EWMACHART Statement: MACONTROL Procedure

Methods for Estimating the Standard Deviation
When control limits are computed from the input data, four methods are available for estimating the process standard deviation
 . Three methods (referred to as the default, MVLUE, and RMSDF) are available with subgrouped data. A fourth method is used
if the data are individual measurements (see Default Method for Individual Measurements).
. Three methods (referred to as the default, MVLUE, and RMSDF) are available with subgrouped data. A fourth method is used
if the data are individual measurements (see Default Method for Individual Measurements).
Default Method for Subgroup Samples
This method is the default for EWMA charts using subgrouped data. The default estimate of is
![\[ \hat{\sigma }=\frac{s_{1}/c_{4}(n_{1})+\ldots + s_{N}/c_{4}(n_{N})}{N} \]](images/qcug_macontrol0063.png)
where N is the number of subgroups for which  ,
,  is the sample standard deviation of the ith subgroup
is the sample standard deviation of the ith subgroup
![\[ s_{i} = \sqrt { \frac{1}{n_{i} - 1} \sum ^{n_ i}_{j=1}(x_{ij}-\bar{X}_{i})^{2}} \]](images/qcug_macontrol0066.png)
and
![\[ c_{4}(n_{i})=\frac{\Gamma (n_{i}/2)\sqrt {2/(n_{i}-1)} }{\Gamma ((n_{i}-1)/2)} \]](images/qcug_macontrol0067.png)
Here  denotes the gamma function, and
denotes the gamma function, and  denotes the ith subgroup mean. A subgroup standard deviation is included in the calculation only if . If the observations are normally distributed, then the expected value of is
denotes the ith subgroup mean. A subgroup standard deviation is included in the calculation only if . If the observations are normally distributed, then the expected value of is  . Thus,
. Thus, 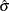 is the unweighted average of N unbiased estimates of . This method is described in the American Society for Testing and Materials (1976).
is the unweighted average of N unbiased estimates of . This method is described in the American Society for Testing and Materials (1976).
MVLUE Method for Subgroup Samples
If you specify SMETHOD=MVLUE, a minimum variance linear unbiased estimate (MVLUE) is computed for . Refer to Burr (1969, 1976) and Nelson (1989, 1994). The MVLUE is a weighted average of N unbiased estimates of of the form  , and it is computed as
, and it is computed as
![\[ \hat{\sigma }=\frac{h_{1}s_{1}/c_{4}(n_{1})+\ldots + h_{N}s_{N}/c_{4}(n_{N})}{h_{1}+\ldots +h_{N}} \]](images/qcug_macontrol0072.png)
where
![\[ h_ i = \frac{[c_4(n_ i)]^{2}}{1 - [c_4(n_ i)]^{2}} \]](images/qcug_macontrol0073.png)
A subgroup standard deviation is included in the calculation only if , and N is the number of subgroups for which . The MVLUE assigns greater weight to estimates of from subgroups with larger sample sizes, and it is intended for situations where the subgroup sample sizes vary. If the subgroup
sample sizes are constant, the MVLUE reduces to the default estimate.
RMSDF Method for Subgroup Samples
If you specify SMETHOD=RMSDF, a weighted root-mean-square estimate is computed for as follows:
![\[ \hat{\sigma } = \frac{\sqrt {(n_{1} - 1)s_1^{2} + \cdots + (n_{N} - 1)s_{N}^{2}}}{c_{4}(n)\sqrt {n_{1} + \cdots + n_{N} - N}} \]](images/qcug_macontrol0074.png)
where  . The weights are the degrees of freedom
. The weights are the degrees of freedom  . A subgroup standard deviation is included in the calculation only if , and N is the number of subgroups for which .
. A subgroup standard deviation is included in the calculation only if , and N is the number of subgroups for which .
If the unknown standard deviation is constant across subgroups, the root-mean-square estimate is more efficient than the minimum variance linear unbiased estimate.
However, in process control applications it is generally not assumed that is constant, and if varies across subgroups, the root-mean-square estimate tends to be more inflated than the MVLUE.
Default Method for Individual Measurements
When each subgroup sample contains a single observation ( ), the process standard deviation is estimated as
), the process standard deviation is estimated as
![\[ \hat{\sigma }=\sqrt {\frac{1}{2(N-1)} \sum _{i=1}^{N-1}{(x_{i+1}-x_{i})^{2}}} \]](images/qcug_macontrol0078.png)
where N is the number of observations, and  are the individual measurements. This formula is given by Wetherill (1977), who states that the estimate of the variance is biased if the measurements are autocorrelated.
are the individual measurements. This formula is given by Wetherill (1977), who states that the estimate of the variance is biased if the measurements are autocorrelated.