The GLIMMIX Procedure
-
Overview

-
Getting Started
-
Syntax
PROC GLIMMIX Statement BY Statement CLASS Statement CONTRAST Statement COVTEST Statement EFFECT Statement ESTIMATE Statement FREQ Statement ID Statement LSMEANS Statement LSMESTIMATE Statement MODEL Statement NLOPTIONS Statement OUTPUT Statement PARMS Statement RANDOM Statement SLICE Statement STORE Statement WEIGHT Statement Programming Statements User-Defined Link or Variance Function
-
Details
Generalized Linear Models Theory Generalized Linear Mixed Models Theory GLM Mode or GLMM Mode Statistical Inference for Covariance Parameters Satterthwaite Degrees of Freedom Approximation Empirical Covariance (Sandwich) Estimators Exploring and Comparing Covariance Matrices Processing by Subjects Radial Smoothing Based on Mixed Models Odds and Odds Ratio Estimation Parameterization of Generalized Linear Mixed Models Response-Level Ordering and Referencing Comparing the GLIMMIX and MIXED Procedures Singly or Doubly Iterative Fitting Default Estimation Techniques Default Output Notes on Output Statistics ODS Table Names ODS Graphics
-
Examples
Binomial Counts in Randomized Blocks Mating Experiment with Crossed Random Effects Smoothing Disease Rates; Standardized Mortality Ratios Quasi-likelihood Estimation for Proportions with Unknown Distribution Joint Modeling of Binary and Count Data Radial Smoothing of Repeated Measures Data Isotonic Contrasts for Ordered Alternatives Adjusted Covariance Matrices of Fixed Effects Testing Equality of Covariance and Correlation Matrices Multiple Trends Correspond to Multiple Extrema in Profile Likelihoods Maximum Likelihood in Proportional Odds Model with Random Effects Fitting a Marginal (GEE-Type) Model Response Surface Comparisons with Multiplicity Adjustments Generalized Poisson Mixed Model for Overdispersed Count Data Comparing Multiple B-Splines Diallel Experiment with Multimember Random Effects Linear Inference Based on Summary Data
- References
Quasi-likelihood for Independent Data
Quasi-likelihood estimation uses only the first and second moment of the response. In the case of independent data, this requires only a specification of the mean and variance of your data. The GLIMMIX procedure estimates parameters by quasi-likelihood, if the following conditions are met:
The response distribution is unknown, because of a user-specified variance function.
There are no G-side random effects.
There are no R-side covariance structures or at most an overdispersion parameter.
Under some mild regularity conditions, the function
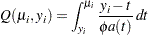 |
known as the log quasi-likelihood of the 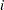 th observation, has some properties of a log-likelihood function (McCullagh and Nelder 1989, p. 325). For example, the expected value of its derivative is zero, and the variance of its derivative equals the negative of the expected value of the second derivative. Consequently,
th observation, has some properties of a log-likelihood function (McCullagh and Nelder 1989, p. 325). For example, the expected value of its derivative is zero, and the variance of its derivative equals the negative of the expected value of the second derivative. Consequently,
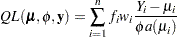 |
can serve as the score function for estimation. Quasi-likelihood estimation takes as the gradient and "Hessian" matrix—with respect to the fixed-effects parameters 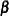 —the quantities
—the quantities
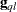 |
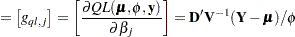 |
|||
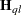 |
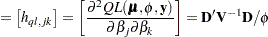 |
In this expression, 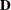 is a matrix of derivatives of
is a matrix of derivatives of 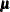 with respect to the elements in , and
with respect to the elements in , and 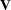 is a diagonal matrix containing variance functions,
is a diagonal matrix containing variance functions, 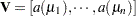 . Notice that
. Notice that 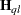 is not the second derivative matrix of
is not the second derivative matrix of 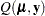 . Rather, it is the negative of the expected value of
. Rather, it is the negative of the expected value of 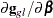 . thus has the form of a "scoring Hessian."
. thus has the form of a "scoring Hessian."
The GLIMMIX procedure fixes the scale parameter 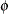 at 1.0 by default. To estimate the parameter, add the statement
at 1.0 by default. To estimate the parameter, add the statement
random _residual_;
The resulting estimator (McCullagh and Nelder 1989, p. 328) is
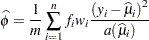 |
where 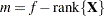 if the NOREML option is in effect,
if the NOREML option is in effect, 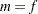 otherwise, and
otherwise, and 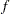 is the sum of the frequencies.
is the sum of the frequencies.
See Example 40.4 for an application of quasi-likelihood estimation with PROC GLIMMIX.