BOXCHART Statement: SHEWHART Procedure
- Overview
-
Getting Started

-
Syntax
-
Details
-
ExamplesUsing Box Charts to Compare SubgroupsCreating Various Styles of Box-and-Whisker PlotsCreating Notched Box-and-Whisker PlotsCreating Box-and-Whisker Plots with Varying WidthsCreating Box-and-Whisker Plots with Different Line Styles and ColorsComputing the Control Limits for Subgroup MaximumsConstructing Multi-Vari Charts
Methods for Estimating the Standard Deviation
When control limits are computed from the input data, three methods (referred to as default, MVLUE and RMSDF) are available
for estimating the process standard deviation  . The method depends on whether you specify the RANGES
option. If you specify this option, is estimated using subgroup ranges; otherwise, is estimated using subgroup standard deviations.
. The method depends on whether you specify the RANGES
option. If you specify this option, is estimated using subgroup ranges; otherwise, is estimated using subgroup standard deviations.
Default Method Based on Subgroup Standard Deviations
If you do not specify the RANGES option, the default estimate for is
![\[ \hat{\sigma } = \frac{s_{1}/c_{4}(n_{1})+ \cdots + s_{N}/c_{4}(n_{N})}{N} \]](images/qcug_shewhart0056.png)
where N is the number of subgroups for which 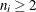 ,
,  is the sample standard deviation of the ith subgroup
is the sample standard deviation of the ith subgroup
![\[ s_{i} = \sqrt { \frac{1}{n_{i} - 1} \sum ^{n_ i}_{j=1}(x_{ij}-\bar{X}_{i})^{2}} \]](images/qcug_shewhart0059.png)
and
![\[ c_{4}(n_{i}) = \frac{\Gamma (n_{i}/2)\sqrt {2/(n_{i}-1)}}{\Gamma ((n_{i}-1)/2)} \]](images/qcug_shewhart0060.png)
Here 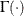 denotes the gamma function, and
denotes the gamma function, and 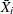 denotes the ith subgroup mean. A subgroup standard deviation is included in the calculation only if . If the observations are normally distributed, the expected value of is
denotes the ith subgroup mean. A subgroup standard deviation is included in the calculation only if . If the observations are normally distributed, the expected value of is 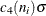 . Thus,
. Thus, 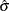 is the unweighted average of N unbiased estimates of . This method is described in the American Society for Testing and Materials (1976).
is the unweighted average of N unbiased estimates of . This method is described in the American Society for Testing and Materials (1976).
Default Method Based on Subgroup Ranges
If you specify the RANGES option, the default estimate for is
![\[ \hat{\sigma } = \frac{R_{1}/d_{2}(n_{1})+ \cdots + R_{N}/d_{2}(n_{N})}{N} \]](images/qcug_shewhart0063.png)
where N is the number of subgroups for which 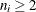 , and
, and 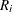 is the sample range of the observations
is the sample range of the observations 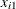 , . . . ,
, . . . ,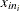 in the ith subgroup.
in the ith subgroup.
![\[ R_{i} = \max _{1 \leq j \leq n_{i}}(x_{ij}) - \min _{1 \leq j \leq n_{i}}(x_{ij}) \]](images/qcug_shewhart0068.png)
A subgroup range 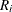 is included in the calculation only if . The unbiasing factor
is included in the calculation only if . The unbiasing factor 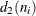 is defined so that, if the observations are normally distributed, the expected value of is
is defined so that, if the observations are normally distributed, the expected value of is 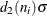 . Thus, is the unweighted average of N unbiased estimates of . This method is described in the American Society for Testing and Materials (1976).
. Thus, is the unweighted average of N unbiased estimates of . This method is described in the American Society for Testing and Materials (1976).
MVLUE Method Based on Subgroup Standard Deviations
If you do not specify the RANGES option and specify SMETHOD=
MVLUE, a minimum variance linear unbiased estimate (MVLUE) is computed for . Refer to Burr (1969, 1976) and Nelson (1989, 1994). This estimate is a weighted average of N unbiased estimates of of the form 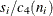 , and it is computed as
, and it is computed as
![\[ \hat{\sigma } = \frac{h_{1}s_{1}/c_{4}(n_{1})+ \cdots + h_{N}s_{N}/c_{4}(n_{N})}{h_1 + \cdots + h_ N} \]](images/qcug_shewhart0073.png)
where
![\[ h_ i = \frac{[c_4(n_ i)]^{2}}{1 - [c_4(n_ i)]^{2}} \]](images/qcug_shewhart0074.png)
A subgroup standard deviation  is included in the calculation only if , and N is the number of subgroups for which . The MVLUE assigns greater weight to estimates of from subgroups with larger sample sizes, and it is intended for situations where the subgroup sample sizes vary. If the subgroup
sample sizes are constant, the MVLUE reduces to the default estimate.
is included in the calculation only if , and N is the number of subgroups for which . The MVLUE assigns greater weight to estimates of from subgroups with larger sample sizes, and it is intended for situations where the subgroup sample sizes vary. If the subgroup
sample sizes are constant, the MVLUE reduces to the default estimate.
MVLUE Method Based on Subgroup Ranges
If you specify the RANGES option and SMETHOD=MVLUE, a minimum variance linear unbiased estimate (MVLUE) is computed for . Refer to Burr (1969, 1976) and Nelson (1989, 1994). The MVLUE is a weighted average of N unbiased estimates of of the form 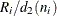 , and it is computed as
, and it is computed as
![\[ \hat{\sigma } = \frac{f_{1}R_{1}/d_{2}(n_{1})+ \cdots + f_{N}R_{N}/d_{2}(n_{N})}{f_1 + \cdots + f_ N} \]](images/qcug_shewhart0077.png)
where
![\[ f_ i = \frac{[d_2(n_ i)]^{2}}{[d_3(n_ i)]^{2}} \]](images/qcug_shewhart0078.png)
A subgroup range is included in the calculation only if , and N is the number of subgroups for which 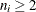 . The unbiasing factor
. The unbiasing factor 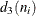 is defined so that, if the observations are normally distributed, the expected value of
is defined so that, if the observations are normally distributed, the expected value of 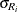 is
is 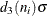 . The MVLUE assigns greater weight to estimates of from subgroups with larger sample sizes, and it is intended for situations where the subgroup sample sizes vary. If the subgroup
sample sizes are constant, the MVLUE reduces to the default estimate.
. The MVLUE assigns greater weight to estimates of from subgroups with larger sample sizes, and it is intended for situations where the subgroup sample sizes vary. If the subgroup
sample sizes are constant, the MVLUE reduces to the default estimate.
RMSDF Method Based on Subgroup Standard Deviations
If you do not specify the RANGES option and specify SMETHOD=RMSDF, a weighted root-mean-square estimate is computed for :
![\[ \hat{\sigma } = \frac{\sqrt {(n_{1} - 1)s_1^{2} + \cdots + (n_{N} - 1)s_{N}^{2}}}{c_{4}(n)\sqrt {n_{1} + \cdots + n_{N} - N}} \]](images/qcug_shewhart0083.png)
where 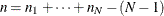 . The weights are the degrees of freedom
. The weights are the degrees of freedom 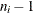 . A subgroup standard deviation is included in the calculation only if , and N is the number of subgroups for which .
. A subgroup standard deviation is included in the calculation only if , and N is the number of subgroups for which .
If the unknown standard deviation is constant across subgroups, the root-mean-square estimate is more efficient than the minimum variance linear unbiased estimate.
However, in process control applications, it is generally not assumed that is constant, and if varies across subgroups, the root-mean-square estimate tends to be more inflated than the MVLUE.