IMSTAT Procedure (Analytics)
- Syntax
 Procedure SyntaxPROC IMSTAT (Analytics) StatementAGGREGATE StatementARM StatementASSESS StatementBOXPLOT StatementCLUSTER StatementCORR StatementCROSSTAB StatementDECISIONTREE StatementDISTINCT StatementFORECAST StatementFREQUENCY StatementGENMODEL StatementGLM StatementGROUPBY StatementHISTOGRAM StatementKDE StatementLOGISTIC StatementMDSUMMARY StatementNEURAL StatementOPTIMIZE StatementPERCENTILE StatementRANDOMWOODS StatementREGCORR StatementSUMMARY StatementTEXTPARSE StatementTOPK StatementQUIT Statement
Procedure SyntaxPROC IMSTAT (Analytics) StatementAGGREGATE StatementARM StatementASSESS StatementBOXPLOT StatementCLUSTER StatementCORR StatementCROSSTAB StatementDECISIONTREE StatementDISTINCT StatementFORECAST StatementFREQUENCY StatementGENMODEL StatementGLM StatementGROUPBY StatementHISTOGRAM StatementKDE StatementLOGISTIC StatementMDSUMMARY StatementNEURAL StatementOPTIMIZE StatementPERCENTILE StatementRANDOMWOODS StatementREGCORR StatementSUMMARY StatementTEXTPARSE StatementTOPK StatementQUIT Statement - Overview
- Examples Calculating Percentiles and QuartilesRetrieving Box ValuesRetrieving Box Plot Values with the NOUTLIERLIMIT= OptionRetrieving Distinct Value Counts and GroupingPerforming a Cluster AnalysisPerforming a Pairwise CorrelationCrosstabulation with Measures of Association and Chi-Square TestsTraining and Validating a Decision TreeStoring and Scoring a Decision TreePerforming a Multi-Dimensional SummaryFitting a Regression ModelForecasting and Automatic ModelingForecasting with Goal SeekingAggregating Time Series DataTraining and Validating a Neural NetworkPredicting E-Mail Spam and Assessing the Model
DISTINCT Statement
The DISTINCT statement calculates the count of unique raw values of variables. You can specify the variables to calculate in the variable list. If no list is specified, the count of unique raw values is calculated for all variables.
Syntax
DISTINCT Statement Options
FORMATS=("format-specification",...)
specifies the formats for the GROUPBY= variables. If you do not specify the FORMAT= option, or if you do not specify the GROUPBY= option, the default format is applied for that variable.
| Example | proc imstat data=lasr1.table1;
DISTINCT x / groupby=(a b) formats=("8.3", "$10");
quit;
|
GROUPBY=(variable-list)
specifies a list of variable names, or a single variable name, to use as GROUPBY variables in the order of the grouping hierarchy. If you do not specify any GROUPBY variable names, then the calculation is performed across the entire table—possibly subject to a WHERE clause.
GROUPBYLIMIT=n
specifies the maximum number of levels in a GROUPBY set. When the software determines that there are at least n levels in the GROUPBY set, it abandons the action, returns a message, and does not produce a result set. You can specify the GROUPBYLIMIT= option if you want to avoid creating excessively large result sets in GROUPBY operations.
GROUPFILTER=(filter-options)
specifies a section of the group-by hierarchy to be included in the computation. With this option, you can request that the server performs the analysis for only a subset of all possible groupings. The subset is determined by applying the group filter to a temporary table that you generate with the GROUPBY statement.
DESCENDING
specifies the top section or the bottom section of the groupings to be collected. If the DESCENDING option is specified, the top LIMIT=n (where n > 0) groupings are collected. Otherwise, the bottom LIMIT=n groupings are collected.
| Alias | DESC |
LIMIT=n
specifies the maximum number of distinct groupings to be collected, where integer n >= 0. If n is zero, then all distinct groupings (up to 231–1) that satisfy the boundary constraints, such as LOWERSCORE=f, are collected.
| CAUTION: |
High Cardinality
Data Sets
Setting n to
zero with high-cardinality data sets can significantly delay the response
of the server.
|
SCOREGT=f
specifies the exclusive lower bound for the numeric scores of the distinct groupings to collect.
| Alias | SGT= |
SCORELT=f
specifies the exclusive upper bound for the numeric scores of the distinct groupings to collect.
| Alias | SLT= |
VALUEGT=("format-name1" <, "format-name2" ...>)
specifies the exclusive lower bound of the group-by variable’s formatted values for the distinct groupings to collect.
| Alias | VGT= |
VALUELT=("format-name1" <, "format-name2" ...>)
specifies the exclusive upper bound of the group-by variable’s formatted values for the distinct groupings to collect.
| Alias | VLT= |
TABLE=table-with-groupby-results
specifies the in-memory table from which to load the group-by hierarchy. If the TABLE= option is not specified, then all other GROUPFILTER= options are ignored.
proc imstat;
table example.cars_program_all;
groupby state city trade_in_model / temptable
weight=new_vehicle_msrp
agg =(max)
order =weight;
run; table example.cars_program_all;
distinct sales_type / groupfilter=(
table =mylasr.&_TEMPLAST_
scoregt=40000
valuelt=("FL","Ft Myers","")
limit =20
descending);
run;| Interaction | If you specify the GROUPFILTER= option, then the GROUPBY= and FORMATS= options have no effect. |
MAXNVALS=n
specifies the maximum size that trees are allowed to consume during the calculation of distinct counts. If you execute a DISTINCT statement with a GROUPBY= or PARTITION= option, then the MAXNVALS limit applies within the groups or partitions.
| Default | 6 |
NOMISSING
specifies that you do not want to include missing values in the determination of the distinct count.
| Alias | NOMISS |
NOPREPARSE
prevents the procedure from preparsing and pregenerating code for temporary expressions, scoring programs, and other user-written SAS statements.
| Alias | NOPREP |
NOTEMPPART
specifies that the temporary table generated by the TEMPTABLE option is not partitioned by the GROUPBY= variables. When you request a temporary table with the DISTINCT statement, by default, the server partitions the table and the size of a partition is equal to the number of analysis variables in the variable-list of the DISTINCT statement. When the number of groups is large, this can result in many small partitions, and requires extra memory resources to store the partition information for the temporary table. By specifying this option, the temporary table is organized similarly to the default table, but is not a partitioned table.
| Alias | NOTP |
ORDERBY=(variable-list)
specifies one or more variables by which to order the result set. The variables specified in variable-list are either one or more of the GROUPBY= variables or one or more of the analysis variables. If you specify an incorrect variable, the server returns an error and no result set. Separate multiple variables with a space.
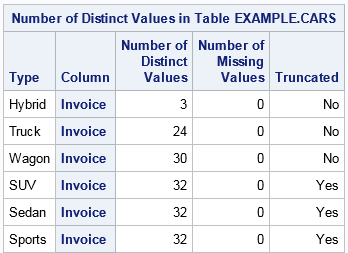
data example.cars; set sashelp.cars; run;
proc imstat data=example.CARS;
distinct Invoice / GROUPBY=Type ORDERBY=Invoice MAXNVALS=32;
run;
ORDERBYDESC
specifies the sort order for the result set. The default is ascending order. Specifying this option arranges the results in descending order. This option has no effect unless you specify the ORDERBY= option.
PARTITION <=partition-key>
When you specify this option and the table is partitioned, the results are calculated separately for each value of the partition key. In other words, the partition variables function as automatic GROUPBY variables. This mode of executing calculations by partition is more efficient than using the GROUPBY= option. With a partitioned table, the server takes advantage of knowing that observations for a partition cannot be located on more than one worker node.
statement / partition="F 11"; /* passed directly to the server */ statement / partition="F","11"; /* composed by the procedure */
| Alias | PART= |
RESULTLIMIT=k
specifies that the number of items that are returned to the client is limited to k times the number of analysis variables if you also specify the GROUPBY= or ORDERBY= option.
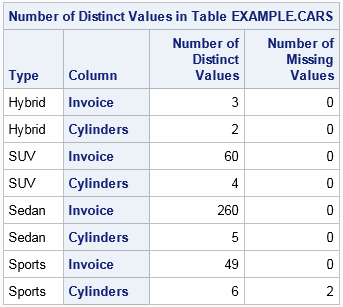
data example.cars; set sashelp.cars; run;
proc imstat data=example.CARS;
distinct Invoice Cylinder / resultlimit=4;
run;
SAVE=table-name
saves the result table so that you can use it in other IMSTAT procedure statements like STORE, REPLAY, and FREE. The value for table-name must be unique within the scope of the procedure execution. The name of a table that has been freed with the FREE statement can be used again in subsequent SAVE= options.
SETSIZE
requests that the server estimate the size of the result set. The procedure does not create a result table if the SETSIZE option is specified. Instead, the procedure reports the number of rows that are returned by the request and the expected memory consumption for the result set (in KB). If you specify the SETSIZE option, the SAS log includes the number of observations and the estimated result set size. See the following log sample:
NOTE: The LASR Analytic Server action request for the STATEMENT
statement would return 17 rows and approximately
3.641 kBytes of data.SORTAGG=aggregation-method
specifies the aggregator for which the ordering of the result set is based, if the ORDERBY= option is specified.
| N | number of observations |
| NMISS | number of missing observations |
| Interaction | You must specify the ORDERBY= option to use this option. |
TEMPEXPRESS="SAS-expressions"
TEMPEXPRESS=file-reference
specifies either a quoted string that contains the SAS expression that defines the temporary variables or a file reference to an external file with the SAS statements.
| Alias | TE= |
TEMPNAMES=variable-name
TEMPNAMES=(variable-list)
specifies the list of temporary variables for the request. Each temporary variable must be defined through SAS statements that you supply with the TEMPEXPRESS= option.
| Alias | TN= |
TEMPTABLE
generates an in-memory temporary table from the result set. The IMSTAT procedure displays the name of the table and stores it in the &_TEMPLAST_ macro variable, provided that the statement executed successfully.
| Interaction | The TEMPTABLE option requires a group-by analysis or a partitioned analysis. |
VARFORMATS=("format-specification",...)
specifies the formats for the analysis variables. If you do not specify this option, the distinct count is based on the number of distinct unformatted values of a variable. Note that the FORMATS= option controls the formatting of the GROUPBY= variables and the VARFORMATS= option controls the formatting of the analysis variables. It is possible to specify a different format for a variable if it appears as a GROUPBY variable and as an analysis variable.
| Example | proc imstat data=example.cars;
distinct msrp invoice / varformats=("", "PRICE20");
run;
|
Details
ODS Table Names
|
ODS Table Name
|
Description
|
Option
|
|---|---|---|
|
Distinct counts for
one or more columns
|
Default
|
|
|
TempTable
|
Information about a
temporary table
|
TEMPTABLE
|