The VARIOGRAM Procedure

Autocorrelation Weights
In general, the choice of a weighting scheme is subjective. You can obtain different results by using different schemes, options, and parameters. PROC VARIOGRAM offers you considerable flexibility in choosing weights that are appropriate for prior considerations such as different hypotheses about neighboring areas, definition of the neighborhood structure, and accounting for natural barriers or other spatial characteristics; see the discussion in Cliff and Ord (1981, p. 17). As stressed for all types of spatial analysis, it is important to have good knowledge of your data. In the autocorrelation statistics, this knowledge can help you avoid spurious correlations when you choose the weights.
The starting point is to assign individual weights to each one of the  data values
data values  ,
, 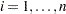 , with respect to the rest. An
, with respect to the rest. An 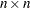 matrix of weights is thus defined, such that for any two locations
matrix of weights is thus defined, such that for any two locations 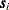 and
and 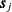 , the weight
, the weight 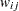 denotes the effect of the value at location on the value
denotes the effect of the value at location on the value 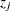 at location . Depending on the nature of your study, the weights need not be symmetric; that is, it can be true that
at location . Depending on the nature of your study, the weights need not be symmetric; that is, it can be true that 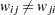 .
.
Binary and Nonbinary Weights
The weights can be either binary or nonbinary values. Binary values of 1 or 0 are assigned if the SRF 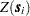 at one location is deemed to be connected or not, respectively, to its value
at one location is deemed to be connected or not, respectively, to its value 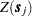 at another location . Nonbinary values can be used in the presence of more refined measures of connectivity between any two data points
at another location . Nonbinary values can be used in the presence of more refined measures of connectivity between any two data points 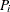 and
and 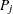 . PROC VARIOGRAM offers a choice between a binary and a distance-based nonbinary weighting scheme.
. PROC VARIOGRAM offers a choice between a binary and a distance-based nonbinary weighting scheme.
In the binary weighting scheme the weight 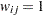 if the data pair at and is closer than the user-defined distance that is defined by the LAGDISTANCE= option, and
if the data pair at and is closer than the user-defined distance that is defined by the LAGDISTANCE= option, and 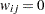 if
if 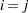 or in any other case. For that reason, in the COMPUTE statement, if you specify the WEIGHTS=BINARY suboption of the AUTOCORRELATION option when the NOVARIOGRAM option is also specified, then you must also specify the LAGDISTANCE= option.
or in any other case. For that reason, in the COMPUTE statement, if you specify the WEIGHTS=BINARY suboption of the AUTOCORRELATION option when the NOVARIOGRAM option is also specified, then you must also specify the LAGDISTANCE= option.
The nonbinary weighting scheme is based on the pair distances and is invoked with the WEIGHTS=DISTANCE suboption of the AUTOCORRELATION option. PROC VARIOGRAM uses a variation of the Pareto form functional to set the weights. Namely, the autocorrelation weight for every point pair and located at and , respectively, is defined as
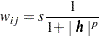 |
where 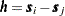 and
and 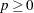 and
and 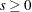 are user-defined parameters for the adjustment of the weights.
are user-defined parameters for the adjustment of the weights.
In particular, the power parameter 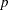 is specified in the POWER= option of the DISTANCE suboption within the AUTOCORRELATION option. The default value for this parameter is
is specified in the POWER= option of the DISTANCE suboption within the AUTOCORRELATION option. The default value for this parameter is 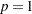 . Also, the scaling parameter
. Also, the scaling parameter  is specified by the SCALE= option in the DISTANCE suboption of the AUTOCORRELATION option. The default value for the scaling parameter is
is specified by the SCALE= option in the DISTANCE suboption of the AUTOCORRELATION option. The default value for the scaling parameter is 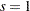 . You can use the and parameters to adjust the actual values of the weights according to your needs. Variations in the scaling parameter do not affect the computed values of the Moran’s
. You can use the and parameters to adjust the actual values of the weights according to your needs. Variations in the scaling parameter do not affect the computed values of the Moran’s 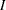 and Geary’s
and Geary’s  autocorrelation coefficients that are introduced in the section Autocorrelation Statistics Types.
autocorrelation coefficients that are introduced in the section Autocorrelation Statistics Types.
Nonbinary Weights with Normalized Distances
PROC VARIOGRAM offers additional flexibility in the DISTANCE weighting scheme through an option to use normalized pair distances. You can invoke this feature by specifying the NORMALIZE option in the DISTANCE suboption of the AUTOCORRELATION option. In this case, the distances used in the definition of the weights are normalized by the maximum pairwise distance 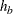 (see the section Computation of the Distribution Distance Classes and Figure 98.24); the weights are then defined as
(see the section Computation of the Distribution Distance Classes and Figure 98.24); the weights are then defined as 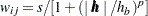 .
.
Most likely, has a different value for different data sets. Hence, it is suggested that you avoid using the weights you obtain from the preceding equation and one data set for comparisons with the weights you derive from different data sets.
Symmetric and Asymmetric Weights
The weighting schemes presented in the preceding paragraphs are symmetric; that is, 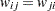 for every data pair at locations and . However, you can also define asymmetric weights
for every data pair at locations and . However, you can also define asymmetric weights 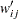 such that
such that
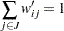 |
for 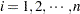 , where
, where 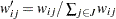 , . In the distance-based scheme,
, . In the distance-based scheme, 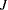 is the set of all locations that form point pairs with the point at . In the binary scheme, is the set of the locations that are connected to based on your selection of the LAGDISTANCE= option; see Cliff and Ord (1981, p. 18). The weights are row-averaged (or standardized by the count of their connected neighbors). You can apply row averaging in weights when you specify the ROWAVG option within either the BINARY or DISTANCE suboptions in the AUTOCORRELATION option.
is the set of all locations that form point pairs with the point at . In the binary scheme, is the set of the locations that are connected to based on your selection of the LAGDISTANCE= option; see Cliff and Ord (1981, p. 18). The weights are row-averaged (or standardized by the count of their connected neighbors). You can apply row averaging in weights when you specify the ROWAVG option within either the BINARY or DISTANCE suboptions in the AUTOCORRELATION option.