The GLIMMIX Procedure
-
Overview

-
Getting Started
-
Syntax
PROC GLIMMIX Statement BY Statement CLASS Statement CONTRAST Statement COVTEST Statement EFFECT Statement ESTIMATE Statement FREQ Statement ID Statement LSMEANS Statement LSMESTIMATE Statement MODEL Statement NLOPTIONS Statement OUTPUT Statement PARMS Statement RANDOM Statement SLICE Statement STORE Statement WEIGHT Statement Programming Statements User-Defined Link or Variance Function
-
Details
Generalized Linear Models Theory Generalized Linear Mixed Models Theory GLM Mode or GLMM Mode Statistical Inference for Covariance Parameters Satterthwaite Degrees of Freedom Approximation Empirical Covariance (Sandwich) Estimators Exploring and Comparing Covariance Matrices Processing by Subjects Radial Smoothing Based on Mixed Models Odds and Odds Ratio Estimation Parameterization of Generalized Linear Mixed Models Response-Level Ordering and Referencing Comparing the GLIMMIX and MIXED Procedures Singly or Doubly Iterative Fitting Default Estimation Techniques Default Output Notes on Output Statistics ODS Table Names ODS Graphics
-
Examples
Binomial Counts in Randomized Blocks Mating Experiment with Crossed Random Effects Smoothing Disease Rates; Standardized Mortality Ratios Quasi-likelihood Estimation for Proportions with Unknown Distribution Joint Modeling of Binary and Count Data Radial Smoothing of Repeated Measures Data Isotonic Contrasts for Ordered Alternatives Adjusted Covariance Matrices of Fixed Effects Testing Equality of Covariance and Correlation Matrices Multiple Trends Correspond to Multiple Extrema in Profile Likelihoods Maximum Likelihood in Proportional Odds Model with Random Effects Fitting a Marginal (GEE-Type) Model Response Surface Comparisons with Multiplicity Adjustments Generalized Poisson Mixed Model for Overdispersed Count Data Comparing Multiple B-Splines Diallel Experiment with Multimember Random Effects Linear Inference Based on Summary Data
- References
Fit Statistics
The "Fit Statistics" table provides statistics about the estimated model. The first entry of the table corresponds to the negative of twice the (possibly restricted) log likelihood, log pseudo-likelihood, or log quasi-likelihood. If the estimation method permits the true log likelihood or residual log likelihood, the description of the first entry reads accordingly. Otherwise, the fit statistics are preceded by the words Pseudo- or Quasi-, for Pseudo- and Quasi-Likelihood estimation, respectively.
Note that the (residual) log pseudo-likelihood in a GLMM is the (residual) log likelihood of a linearized model. You should not compare these values across different statistical models, even if the models are nested with respect to fixed and/or G-side random effects. It is possible that between two nested models the larger model has a smaller pseudo-likelihood. For this reason, IC=NONE is the default for GLMMs fit by pseudo-likelihood methods.
See the IC= option of the PROC GLIMMIX statement and Table 40.2 for the definition and computation of the information criteria reported in the "Fit Statistics" table.
For generalized linear models, the GLIMMIX procedure reports Pearson’s chi-square statistic
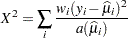 |
where 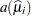 is the variance function evaluated at the estimated mean.
is the variance function evaluated at the estimated mean.
For GLMMs, the procedure typically reports a generalized chi-square statistic,
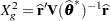 |
so that the ratio of 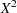 or
or 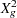 and the degrees of freedom produces the usual residual dispersion estimate.
and the degrees of freedom produces the usual residual dispersion estimate.
If the R-side scale parameter 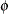 is not extracted from
is not extracted from  , the GLIMMIX procedure computes
, the GLIMMIX procedure computes
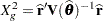 |
as the generalized chi-square statistic. This is the case, for example, if R-side covariance structures are varied by a GROUP= effect or if the scale parameter is not profiled for an R-side TYPE=CS, TYPE=SP, TYPE=AR, TYPE=TOEP, or TYPE=ARMA covariance structure.
For METHOD=LAPLACE, the generalized chi-square statistic is not reported. Instead, the Pearson statistic for the conditional distribution appears in the "Conditional Fit Statistics" table.
If your model contains smooth components (such as TYPE=RSMOOTH), then the "Fit Statistics" table also displays the residual degrees of freedom of the smoother. These degrees of freedom are computed as
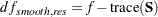 |
where 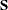 is the "smoother" matrix—that is, the matrix that produces the predicted values on the linked scale.
is the "smoother" matrix—that is, the matrix that produces the predicted values on the linked scale.
For ODS purposes, the name of the "Fit Statistics" table is "FitStatistics."