet’s (1994) randomization-based model comparison test be performed |
|
|
Names the SAS data set |
|
|
Displays the details of the fitted model |
|
|
Specifies the general factor extraction method to be used |
|
|
Specifies how observations with missing values are to be handled in computing the fit |
|
|
Specifies the number of factors to extract |
|
|
Suppresses centering of the responses and predictors before fitting |
|
|
Suppresses re-centering and rescaling of the responses and predictors when cross-validating |
|
|
Suppresses the normal display of results |
|
|
Suppresses scaling of the responses and predictors before fitting |
|
|
Controls the plots produced through ODS Graphics |
|
|
Specifies that continuous model variables be centered and scaled |
|
|
Displays the amount of variation accounted for in each response and predictor |
The following options are available.
- CENSCALE
-
lists the centering and scaling information for each response and predictor.
-
CV=ONE
CV=SPLIT <(n)>
CV=BLOCK <(n)>
CV=RANDOM <(cv-random-opts)>
CV=TESTSET(SAS-data-set) -
specifies the cross validation method to be used. By default, no cross validation is performed. The method CV=ONE requests one-at-a-time cross validation, CV=SPLIT requests that every nth observation be excluded, CV=BLOCK requests that n blocks of consecutive observations be excluded, CV=RANDOM requests that observations be excluded at random, and CV=TESTSET(SAS-data-set) specifies a test set of observations to be used for validation (formally, this is called “test set validation” rather than “cross validation”). You can, optionally, specify n for CV=SPLIT and CV=BLOCK; the default is n = 7. You can also specify the following optional cv-random-options in parentheses after the CV=RANDOM option:
- CVTEST <(cvtest-options)>
-
specifies that van der Voet’s (1994) randomization-based model comparison test be performed to test models with different numbers of extracted factors against the model that minimizes the predicted residual sum of squares; see the section Cross Validation for more information. You can also specify the following cv-test-options in parentheses after the CVTEST option:
- PVAL=n
-
specifies the cutoff probability for declaring an insignificant difference. The default value is 0.10.
- STAT=test-statistic
-
specifies the test statistic for the model comparison. You can specify either T2, for Hotelling’s
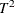 statistic, or PRESS, for the predicted residual sum of squares. The default value is T2.
statistic, or PRESS, for the predicted residual sum of squares. The default value is T2.
- NSAMP=n
-
specifies the number of randomizations to perform. The default value is 1000.
- SEED=n
-
specifies the seed value for randomization generation (the clock time is used by default).
- DATA=SAS-data-set
-
names the SAS data set to be used by PROC PLS. The default is the most recently created data set.
- DETAILS
-
lists the details of the fitted model for each successive factor. The details listed are different for different extraction methods; see the section Displayed Output for more information.
-
METHOD=PLS <( PLS-options )>
METHOD=SIMPLS
METHOD=PCR
METHOD=RRR -
specifies the general factor extraction method to be used. The value PLS requests partial least squares, SIMPLS requests the SIMPLS method of de Jong (1993), PCR requests principal components regression, and RRR requests reduced rank regression. The default is METHOD=PLS. You can also specify the following optional PLS-options in parentheses after METHOD=PLS:
- ALGORITHM=NIPALS | SVD | EIG | RLGW
-
names the specific algorithm used to compute extracted PLS factors. NIPALS requests the usual iterative NIPALS algorithm, SVD bases the extraction on the singular value decomposition of
 , EIG bases the extraction on the eigenvalue decomposition of
, EIG bases the extraction on the eigenvalue decomposition of 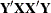 , and RLGW is an iterative approach that is efficient when there are many predictors. ALGORITHM=SVD is the most accurate but
least efficient approach; the default is ALGORITHM=NIPALS.
, and RLGW is an iterative approach that is efficient when there are many predictors. ALGORITHM=SVD is the most accurate but
least efficient approach; the default is ALGORITHM=NIPALS.
- MAXITER=n
-
specifies the maximum number of iterations for the NIPALS and RLGW algorithms. The default value is 200.
- EPSILON=n
-
specifies the convergence criterion for the NIPALS and RLGW algorithms. The default value is
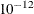 .
.
-
MISSING=NONE
MISSING=AVG
MISSING=EM <( EM-options )> -
specifies how observations with missing values are to be handled in computing the fit. The default is MISSING=NONE, for which observations with any missing variables (dependent or independent) are excluded from the analysis. MISSING=AVG specifies that the fit be computed by filling in missing values with the average of the nonmissing values for the corresponding variable. If you specify MISSING=EM, then the procedure first computes the model with MISSING=AVG and then fills in missing values by their predicted values based on that model and computes the model again. For both methods of imputation, the imputed values contribute to the centering and scaling values, and the difference between the imputed values and their final predictions contributes to the percentage of variation explained. You can also specify the following optional EM-options in parentheses after MISSING=EM:
- MAXITER=n
-
specifies the maximum number of iterations for the imputation/fit loop. The default value is 1. If you specify a large value of MAXITER=, then the loop will iterate until it converges (as controlled by the EPSILON= option).
- EPSILON=n
-
specifies the convergence criterion for the imputation/fit loop. The default value is
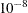 . This option is effective only if you specify a large value for the MAXITER= option.
. This option is effective only if you specify a large value for the MAXITER= option.
- NFAC=n
-
specifies the number of factors to extract. The default is
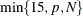 , where p is the number of predictors (the number of dependent variables for METHOD=RRR) and N is the number of runs (observations). This is probably more than you need for most applications. Extracting too many factors
can lead to an overfit model, one that matches the training data too well, sacrificing predictive ability. Thus, if you use
the default NFAC= specification, you should also either use the CV= option to select the appropriate number of factors for
the final model or consider the analysis to be preliminary and examine the results to determine the appropriate number of
factors for a subsequent analysis.
, where p is the number of predictors (the number of dependent variables for METHOD=RRR) and N is the number of runs (observations). This is probably more than you need for most applications. Extracting too many factors
can lead to an overfit model, one that matches the training data too well, sacrificing predictive ability. Thus, if you use
the default NFAC= specification, you should also either use the CV= option to select the appropriate number of factors for
the final model or consider the analysis to be preliminary and examine the results to determine the appropriate number of
factors for a subsequent analysis.
- NOCENTER
-
suppresses centering of the responses and predictors before fitting. This is useful if the analysis variables are already centered and scaled. See the section Centering and Scaling for more information.
- NOCVSTDIZE
-
suppresses re-centering and rescaling of the responses and predictors before each model is fit in the cross validation. See the section Centering and Scaling for more information.
- NOPRINT
-
suppresses the normal display of results. This is useful when you want only the output statistics saved in a data set. Note that this option temporarily disables the Output Delivery System (ODS); see Chapter 20: Using the Output Delivery System, for more information.
- NOSCALE
-
suppresses scaling of the responses and predictors before fitting. This is useful if the analysis variables are already centered and scaled. See the section Centering and Scaling for more information.
-
PLOTS <(global-plot-options)> <= plot-request <(options)>>
PLOTS <(global-plot-options)> <= (plot-request <(options)> <... plot-request <(options)>>)> -
controls the plots produced through ODS Graphics. When you specify only one plot request, you can omit the parentheses from around the plot request. For example:
plots=none plots=cvplot plots=(diagnostics cvplot) plots(unpack)=diagnostics plots(unpack)=(diagnostics corrload(trace=off))
ODS Graphics must be enabled before plots can be requested. For example:
ods graphics on; proc pls data=pentaTrain; model log_RAI = S1-S5 L1-L5 P1-P5; run; ods graphics off;
For more information about enabling and disabling ODS Graphics, see the section Enabling and Disabling ODS Graphics in Chapter 21: Statistical Graphics Using ODS.
If ODS Graphics is enabled but you do not specify the PLOTS= option, then PROC PLS produces by default a plot of the R-square analysis and a correlation loading plot summarizing the first two factors.
The global plot options include the following:
The plot requests include the following:
- VARSCALE
-
specifies that continuous model variables be centered and scaled prior to centering and scaling the model effects in which they are involved. The rescaling specified by the VARSCALE option is sometimes more appropriate if the model involves crossproducts between model variables; however, the VARSCALE option still might not produce the model you expect. See the section Centering and Scaling for more information.
- VARSS
-
lists, in addition to the average response and predictor sum of squares accounted for by each successive factor, the amount of variation accounted for in each response and predictor.