The NLIN Procedure
- Overview
-
Getting Started

-
Syntax
-
Details
Automatic Derivatives Measures of Nonlinearity and Diagnostics Missing Values Special Variables Troubleshooting Computational Methods Output Data Sets Confidence Intervals Covariance Matrix of Parameter Estimates Convergence Measures Displayed Output Incompatibilities with SAS 6.11 and Earlier Versions of PROC NLIN ODS Table Names ODS Graphics
-
Examples
- References
| Measures of Nonlinearity and Diagnostics |
A "close-to-linear" nonlinear regression model, in the sense of Ratkowsky (1983, 1990), is a model in which parameter estimators have properties similar to those in a linear regression model. That is, the least squares estimators of the parameters are close to being unbiased and normally distributed, and they have minimum variance.
A nonlinear regression model sometimes fails to be close to linear due to the properties of one or several parameters. When this occurs, bias in the parameter estimates can render inferences that use the reported standard errors and confidence limits invalid.
PROC NLIN provides various measures of nonlinearity. To assess the nonlinearity of a model-data combination, you can use both of the following complementary sets of measures:
Box’s bias (Box 1971) and Hougaard’s skewness (Hougaard 1982, 1985) of the least squares parameter estimates
curvature measures of nonlinearity (Bates and Watts 1980).
Furthermore, PROC NLIN provides residual, leverage, and local-influence diagnostics (St. Laurent and Cook 1993).
In the following several sections, these nonlinearity measures and diagnostics are discussed. For this material, several basic definitions are required. Let 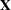 be the Jacobian matrix for the model,
be the Jacobian matrix for the model, 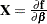 , and let
, and let 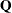 and
and 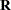 be the components of the QR decomposition of
be the components of the QR decomposition of 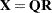 of , where is an
of , where is an 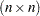 orthogonal matrix. Finally, let
orthogonal matrix. Finally, let 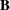 be the inverse of the matrix constructed from the first
be the inverse of the matrix constructed from the first 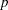 rows of the
rows of the 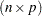 dimensional matrix (that is,
dimensional matrix (that is, 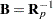 ). Next define
). Next define
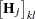 |
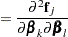 |
|||
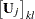 |
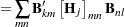 |
|||
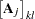 |
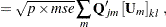 |
where 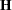 ,
, 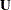 and the acceleration array
and the acceleration array 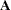 are three-dimensional
are three-dimensional 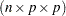 matrices. The first faces of the acceleration array constitute a
matrices. The first faces of the acceleration array constitute a 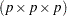 parameteter-effects array and the last
parameteter-effects array and the last 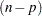 faces constitute the
faces constitute the 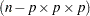 intrinsic curvature array (Bates and Watts 1980). The previous and subsequent quantities are computed at the least squares parameter estimators.
intrinsic curvature array (Bates and Watts 1980). The previous and subsequent quantities are computed at the least squares parameter estimators.
Box’s Measure of Bias
The degree to which parameter estimators exhibit close-to-linear behavior can be assessed with Box’s bias (Box 1971) and Hougaard’s measure of skewness (Hougaard 1982, 1985). The bias and percentage bias measures are available through the BIAS option in the PROC NLIN statement. Box’s bias measure is defined as
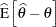 |
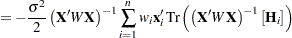 |
where 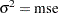 if the SIGSQ option is not set. Otherwise,
if the SIGSQ option is not set. Otherwise, 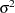 is the value you set with the SIGSQ option.
is the value you set with the SIGSQ option. 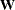 is the diagonal weight matrix specified with the _WEIGHT_ variable (or the identity matrix if _WEIGHT_ is not defined) and
is the diagonal weight matrix specified with the _WEIGHT_ variable (or the identity matrix if _WEIGHT_ is not defined) and 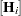 is the
is the 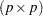 Hessian matrix at the
Hessian matrix at the 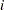 th observation. In the case of unweighted least squares, the bias formula can be expressed in terms of the acceleration array ,
th observation. In the case of unweighted least squares, the bias formula can be expressed in terms of the acceleration array ,
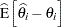 |
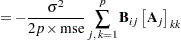 |
As the preceeding formulas illustrate, the bias depends solely on the parameter-effects array, thereby permitting its reduction through reparameterization. Example 62.4 shows how changing the parameterization of a four-parameter logistic model can reduce the bias. Ratkowsky (1983, p. 21) recommends that you consider reparameterization if the percentage bias exceeds 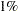 .
.
Hougaard’s Measure of Skewness
In addition to Box’s bias, Hougaard’s measure of skewness, 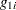 (Hougaard 1982, 1985), is also provided in PROC NLIN to assess the close-to-linear behavior of parameter estimators. This measure is available through the HOUGAARD option in the PROC NLIN statement. Hougaard’s skewness measure for the th parameter is based on the third central moment, defined as
(Hougaard 1982, 1985), is also provided in PROC NLIN to assess the close-to-linear behavior of parameter estimators. This measure is available through the HOUGAARD option in the PROC NLIN statement. Hougaard’s skewness measure for the th parameter is based on the third central moment, defined as
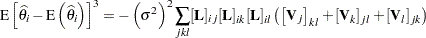 |
where the sum is a triple sum over the number of parameters and
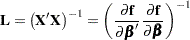 |
The term 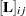 denotes the value in row , column
denotes the value in row , column 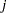 of the matrix
of the matrix 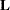 . (Hougaard (1985) uses superscript notation to denote elements in this inverse.) The matrix
. (Hougaard (1985) uses superscript notation to denote elements in this inverse.) The matrix 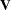 is a three-dimensional array
is a three-dimensional array
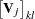 |
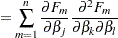 |
The third central moment is then normalized using the standard error as
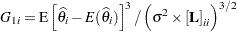 |
The previous expressions depend on the unknown values of the parameters and on the residual variance . In order to evaluate the Hougaard measure in a particular data set, the NLIN procedure computes
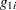 |
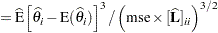 |
|||
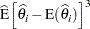 |
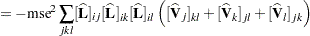 |
Following Ratkowsky (1990, p. 28), the parameter 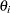 is considered to be very close to linear, reasonably close, skewed, or quite nonlinear according to the absolute value of the Hougaard measure
is considered to be very close to linear, reasonably close, skewed, or quite nonlinear according to the absolute value of the Hougaard measure 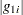 being less than 0.1, between 0.1 and 0.25, between 0.25 and 1, or greater than 1, respectively.
being less than 0.1, between 0.1 and 0.25, between 0.25 and 1, or greater than 1, respectively.
Relative Curvature Measures of Nonlinearity
Bates and Watts (1980) formulated the maximum parameter-effects and maximum intrinsic curvature measures of nonlinearity to assess the close-to-linear behavior of nonlinear models. Ratkowsky (1990) notes that of the two curvature components in a nonlinear model, the parameter-effects curvature is typically larger. It is this component that you can affect by changing the parameterization of a model. PROC NLIN provides these two measures of curvature both through the STATS plot-option and through the NLINMEASURES option in the PROC NLIN statement.
The maximum parameter-effects and intrinsic curvatures are defined, in a compact form, as
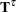 |
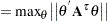 |
|||
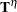 |
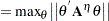 |
where 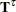 and
and 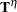 denote the maximum parameter-effects and intrinsic curvatures, while
denote the maximum parameter-effects and intrinsic curvatures, while 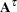 and
and 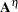 stand for the parameter-effects and intrinsic curvature arrays. The maximization is carried out over a unit-vector of the parameter values (Bates and Watts 1980). In line with Bates and Watts (1980), PROC NLIN takes
stand for the parameter-effects and intrinsic curvature arrays. The maximization is carried out over a unit-vector of the parameter values (Bates and Watts 1980). In line with Bates and Watts (1980), PROC NLIN takes 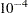 as the convergence tolerance for the maximum intrinsic and parameter-effects curvatures. Note that the preceeding matrix products involve contraction of the faces of the three-dimensional acceleration arrays with the normalized parameter vector,
as the convergence tolerance for the maximum intrinsic and parameter-effects curvatures. Note that the preceeding matrix products involve contraction of the faces of the three-dimensional acceleration arrays with the normalized parameter vector, 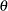 . The corresponding expressions for the RMS (root mean square) parameter-effects and intrinsic curvatures can be found in Bates and Watts (1980).
. The corresponding expressions for the RMS (root mean square) parameter-effects and intrinsic curvatures can be found in Bates and Watts (1980).
The statistical significance of and and the corresponding RMS values can be assessed by comparing these values with 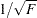 , where
, where 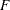 is the upper
is the upper 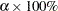 quantile of an distribution with and
quantile of an distribution with and 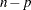 degrees of freedom (Bates and Watts 1980).
degrees of freedom (Bates and Watts 1980).
One motivation for fitting a nonlinear model in a different parameterization is to obtain a particular interpretation and to give parameter estimators more close-to-linear behavior. Example 62.4 shows how changing the parameterization of a four-parameter logistic model can reduce the parameter-effects curvature and can yield a useful parameter interpretation at the same time. In addition, Example 62.6 shows a nonlinear model with a high intrinsic curvature and the corresponding diagnostics.
Leverage in Nonlinear Regression
In contrast to linear regression, there are several measures of leverage in nonlinear regression. Furthermore, in nonlinear regression, the effect of a change in the th response on the th predicted value might depend on both the size of the change and the th response itself (St. Laurent and Cook 1992). As a result, some observations might show superleverage —namely, leverages in excess of one (St. Laurent and Cook 1992).
PROC NLIN provides two measures of leverages: tangential and Jacobian leverages through the PLOTS option in the PROC NLIN statement and the H= and J= options of OUTPUT statement. Tangential leverage, 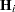 , is based on approximating the nonlinear model with a linear model that parameterizes the tangent plane at the least squares parameter estimators. In contrast, Jacobian leverage,
, is based on approximating the nonlinear model with a linear model that parameterizes the tangent plane at the least squares parameter estimators. In contrast, Jacobian leverage, 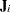 , is simply defined as the instantaneous rate of change in the th predicted value with respect to the th response (St. Laurent and Cook 1992).
, is simply defined as the instantaneous rate of change in the th predicted value with respect to the th response (St. Laurent and Cook 1992).
The mathematical formulas for tangential and Jacobian leverages are
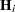 |
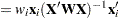 |
|||
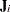 |
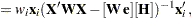 |
where  is the vector of residuals, is the diagonal weight matrix if you specify the special variable _WEIGHT_ and otherwise the identity matrix, and indexes the corresponding quantities for the th observation. The brackets
is the vector of residuals, is the diagonal weight matrix if you specify the special variable _WEIGHT_ and otherwise the identity matrix, and indexes the corresponding quantities for the th observation. The brackets 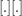 indicate column multiplication as defined in Bates and Watts (1980). The preceeding formula for tangential leverage holds if the gradient, Marquardt, or Gauss methods are used. For the Newton method, the tangential leverage is set equal to the Jacobian leverage.
indicate column multiplication as defined in Bates and Watts (1980). The preceeding formula for tangential leverage holds if the gradient, Marquardt, or Gauss methods are used. For the Newton method, the tangential leverage is set equal to the Jacobian leverage.
In a model with a large intrinsic curvature, the Jacobian and tangential leverages can be very different. In fact, the two leverages are identical only if the model provides an exact fit to the data (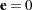 ) or the model is intrinsically linear (St. Laurent and Cook 1993). This is also illustrated by the leverage plot and nonlinearity measures provided in Example 62.6.
) or the model is intrinsically linear (St. Laurent and Cook 1993). This is also illustrated by the leverage plot and nonlinearity measures provided in Example 62.6.
Local Influence in Nonlinear Regression
St. Laurent and Cook (1993) suggest using 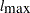 , the direction that yields the maximum normal curvature, to assess the local influence of an additive perturbation to the response variable on the estimation of the parameters and variance of a nonlinear model. Defining the normal curvature components
, the direction that yields the maximum normal curvature, to assess the local influence of an additive perturbation to the response variable on the estimation of the parameters and variance of a nonlinear model. Defining the normal curvature components
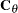 |
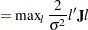 |
|||
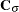 |
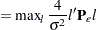 |
where 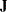 is the Jacobian leverage matrix and
is the Jacobian leverage matrix and 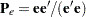 , you choose the that results in the maximum of the two curvature components (St. Laurent and Cook 1993). PROC NLIN provides through the PLOTS option in the PROC NLIN statement and the LMAX= option in the OUTPUT statement. Example 62.6 shows a plot of for a model with high intrinsic curvature.
, you choose the that results in the maximum of the two curvature components (St. Laurent and Cook 1993). PROC NLIN provides through the PLOTS option in the PROC NLIN statement and the LMAX= option in the OUTPUT statement. Example 62.6 shows a plot of for a model with high intrinsic curvature.
Residuals in Nonlinear Regression
If a nonlinear model is intrinsically nonlinear, using the residuals 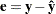 for diagnostics can be misleading (Cook and Tsai 1985). This is due to the fact that in correctly specified intrinsically nonlinear models, the residuals have nonzero means and different variances, even when the original error terms have identical variances. Furthermore, the covariance between the residuals and the predicted values tends to be negative semidefinite, complicating the interpretation of plots based on (Cook and Tsai 1985).
for diagnostics can be misleading (Cook and Tsai 1985). This is due to the fact that in correctly specified intrinsically nonlinear models, the residuals have nonzero means and different variances, even when the original error terms have identical variances. Furthermore, the covariance between the residuals and the predicted values tends to be negative semidefinite, complicating the interpretation of plots based on (Cook and Tsai 1985).
Projected residuals are proposed by Cook and Tsai (1985) to overcome these shortcomings of residuals, which are henceforth called raw (ordinary) residuals to differentiate them from their projected counterparts. Projected residuals have zero means and are uncorrelated with the predicted values. In fact, projected residuals are identical to the raw residuals in intrinsically linear models.
PROC NLIN provides raw and projected residuals, along with their standardized forms. In addition, the mean or expectation of the raw residuals is available. These can be accessed with the PLOTS option in the PROC NLIN statement and the OUTPUT statement options PROJRES=, PROJSTUDENT=, RESEXPEC=, RESIDUAL= and STUDENT=.
Denote the projected residuals by 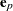 and the expectation of the raw residuals by
and the expectation of the raw residuals by 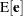 . Then
. Then
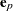 |
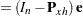 |
|||
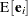 |
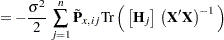 |
where 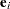 is the th observation raw residual,
is the th observation raw residual, 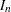 is an n-dimensional identity matrix,
is an n-dimensional identity matrix, 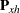 is the projector onto the column space of
is the projector onto the column space of 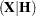 , and
, and 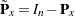 . The preceeding formulas are general with the projectors defined accordingly to take the weighting into consideration. In unweighted least squares,
. The preceeding formulas are general with the projectors defined accordingly to take the weighting into consideration. In unweighted least squares, 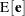 reduces to
reduces to
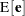 |
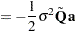 |
with 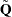 being the last columns of the matrix in the QR decomposition of
being the last columns of the matrix in the QR decomposition of 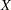 and the dimensional vector
and the dimensional vector  being defined in terms of the intrinsic acceleration array
being defined in terms of the intrinsic acceleration array
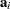 |
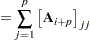 |
Standardization of the projected residuals requires the variance of the projected residuals. This is estimated using the formula (Cook and Tsai 1985)
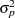 |
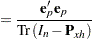 |
The standardized raw and projected residuals, denoted by 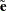 and
and 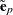 respectively, are given by
respectively, are given by
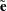 |
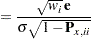 |
|||
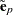 |
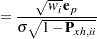 |
The use of raw and projected residuals for diagnostics in nonlinear regression is illustrated in Example 62.6.