The Decomposition Algorithm
- Overview
-
Getting Started

-
SyntaxDecomposition Algorithm Options in the PROC OPTLP Statement or the SOLVE WITH LP Statement in PROC OPTMODELDecomposition Algorithm Options in the PROC OPTMILP Statement or the SOLVE WITH MILP Statement in PROC OPTMODELDECOMP StatementDECOMP_MASTER StatementDECOMP_MASTER_IP StatementDECOMP_SUBPROB Statement
-
Details
-
ExamplesMulticommodity Flow Problem and METHOD=NETWORKGeneralized Assignment ProblemBlock-Diagonal Structure and METHOD=CONCOMP in Single-Machine ModeBlock-Diagonal Structure and METHOD=CONCOMP in Distributed ModeBlock-Angular Structure and METHOD=AUTOBin Packing ProblemResource Allocation ProblemVehicle Routing ProblemATM Cash Management in Single-Machine ModeATM Cash Management in Distributed ModeKidney Donor Exchange and METHOD=SET
- References
Special Case: Identical Blocks and Ryan-Foster Branching
In the special case of a set partitioning master problem and identical blocks, the underlying algorithm is automatically adjusted to reduce symmetry and improve overall performance. Identical blocks are subproblems (see the section Overview: Decomposition Algorithm) that have equivalent feasible regions (and optima) when they are projected. Algebraically, this means that
![\[ \begin{array}{lllllll} \mathbf{A}^1 & =& \mathbf{A}^2 & =& \dots & =& \mathbf{A}^\kappa \\ \mathbf{D}^1 & =& \mathbf{D}^2 & =& \dots & =& \mathbf{D}^\kappa \\ \mathbf{c}^1 & =& \mathbf{c}^2 & =& \dots & =& \mathbf{c}^\kappa \\ \mathbf{b}^1 & =& \mathbf{b}^2 & =& \dots & =& \mathbf{b}^\kappa \\ \mathbf{\overline{x}}^1 & =& \mathbf{\overline{x}}^2 & =& \dots & =& \mathbf{\overline{x}}^\kappa \\ \mathbf{\underline{x}}^1 & =& \mathbf{\underline{x}}^2 & =& \dots & =& \mathbf{\underline{x}}^\kappa \end{array} \]](images/ormpug_decomp0040.png)
A set partitioning
problem is a specific type of integer programming model in which each constraint represents choosing exactly one member of
a set. These constraints are often referred to as assignment constraints. The linear relaxation of a set partitioning problem enables an algorithm to choose fractional parts of several members of
some set such that they sum to 1. Algebraically, this means 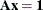 , where all the coefficients in
, where all the coefficients in 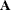 are 0 or 1.
are 0 or 1.
The performance of algorithms that use a branch-and-bound method can suffer when the formulation contains substructures that are symmetric. In this context, symmetric means that an assignment of solutions can be arbitrarily permuted for some component without affecting the optimality of that solution. For example, if
![\[ \begin{array}{llll} x_{11}=1 & x_{12}=0 & x_{21}=0 & x_{22}=1 \end{array} \]](images/ormpug_decomp0042.png)
and
![\[ \begin{array}{llll} x_{11}=0 & x_{12}=1 & x_{21}=1 & x_{22}=0 \end{array} \]](images/ormpug_decomp0043.png)
are both optimal, then these solutions, 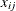 , are considered symmetric on index j. That is, you can interchange
, are considered symmetric on index j. That is, you can interchange 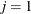 and
and 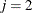 without affecting the optimality of the solution. The presence of identical blocks in a mathematical program is an obvious
case in which symmetry can hurt performance. In order to overcome this handicap, the decomposition algorithm aggregates the
identical blocks into one block when it forms the Dantzig-Wolfe master problem. If the Dantzig-Wolfe master problem is a set
partitioning model, the algorithm uses a specialized branching rule known as Ryan-Foster branching.
If the original master model (after aggregation) is equivalent to the identity matrix, this guarantees that the Dantzig-Wolfe
master problem is of the appropriate form. For more information about the aggregate formulation and Ryan-Foster branching,
see Barnhart et al. (1998).
without affecting the optimality of the solution. The presence of identical blocks in a mathematical program is an obvious
case in which symmetry can hurt performance. In order to overcome this handicap, the decomposition algorithm aggregates the
identical blocks into one block when it forms the Dantzig-Wolfe master problem. If the Dantzig-Wolfe master problem is a set
partitioning model, the algorithm uses a specialized branching rule known as Ryan-Foster branching.
If the original master model (after aggregation) is equivalent to the identity matrix, this guarantees that the Dantzig-Wolfe
master problem is of the appropriate form. For more information about the aggregate formulation and Ryan-Foster branching,
see Barnhart et al. (1998).
Suppose you want to solve the following problem:
![\[ \begin{array}{rrrrrrrrrrrrlll} \mbox{max} & x_{11} & + & 2 x_{21} & + & x_{31} & + & x_{12} & + & 2 x_{22} & + & x_{32} \\ \mbox{subject to} & x_{11} & & & & & & x_{12} & & & & & = & 1 & \mbox{(m1)} \\ & & & x_{21} & & & & & & x_{22} & & & = & 1 & \mbox{(m2)} \\ & 5 x_{11} & + & 7 x_{21} & + & 4 x_{31} & & & & & & & \leq & 11 & \mbox{(s1)} \\ & & & & & & & 5 x_{12} & + & 7 x_{22} & + & 4 x_{32} & \leq & 11 & \mbox{(s2)} \\ & \multicolumn{8}{c}{x_{ij} \in \{ 0,1\} \; \; i \in \{ 1,\dots ,3\} , j \in \{ 1,\dots ,2\} } \\ \end{array} \]](images/ormpug_decomp0047.png)
If constraints m1 and m2 are removed, then the remaining constraints s1 and s2 decompose into two independent and identical subproblems. In addition, constraints m1 and m2 form a set partitioning master problem.
The following statements use the OPTMODEL procedure and the decomposition algorithm to solve the preceding problem:
proc optmodel;
var x{i in 1..3, j in 1..2} binary;
max f = x[1,1] + 2*x[2,1] + x[3,1] +
x[1,2] + 2*x[2,2] + x[3,2];
con m1: x[1,1] + x[1,2] = 1;
con m2: x[2,1] + x[2,2] = 1;
con s1: 5*x[1,1] + 7*x[2,1] + 4*x[3,1] <= 11;
con s2: 5*x[1,2] + 7*x[2,2] + 4*x[3,2] <= 11;
s1.block = 0;
s2.block = 1;
solve with milp / presolver=none decomp=(logfreq=1);
print x;
quit;
Here, the PRESOLVER=NONE option is used again, because otherwise the presolver solves this small instance without invoking any solver. The solution summary and optimal solution are displayed in Figure 15.3.
Figure 15.3: Solution Summary and Optimal Solution
| Solution Summary | |
|---|---|
| Solver | MILP |
| Algorithm | Decomposition |
| Objective Function | f |
| Solution Status | Optimal |
| Objective Value | 5 |
| Relative Gap | 0 |
| Absolute Gap | 0 |
| Primal Infeasibility | 0 |
| Bound Infeasibility | 0 |
| Integer Infeasibility | 0 |
| Best Bound | 5 |
| Nodes | 1 |
| Iterations | 2 |
| Presolve Time | 0.00 |
| Solution Time | 0.00 |
The iteration log, which displays the problem statistics, the progress of the solution, and the optimal objective value, is shown in Figure 15.4.
Figure 15.4: Log
| NOTE: Problem generation will use 4 threads. |
| NOTE: The problem has 6 variables (0 free, 0 fixed). |
| NOTE: The problem has 6 binary and 0 integer variables. |
| NOTE: The problem has 4 linear constraints (2 LE, 2 EQ, 0 GE, 0 range). |
| NOTE: The problem has 10 linear constraint coefficients. |
| NOTE: The problem has 0 nonlinear constraints (0 LE, 0 EQ, 0 GE, 0 range). |
| NOTE: The MILP presolver value NONE is applied. |
| NOTE: The MILP solver is called. |
| NOTE: The Decomposition algorithm is used. |
| NOTE: The Decomposition algorithm is executing in single-machine mode. |
| NOTE: The DECOMP method value USER is applied. |
| NOTE: All blocks are identical and the master model is set partitioning. |
| NOTE: The Decomposition algorithm is using an aggregate formulation and Ryan-Foster branching. |
| NOTE: The number of block threads has been reduced to 1 threads. |
| NOTE: The problem has a decomposable structure with 2 blocks. The largest block covers 25% of |
| the constraints in the problem. |
| NOTE: The decomposition subproblems cover 6 (100%) variables and 2 (50%) constraints. |
| NOTE: The deterministic parallel mode is enabled. |
| NOTE: The Decomposition algorithm is using up to 4 threads. |
| Iter Best Master Best LP IP CPU Real |
| Bound Objective Integer Gap Gap Time Time |
| . 6.0000 5.0000 5.0000 16.67% 16.67% 0 0 |
| 1 6.0000 5.0000 5.0000 16.67% 16.67% 0 0 |
| 2 5.0000 5.0000 5.0000 0.00% 0.00% 0 0 |
| Node Active Sols Best Best Gap CPU Real |
| Integer Bound Time Time |
| 0 0 1 5.0000 5.0000 0.00% 0 0 |
| NOTE: The Decomposition algorithm used 4 threads. |
| NOTE: The Decomposition algorithm time is 0.00 seconds. |
| NOTE: Optimal. |
| NOTE: Objective = 5. |
The decomposition solver recognizes that the original master model is of the appropriate form and that each block is identical. It formulates the aggregate master and uses Ryan-Foster branching to solve the model.
In the presence of identical blocks, under certain circumstances, the aggregate formulation can also be used with a set covering
master formulation. A set covering
problem is an integer programming model in which each constraint represents choosing at least one member of a set. Algebraically,
this means 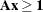 , where all the coefficients in are 0 or 1. Aggregate formulation and Ryan-Foster branching can be used if there exists an optimal solution,
, where all the coefficients in are 0 or 1. Aggregate formulation and Ryan-Foster branching can be used if there exists an optimal solution, 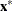 , that is binding at equality (
, that is binding at equality (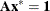 ). If you can guarantee such a condition, you can greatly improve performance by explicitly using VARSEL=RYANFOSTER as a MILP
main solver option. The decomposition algorithm usually performs better when it uses a set covering formulation as opposed
to a set partitioning formulation, because it is usually easier to find integer feasible solutions. If the models are equivalent,
using the set covering formulation is recommended. For two examples, see Example 15.6, which shows the bin packing problem, and Example 15.8, which shows the vehicle routing problem.
). If you can guarantee such a condition, you can greatly improve performance by explicitly using VARSEL=RYANFOSTER as a MILP
main solver option. The decomposition algorithm usually performs better when it uses a set covering formulation as opposed
to a set partitioning formulation, because it is usually easier to find integer feasible solutions. If the models are equivalent,
using the set covering formulation is recommended. For two examples, see Example 15.6, which shows the bin packing problem, and Example 15.8, which shows the vehicle routing problem.
Similarly, a set packing
problem is an integer programming model in which each constraint represents choosing at most one member of a set. Algebraically,
this means 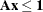 , where all the coefficients in are 0 or 1. Aggregate formulation and Ryan-Foster branching can be used if there exists an optimal solution, , that is binding at equality (). In this case, using VARSEL=RYANFOSTER can improve performance. Alternatively, you can transform any set packing model into
a set partitioning model by introducing a zero-cost slack variable for each packing constraint. See Example 15.11, which shows an application that optimizes a kidney donor exchange.
, where all the coefficients in are 0 or 1. Aggregate formulation and Ryan-Foster branching can be used if there exists an optimal solution, , that is binding at equality (). In this case, using VARSEL=RYANFOSTER can improve performance. Alternatively, you can transform any set packing model into
a set partitioning model by introducing a zero-cost slack variable for each packing constraint. See Example 15.11, which shows an application that optimizes a kidney donor exchange.
The decomposition algorithm automatically searches for identical blocks and the appropriate set partitioning master formulation. If it finds this structure, the algorithm automatically generates the aggregate formulation and uses Ryan-Foster branching. The aggregate model needs to process only one block at each subproblem iteration. Therefore, parallel processing (in which multiple blocks are processed simultaneously), as described in the section Parallel Processing, cannot improve performance. For this reason, when the decomposition algorithm runs in distributed mode, it does not create the aggregate formulation, nor does it use Ryan-Foster branching, even if the blocks are found to be identical.