OUTPUT Statement: CAPABILITY Procedure

Syntax: OUTPUT Statement
The syntax for the OUTPUT statement is as follows:
-
OUTPUT <OUT=SAS-data-set> <keyword1=names …keywordk=names> <percentile-options>;
You can use any number of OUTPUT statements in the CAPABILITY procedure. Each OUTPUT statement creates a new data set containing the statistics specified in that statement. When you use the OUTPUT statement, you must also use the VAR statement. In addition, the OUTPUT statement must contain at least one of the following:
You can use the OUT= option to specify the name of the output data set:
A keyword=names specification selects a statistic to be included in the output data set and gives names to the new variables that contain the statistics. Specify a keyword for each desired statistic, an equal sign, and the names of the variables to contain the statistic.
In the output data set, the first variable listed after a keyword in the OUTPUT statement contains the statistic for the first variable listed in the VAR statement; the second variable contains the statistic for the second variable in the VAR statement, and so on. The list of names following the equal sign can be shorter than the list of variables in the VAR statement. In this case, the procedure uses the names in the order in which the variables are listed in the VAR statement. Consider the following example:
proc capability noprint; var length width height; output out=summary mean=mlength mwidth; run;
The variables mlength and mwidth contain the means for length and width. The mean for height is computed by the procedure but is not saved in the output data set.
Table 5.52 lists all keywords available in the OUTPUT statement grouped by type. Formulas for selected statistics are given in the section Details: CAPABILITY Procedure.
Table 5.52: OUTPUT Statement Statistic Keywords
|
Keyword |
Description |
|---|---|
|
Descriptive Statistics |
|
|
CSS |
Sum of squares corrected for the mean |
|
CV |
Percent coefficient of variation |
|
GEOMEAN |
Geometric mean |
|
KURTOSIS | KURT |
Kurtosis |
|
MAX |
Largest (maximum) value |
|
MEAN |
Mean |
|
MIN |
Smallest (minimum) value |
|
MODE |
Most frequent value (if not unique, the smallest mode) |
|
N |
Number of observations on which calculations are based |
|
NMISS |
Number of missing values |
|
NOBS |
Number of observations |
|
RANGE |
Range |
|
SKEWNESS | SKEW |
Skewness |
|
STD | STDDEV |
Standard deviation |
|
STDMEAN | STDERR |
Standard error of the mean |
|
SUM |
Sum |
|
SUMWGT |
Sum of weights |
|
USS |
Uncorrected sum of squares |
|
VAR |
Variance |
|
Quantile Statistics |
|
|
MEDIAN | P50 | Q2 |
Median (50th percentile) |
|
P1 |
1st percentile |
|
P5 |
5th percentile |
|
P10 |
10th percentile |
|
P90 |
90th percentile |
|
P95 |
95th percentile |
|
P99 |
99th percentile |
|
Q1 | P25 |
Lower quartile (25th percentile) |
|
Q3 | P75 |
Upper quartile (75th percentile) |
|
QRANGE |
Interquartile range (Q3 – Q1) |
|
Robust Statistics |
|
|
GINI |
Gini’s mean difference |
|
MAD |
Median absolute difference |
|
QN |
2nd variation of median absolute difference |
|
SN |
1st variation of median absolute difference |
|
STD_GINI |
Standard deviation for Gini’s mean difference |
|
STD_MAD |
Standard deviation for median absolute difference |
|
STD_QN |
Standard deviation for the second variation of the median absolute difference |
|
STD_QRANGE |
Estimate of the standard deviation, based on interquartile range |
|
STD_SN |
Standard deviation for the first variation of the median absolute difference |
|
Hypothesis Test Statistics |
|
|
MSIGN |
Sign statistic |
|
NORMAL |
Test statistic for normality. If the sample size is less than or equal to 2000, this is the Shapiro-Wilk W statistic. Otherwise, it is the Kolmogorov D statistic. |
|
PNORMAL | PROBN |
p-value for normality test |
|
PROBM |
Probability of a greater absolute value for the sign statistic |
|
PROBS |
Probability of a greater absolute value for the signed rank statistic |
|
PROBT |
Two-tailed p-value for Student’s t statistic with |
|
SIGNRANK |
Signed rank statistic |
|
T |
Student’s t statistic to test the null hypothesis that the population mean is equal to |
|
Specification Limits and Related Statistics |
|
|
LSL |
Lower specification limit |
|
PCTGTR |
Percent of nonmissing observations greater than |
|
the upper specification limit |
|
|
PCTLSS |
Percent of nonmissing observations less than |
|
the lower specification limit |
|
|
TARGET |
Target value |
|
USL |
Upper specification limit |
|
Capability Indices and Related Statistics |
|
|
CP |
Capability index |
|
CPLCL |
Lower confidence limit for |
|
CPUCL |
Upper confidence limit for |
|
CPK |
Capability index |
|
CPKLCL |
Lower confidence limit for |
|
CPKUCL |
Upper confidence limit for |
|
CPL |
Capability index CPL |
|
CPLLCL |
Lower confidence limit for |
|
CPLUCL |
Upper confidence limit for |
|
CPM |
Capability index |
|
CPMLCL |
Lower confidence limit for |
|
CPMUCL |
Upper confidence limit for |
|
CPU |
Capability index CPU |
|
CPULCL |
Lower confidence limit for |
|
CPUUCL |
Upper confidence limit for |
|
K |
Capability index k (also denoted K) |

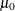
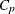
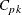
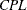
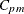
The CAPABILITY procedure automatically computes the 1st, 5th, 10th, 25th, 50th, 75th, 90th, 95th, and 99th percentiles for the data. You can save these statistics in an output data set by using keyword=names specifications. You can request additional percentiles by using the PCTLPTS= option. The following percentile-options are related to these additional percentiles:
-
CIPCTLDF=(cipctl-options)
CIQUANTDF=(cipctl-options) -
requests distribution-free confidence limits for percentiles that are requested with the PCTLPTS= option. In other words, no specific parametric distribution such as the normal is assumed for the data. PROC CAPABILITY uses order statistics (ranks) to compute the confidence limits as described by Hahn and Meeker (1991). This option does not apply if you use a WEIGHT statement. You can specify the following cipctl-options:
-
ALPHA=

-
specifies the level of significance
for 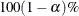 confidence intervals. The value must be between 0 and 1; the default value is 0.05, which results in 95% confidence intervals. The default value is the value
of ALPHA= given in the PROC statement.
confidence intervals. The value must be between 0 and 1; the default value is 0.05, which results in 95% confidence intervals. The default value is the value
of ALPHA= given in the PROC statement.
- LOWERPRE=prefixes
-
specifies one or more prefixes that are used to create names for variables that contain the lower confidence limits. To save lower confidence limits for more than one analysis variable, specify a list of prefixes. The order of the prefixes corresponds to the order of the analysis variables in the VAR statement.
- LOWERNAME=suffixes
-
specifies one or more suffixes that are used to create names for variables that contain the lower confidence limits. PROC CAPABILITY creates a variable name by combining the LOWERPRE= value and suffix name. Because the suffixes are associated with the requested percentiles, list the suffixes in the same order as the PCTLPTS= percentiles.
- TYPE=keyword
-
specifies the type of confidence limit, where keyword is LOWER, UPPER, SYMMETRIC, or ASYMMETRIC. The default value is SYMMETRIC.
- UPPERPRE=prefixes
-
specifies one or more prefixes that are used to create names for variables that contain the upper confidence limits. To save upper confidence limits for more than one analysis variable, specify a list of prefixes. The order of the prefixes corresponds to the order of the analysis variables in the VAR statement.
- UPPERNAME=suffixes
-
specifies one or more suffixes that are used to create names for variables that contain the upper confidence limits. PROC CAPABILITY creates a variable name by combining the UPPERPRE= value and suffix name. Because the suffixes are associated with the requested percentiles, list the suffixes in the same order as the PCTLPTS= percentiles.
Note: See the entries for the PCTLPTS= , PCTLPRE= , and PCTLNAME= options for a detailed description of how variable names are created using prefixes, percentile values, and suffixes.
-
ALPHA=
-
CIPCTLNORMAL=(cipctl-options)
CIQUANTNORMAL=(cipctl-options) -
requests confidence limits based on the assumption that the data are normally distributed for percentiles that are requested with the PCTLPTS= option. The computational method is described in Section 4.4.1 of Hahn and Meeker (1991) and uses the noncentral t distribution as given by Odeh and Owen (1980). This option does not apply if you use a WEIGHT statement. You can specify the following cipctl-options:
-
ALPHA=
-
specifies the level of significance
for confidence intervals. The value must be between 0 and 1; the default value is 0.05, which results in 95% confidence intervals. The default value is the value
of ALPHA= given in the PROC statement.
- LOWERPRE=prefixes
-
specifies one or more prefixes that are used to create names for variables that contain the lower confidence limits. To save lower confidence limits for more than one analysis variable, specify a list of prefixes. The order of the prefixes corresponds to the order of the analysis variables in the VAR statement.
- LOWERNAME=suffixes
-
specifies one or more suffixes that are used to create names for variables that contain the lower confidence limits. PROC CAPABILITY creates a variable name by combining the LOWERPRE= value and suffix name. Because the suffixes are associated with the requested percentiles, list the suffixes in the same order as the PCTLPTS= percentiles.
- TYPE=keyword
-
specifies the type of confidence limit, where keyword is LOWER, UPPER, or TWOSIDED. The default is TWOSIDED.
- UPPERPRE=prefixes
-
specifies one or more prefixes that are used to create names for variables that contain the upper confidence limits. To save upper confidence limits for more than one analysis variable, specify a list of prefixes. The order of the prefixes corresponds to the order of the analysis variables in the VAR statement.
- UPPERNAME=suffixes
-
specifies one or more suffixes that are used to create names for variables that contain the upper confidence limits. PROC CAPABILITY creates a variable name by combining the UPPERPRE= value and suffix name. Because the suffixes are associated with the requested percentiles, list the suffixes in the same order as the PCTLPTS= percentiles.
Note: See the entries for the PCTLPTS= , PCTLPRE= , and PCTLNAME= options for a detailed description of how variable names are created using prefixes, percentile values, and suffixes.
-
ALPHA=
- PCTLGROUP=BYSTAT | BYVAR
-
specifies the order in which variables that you request with the PCTLPTS= option are added to the OUT= data set when the VAR statement lists more than one analysis variable. By default (or if you specify PCTLGROUP=BYSTAT), all variables that are associated with a percentile value are created consecutively. If you specify PCTLGROUP=BYVAR, all variables that are associated with an analysis variable are created consecutively.
Consider the following statements:
proc univariate data=Score; var PreTest PostTest; output out=ByStat pctlpts=20 40 pctlpre=Pre_ Post_; output out=ByVar pctlgroup=byvar pctlpts=20 40 pctlpre=Pre_ Post_; run;
The order of variables in the data set
ByStatisPre_20,Post_20,Pre_40,Post_40. The order of variables in the data setByVarisPre_20,Pre_40,Post_20,Post_40. - PCTLNAME=suffixes
-
provides name suffixes for the new variables created by the PCTLPTS= option. These suffixes are appended to the prefixes you specify with the PCTLPRE= option, replacing the percentile values that are used as suffixes by default. List the suffixes in the same order in which you specify the percentiles. If you specify n suffixes with the PCTLNAME= option and m percentile values with the PCTLPTS= option, where
 , the suffixes are used to name the first n percentiles, and the default names are used for the remaining
, the suffixes are used to name the first n percentiles, and the default names are used for the remaining  percentiles. For example, consider the following statements:
percentiles. For example, consider the following statements:
proc capability; var length width height; output pctlpts = 20 40 pctlpre = pl pw ph pctlname = twenty; run;The value "twenty" in the PCTLNAME= option is used for only the first percentile in the PCTLPTS= list. This suffix is appended to the values in the PCTLPRE= option to generate the new variable names
pltwenty,pwtwenty, andphtwenty, which contain the 20th percentiles forlength,width, andheight, respectively. Because a second PCTLNAME= suffix is not specified, variable names for the 40th percentiles forlength,width, andheightare generated using the prefixes and percentile values. Thus, the output data set contains the variablespltwenty,pl40,pwtwenty,pw40,phtwenty, andph40. - PCTLNDEC=value
-
specifies the number of decimal places in percentile values that are incorporated into percentile variable names. The default value is 1. For example, the following statements create two output data sets, each containing one percentile variable. The variable in data set
shortis namedpwid85_1, while the one in data setlongis namedpwid85_125.proc capability; var width; output out=short pctlpts=85.125 pctlpre=pwid; output out=long pctlpts=85.125 pctlpre=pwid pctlndec=3; run;
- PCTLPRE=prefixes
-
specifies prefixes used to create variable names for percentiles requested with the PCTLPTS= option. The PCTLPRE= and PCTLPTS= options must be used together.
The procedure generates new variable names by using the prefix and the percentile values. If the specified percentile is an integer, the variable name is simply the prefix followed by the value. For noninteger percentiles, an underscore replaces the decimal point in the variable name, and decimal values are truncated to one decimal place. For example, the following statements create the variables
pwid20,pwid33_3,pwid66_6, andpwid80for the 20th, 33.33rd, 66.67th, and 80th percentiles ofwidth, respectively:proc capability noprint; var width; output pctlpts=20 33.33 66.67 80 pctlpre=pwid; run;
If you request percentiles for more than one variable, you should list prefixes in the same order in which the variables appear in the VAR statement. For example, the following statements compute the 80th and 87.5th percentiles for
lengthandwidthand save the new variablesplength80,plength87_5,pwidth80, andpwidth87_5in the output data set:proc capability noprint; var length width; output pctlpts=80 87.5 pctlpre=plength pwidth; run;
- PCTLPTS=percentiles
-
specifies percentiles that are not automatically computed by the procedure. The CAPABILITY procedure automatically computes the 1st, 5th, 10th, 25th, 50th, 75th, 90th, 95th, and 99th percentiles for the data. These can be saved in an output data set by using keyword=names specifications. The PCTLPTS= option generates additional percentiles and outputs them to a data set; these additional percentiles are not printed.
If you use the PCTLPTS= option, you must also use the PCTLPRE= option to provide a prefix for the new variable names. For example, to create variables that contain the 20th, 40th, 60th, and 80th percentiles of
length, use the following statements:proc capability noprint; var length; output pctlpts=20 40 60 80 pctlpre=plen; run;
This creates the variables
plen20,plen40,plen60, andplen80, whose values are the corresponding percentiles oflength. In addition to specifying name prefixes with the PCTLPRE= option, you can also use the PCTLNAME= option to create name suffixes for the new variables created by the PCTLPTS= option.