IMSTAT Procedure (Analytics)
- Syntax
 Procedure SyntaxPROC IMSTAT (Analytics) StatementAGGREGATE StatementARM StatementASSESS StatementBOXPLOT StatementCLUSTER StatementCORR StatementCROSSTAB StatementDECISIONTREE StatementDISTINCT StatementFORECAST StatementFREQUENCY StatementGENMODEL StatementGLM StatementGROUPBY StatementHISTOGRAM StatementKDE StatementLOGISTIC StatementMDSUMMARY StatementNEURAL StatementOPTIMIZE StatementPERCENTILE StatementRANDOMWOODS StatementREGCORR StatementSUMMARY StatementTEXTPARSE StatementTOPK StatementQUIT Statement
Procedure SyntaxPROC IMSTAT (Analytics) StatementAGGREGATE StatementARM StatementASSESS StatementBOXPLOT StatementCLUSTER StatementCORR StatementCROSSTAB StatementDECISIONTREE StatementDISTINCT StatementFORECAST StatementFREQUENCY StatementGENMODEL StatementGLM StatementGROUPBY StatementHISTOGRAM StatementKDE StatementLOGISTIC StatementMDSUMMARY StatementNEURAL StatementOPTIMIZE StatementPERCENTILE StatementRANDOMWOODS StatementREGCORR StatementSUMMARY StatementTEXTPARSE StatementTOPK StatementQUIT Statement - Overview
- Examples Calculating Percentiles and QuartilesRetrieving Box ValuesRetrieving Box Plot Values with the NOUTLIERLIMIT= OptionRetrieving Distinct Value Counts and GroupingPerforming a Cluster AnalysisPerforming a Pairwise CorrelationCrosstabulation with Measures of Association and Chi-Square TestsTraining and Validating a Decision TreeStoring and Scoring a Decision TreePerforming a Multi-Dimensional SummaryFitting a Regression ModelForecasting and Automatic ModelingForecasting with Goal SeekingAggregating Time Series DataTraining and Validating a Neural NetworkPredicting E-Mail Spam and Assessing the Model
LOGISTIC Statement
The LOGISTIC statement can model binary data with logit, probit, log-log, and complementary log-log link functions. It can also model binomial data with the same set of link functions.
Syntax
Required Arguments
dependent-variable
specifies the variable to model. This variable is also referred to as the response variable.
event-variable
specifies the name of the variable that indicates the count of positive responses.
model-effects
specifies a list of variables to use for modeling the dependent variable.
trial-variable
specifies the name of the variable that indicates the total number of trials.
Optional Argument
class-variables
specifies a list of variables to use as classification variables. The variables in this list take the place of the CLASS statement in traditional SAS procedures.
LOGISTIC Statement Options
ALLIDVARS
requests that all variables in the input table are treated as ID variables when a scoring table is produced. In other words, if this option is specified, all variables from the input table, including computed columns, are transferred to the scoring table.
ALPHA=number
specifies a number between 0 and 1 from which to determine the confidence level for approximate confidence intervals of the parameter estimates. The default is α = 0.05, which leads to 100 x (1- α)% = 95% confidence limits for the parameter estimates.
| Default | 0.05 |
CI
specifies to add confidence intervals to the table of parameter estimates. The confidence level is 100*(1-α)% where α is determined by the ALPHA= option. The default value is α = 0.05. This value is equivalent to a 95% confidence limit.
| Default | 0.05 |
CLASSFORMATS=("format-name1"<, "format-name2" ...>)
specifies the formats for the classification variables in the model. If you do not specify the CLASSFORMATS= option, the default format is applied for the classification variable. That default format was determined when the table was originally loaded into the server. In the following example, the CLASSFORMAT= values apply to variables x1 and x2.
| Alias | CLASSFMT= |
| Example | logistic y (x1 x2) = x3-x7 / classformats=("YN.", "F8."); |
CODE <(code-generation-options)>
requests that the server produce SAS scoring code based on the actions that it performed during the analysis. The server generates DATA step code. By default, the code is replayed as an ODS table by the procedure as part of the output of the statement. More frequently, you might want to write the scoring code to an external file by specifying options.
Y, the
generated code stores the predicted value as P_Y.
The name of the variable is truncated to fit within the SAS name length
requirements.
COMMENT
specifies to add comments to the code in addition to the header block. The header block is added by default.
FILENAME='path'
specifies the name of the external file to which the scoring code is written. This suboption applies only to the scoring code itself. If you request that the server generate IMSTAT programming statements with the IMSTAT suboption, then these statements are saved as an ODS table.
| Alias | FILE= |
FORMATWIDTH=k
specifies the width to use in formatting derived numbers such as parameter estimates in the scoring code. The server applies the BEST format, and the default format for code generation is BEST20.
| Alias | FMTW= |
| Range | 4 to 32 |
IMSTAT
specifies to generate IMSTAT programming statements that reproduce the analysis in addition to the scoring code. For example, this option is helpful when you perform variable selection and you want to capture the modeling code that reflects only the selected variables.
IMSTATONLY
specifies to generate the IMSTAT programming statements only. No scoring code is produced.
LABELID=id
specifies a group identifier for group processing. The identifier is an integer and is used to create array names and statement labels in the generated code.
LINESIZE=n
specifies the line size for the generated code.
| Alias | LS= |
| Default | 72 |
| Range | 64 to 256 |
NOTRIM
requests that the comparison of the formatted values for class variables and group-by variables is based on the full format width with padding. By default, the leading and trailing blanks are removed from the formatted values.
REPLACE
specifies to overwrite the external file with the new contents if the file already exists. This option has no effect unless you specify the FILENAME= option.
DESCENDING
specifies to model the largest ordered value for the dependent variable instead of the smallest. This option is useful for modeling responses with the value of 1 instead of modeling for value 0.
| Alias | DESC |
EXCLUDE=(list-of-ODS-tables)
specifies the result tables that you want to exclude from being generated on the server and from being sent to the SAS session. The GLM statement can generate the following tables:
|
Table Name
|
Table Alias
|
Description
|
Condition
|
|---|---|---|---|
|
ModelInfo
|
Information about the
model—constant across groups or partitions.
|
This table is shown
by default.
|
|
|
ClassLevels
|
Class
|
Information about the
classification variables, such as the number of levels and their values.
|
This table is shown
when classification variables are present in the model.
|
|
ConvStatus
|
Convergence
|
Convergence status of
optimization
|
This table is shown
by default.
|
|
Dimensions
|
Dim
|
Model dimensions
|
This table is shown
by default.
|
|
FitStatistics
|
Fit
|
Fit statistics customary
for regression models
|
This table is shown
when it is requested with the SELECT= option.
|
|
GlobalTest
|
Global
|
Test of the hypothesis
that the model fits as well as a null model without explanatory variables
|
This table is shown
my default.
|
|
IterHistory
|
IterHist
|
Iteration history
|
This table is shown
when the ITDETAILS option is used or when the table is requested with
the SELECT= option.
|
|
ParmEstimates
|
ParameterEstimates
Pest
|
The solutions for the
linear model coefficients
|
This table is shown
when there are no classification variables in the model.
|
|
ResponseProfile
|
Resp
|
Information about the
values of the binary response variable such as the level order and
frequency
|
This table is shown
when modeling binary data. (When the events/trials syntax is not used.)
|
|
Tests3
|
Type III tests of model
effects
|
This table is shown
when the effects contain classification variables and the NOSTDERR
option is not specified.
|
FORMATS=("format-specification"<,...>)
specifies the formats for the GROUPBY variables. If you do not specify the FORMATS= option, or if you omit the entry for a GROUPBY variable, the default format is applied for that variable.
| Example | proc imstat data=lasr1.table1; statement / groupby=(a b) formats=("8.3", "$10"); quit; |
FCONV=r
specifies a relative function convergence criterion. For all techniques except NMSIMP, termination requires a small relative change of the function value in successive iterations. Suppose that Ψ is the p × 1 vector of parameter estimates in the optimization, and the objective function at the kth iteration is denoted as f(Ψ)k. Then, the FCONV criterion is met if
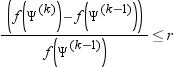
| Default | r=10-FDIGITS where FDIGITS is -log10(e) and e is the machine precision. |
FREQ=variable-name
specifies the numeric variable that provides frequencies for the analysis. For example, if the FREQ= variable has the value 5, then it implies that the record represents five such observations with identical values for the modeling variables. If you specify a FREQ= variable, then only the observations with a value that is not missing and greater than zero for the variable are used in the analysis.
GCONV=r
specifies a relative gradient convergence criterion. For all optimization techniques except CONGRA and NMSIMP, termination requires that the normalized predicted function reduction is small. The default value is r = 1e-8. Suppose that Ψ is the p × 1 vector of parameter estimates in the optimization with ith element Ψi. The objective function, its p × 1 gradient vector, and its p × p Hessian matrix are denoted, f(Ψ), g(Ψ), and H(Ψ ), respectively. Then, if superscripts denote the iteration count, the normalized predicted function reduction at iteration k is
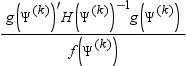
GROUPBY=(variable-list)
specifies the names of the Group-by variables in the order of the grouping hierarchy. If no variable names are specified, the model is fit across the entire table—possibly subject to a WHERE clause.
GROUPFILTER=(filter-options)
specifies a section of the group-by hierarchy to be included in the computation. With this option, you can request that the server performs the analysis for only a subset of all possible groupings. The subset is determined by applying the group filter to a temporary table that you generate with the GROUPBY statement.
DESCENDING
specifies the top section or the bottom section of the groupings to be collected. If the DESCENDING option is specified, the top LIMIT=n (where n > 0) groupings are collected. Otherwise, the bottom LIMIT=n groupings are collected.
| Alias | DESC |
LIMIT=n
specifies the maximum number of distinct groupings to be collected, where integer n >= 0. If n is zero, then all distinct groupings (up to 231–1) that satisfy the boundary constraints, such as LOWERSCORE=f, are collected.
| CAUTION: |
High Cardinality
Data Sets
Setting n to
zero with high-cardinality data sets can significantly delay the response
of the server.
|
SCOREGT=f
specifies the exclusive lower bound for the numeric scores of the distinct groupings to collect.
| Alias | SGT= |
SCORELT=f
specifies the exclusive upper bound for the numeric scores of the distinct groupings to collect.
| Alias | SLT= |
VALUEGT=("format-name1" <, "format-name2" ...>)
specifies the exclusive lower bound of the group-by variable’s formatted values for the distinct groupings to collect.
| Alias | VGT= |
VALUELT=("format-name1" <, "format-name2" ...>)
specifies the exclusive upper bound of the group-by variable’s formatted values for the distinct groupings to collect.
| Alias | VLT= |
TABLE=table-with-groupby-results
specifies the in-memory table from which to load the group-by hierarchy. If the TABLE= option is not specified, then all other GROUPFILTER= options are ignored.
proc imstat;
table example.cars_program_all;
groupby state city trade_in_model / temptable
weight=new_vehicle_msrp
agg =(max)
order =weight;
run; table example.cars_program_all;
distinct sales_type / groupfilter=(
table =mylasr.&_TEMPLAST_
scoregt=40000
valuelt=("FL","Ft Myers","")
limit =20
descending);
run;| Interaction | If you specify the GROUPFILTER= option, then the GROUPBY= and FORMATS= options have no effect. |
IDVARS=(variable-list)
IDVARS=variable-name
specifies the variables from the active table to transfer to the temporary table that is created by scoring the input table. This option has no effect unless the SCORE option is also specified. (See the SCORE option for details about which variables are added to the temporary table by default.) The IDVARS= option should be used to transfer additional columns from the input table to the scoring table.
| Alias | ID= |
| Tip | Instead of this option, you can specify the ALLIDVARS option to transfer all variables from the input table to the scoring table. |
ITDETAILS
requests to add details about the iterative model fitting process (an iteration history) to the ODS output tables.
| Alias | ITDETAIL |
KEYORDER
requests that the results for a partitioned analysis are displayed in the order of the partition keys. If this option is not specified, then results are displayed by using the partitions on the first worker node followed by the partitions on the second node, and so on. Without this option, the results are likely to have random ordering of the partitions. The KEYORDER option makes result collection less efficient but produces a natural, predictable order.
LINK=function
specifies the link function to use for the model fitting process. See the following list for the available functions:
-
LOGIT
-
PROBIT
-
LOGLOG
-
CLOGLOG
| Default | LOGIT |
MAXFUNC=n
specifies the maximum number n of function calls in the iterative model fitting process. The default value depends on the optimization technique as follows:
|
Optimization Technique
|
Default Number of Function
Calls
|
|---|---|
|
TRUREG, NRRIDG, and
NEWRAP
|
125
|
|
QUANEW and DBLDOG
|
500
|
|
CONGRA
|
1000
|
|
NMSIMP
|
3000
|
| Alias | MAXFU= |
MAXITER=i
MAXTESTLEV=n
specifies the maximum number of levels in an effect for which the server generates Type III tests. The idea behind the MAXTESTLEV= option is that testing effects for significance that have a large number of levels is typically not meaningful. The effects tend to be highly significant anyway, but determining the exact significance level is computationally intensive. The default value is 300 and implies that no test statistics are produced for any effect that has more than 300 levels.
| Default | 300 |
NAME=SAS-name
specifies the name to use for identifying the model in the server output and in the temporary table of results generated by the TEMPTABLE option. SAS name rules apply. For example, the following statements add the 'Model' entry to the ModelInformation table.
proc imstat;
table hps.neuralgia;
logistic pain = treatment sex duration / name = LogisModel
run;

NOCLPRINT <=n>
specifies the number of levels for each classification variables to show in the Class Level Information ODS table. If you do not specify the NOCLPRINT option, all unique values are shown in the order of the class variable levelization. If you specify NOCLPRINT=n, then the values are shown for those classification variables that have less than n levels only. The value for n must be at least 1.
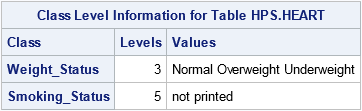
NOINT
suppresses the inclusion of an intercept in the model. By default, all models contain an intercept term.
NOPREPARSE
prevents the procedure from preparsing and pregenerating code for temporary expressions, scoring programs, and other user-written SAS statements.
| Alias | NOPREP |
NOSTDERR
prevents the computation of the covariance matrix and the standard errors of the parameter estimates. When you specify this option, the Type III tests for the model effects are also not available.
| Alias | NOSTD |
OFFSET=variable-name
specifies the offset variable for the analysis. An offset variable can be thought of as a regressor variable whose regression coefficient is known to be 1. Offsets are used to shift the linear predictors by a certain amount. For example, an offset can be used to accommodate constants in the underlying model. For example, a model for the probability of being seropositive is as follows:
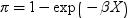
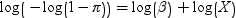
PARTITION <=partition-key>
When you specify this option and the table is partitioned, the results are calculated separately for each value of the partition key. In other words, the partition variables function as automatic GROUPBY variables. This mode of executing calculations by partition is more efficient than using the GROUPBY= option. With a partitioned table, the server takes advantage of knowing that observations for a partition cannot be located on more than one worker node.
statement / partition="F 11"; /* passed directly to the server */ statement / partition="F","11"; /* composed by the procedure */
| Alias | PART= |
ROLEVAR=variable-name
specifies a variable in the in-memory table that defines whether an observation belongs to the training set, the validation set, or is to be excluded from the analysis. The role variable can have a numeric or character type, and it can be a temporary computed variable.
-
value = 1: this observation is in the training set
-
value = 2: this observation is in the validation set
-
any other value: this observation is to be excluded from the analysis
-
If the first non-blank character is 't' or 'T', then the observation is in the training set.
-
If the first non-blank character is 'v' or 'V', then he observation is in the validation set.
-
Any other value for the first non-blank character, including an all blank entry, leads to the exclusion of the observation from the analysis.
| Alias | ROLE= |
| Interactions | You can divide the data at random into training and validation sets by providing the VALIDATE= and SEED= options. |
| If you specify both the ROLEVAR= option and the VALIDATE= options, then the ROLEVAR= setting supersedes the VALIDATE= option. |
SCORE <(score-statistic1score-statistic2...)>
requests that the active table be scored after the model is fit and the results be stored in a temporary table. The server automatically adds all model variables to the temporary table with the score results. These results include the response variable, the class variables, all explanatory variables from which effects are formed, and the WEIGHT=, and FREQ= variables.
|
Keyword and Aliases
|
Column Name
|
Description
|
Default
|
|---|---|---|---|
|
PRED, PREDICTED, LINP
|
_PRED_
|
Predicted linear predictor
value
|
Yes
|
|
RESID, RESIDUAL, R
|
_RESID_
|
Raw residual (on a linear
scale)
|
Yes
|
|
LEVERAGE, H
|
_LEVERAGE_
|
Measure of how extreme
an observation is in the regressor space
|
Yes
|
|
ILINK, MEAN, PROB
|
_ILINK_
|
Inversely linked linear
predictor, the predicted mean of the response
|
Yes
|
|
PEARSON, RESCHI
|
_PEARSON_
|
Pearson residual, also
known as the Chi-square residual
|
Yes
|
|
DEVRESID, RESDEV
|
_DEVRESID_
|
Deviance residual
|
Yes
|
|
LIKEDIST, LD, RESLIKE
|
_LIKEDIST_
|
Likelihood displacement
|
Yes
|
|
STDRES, STDRESCHI
|
_STDRESCHI_
|
Standardized Pearson
Chi-square residual
|
Yes
|
|
STDP
|
_STDP_
|
Standard error of the
mean predicted value
|
No
|
|
LCLM, LOWERMEAN
|
_LCLM_
|
Lower confidence limit
for the mean of the predicted value
|
No
|
|
UCLM, UPPERMEAN
|
_UCLM_
|
Upper confidence limit
for the mean of the predicted value
|
No
|
|
LCL, LOWERPRED
|
_LCL_
|
Lower confidence limit
for the predicted value
|
No
|
|
UCL, UPPERPRED
|
_UCL_
|
Upper confidence limit
for the predicted value
|
No
|
|
DIFDEV
|
_DIFDEV_
|
Change in the deviance
due to the deletion of the observation
|
No
|
|
DIFCHISQ
|
_DIFCHISQ_
|
Change in the Pearson
statistic due to deletion of the observation
|
No
|
SELECT=(list-of-ODS-tables)
specifies the list of ODS tables that you want to display for the analysis. The specified list replaces the default tables that are generated by the server and displayed. See the EXCLUDE= option for the list of default tables and the table names that you can display.
SHOWSELECTED
requests that the server perform variable selection for the model. A backward selection method is used, where the significance level for an effect to remain in the model is determined by the SLSTAY= option. This option performs variable selection like the VARSEL option, but in contrast to the latter option, it displays output only for the selected effects.
| Alias | SHOWSEL |
SLSTAY=α
specifies the significance level used in determining whether effects should stay in the model during variable selection.
| Default | 0.1 |
| Range | 0 to 1 |
TECHNIQUE=
specifies the optimization technique.
| CONGRA (CG) | performs a conjugate-gradient optimization. |
| DBLDOG (DD) | performs a version of the double-dogleg optimization. |
| DUQUANEW (DQN) | performs a (dual) quasi-Newton optimization. |
| NMSIMP (NS) | performs a Nelder-Mead simplex optimization. |
| NONE | specifies not to perform any optimization. This value can be used to perform a grid search without optimization. |
| NEWRAP (NRA) | performs a (modified) Newton-Raphson optimization that combines a line-search algorithm with ridging. |
| NRRIDG (NRR) | performs a (modified) Newton-Raphson optimization with ridging. |
| QUANEW (QN) | performs a quasi-Newton optimization. If you specify this technique, but specify bounds for any parameter, the server automatically performs DUQUANEW. |
| TRUREG (TR) | performs a trust-region optimization. |
| Alias | TECH= |
| Default | NRRIDG |
TEMPEXPRESS="SAS-expressions"
TEMPEXPRESS=file-reference
specifies either a quoted string that contains the SAS expression that defines the temporary variables or a file reference to an external file with the SAS statements.
| Alias | TE= |
TEMPNAMES=variable-name
TEMPNAMES=(variable-list)
specifies the list of temporary variables for the request. Each temporary variable must be defined through SAS statements that you supply with the TEMPEXPRESS= option.
| Alias | TN= |
TEMPTABLE
generates an in-memory temporary table from the result set. The IMSTAT procedure displays the name of the table and stores it in the &_TEMPLAST_ macro variable, provided that the statement executed successfully.
VALIDATE=f
specifies the proportion f in the validation data set.
| Alias | VALPROP= |
| Range | 0 to 1 |
| Interaction | If you specify both the ROLEVAR= option and the VALIDATE= option, then the ROLEVAR= setting supersedes the VALIDATE= option. |
VARSELECTION
specifies that the server perform variable selection for the model. A backward selection method is used, where the significance level for an effect to remain in the model is determined by the SLSTAY= option. In contrast to the SHOWSEL option, all effects are reported in the IMSTAT output.
| Alias | VARSEL |
WEIGHT=variable-name
specifies the numeric variable to use as a weighing variable in solving the linear model.