| Time Series Analysis and Examples |
Minimum AIC Procedure
The AIC statistic is widely used to select the
best model among alternative parametric models.
The minimum AIC model selection procedure can be interpreted
as a maximization of the expected entropy (Akaike 1981).
The entropy of a true probability density function (PDF)
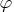 with respect to the fitted PDF
with respect to the fitted PDF 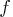 is written as
is written as
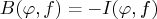
where
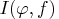
is a Kullback-Leibler
information measure, which is defined as
![i(\varphi,f) = \int [ \log [ \frac{\varphi(z)}{f(z)} ] ] \varphi(z) dz](images/timeseriesexpls_timeseriesexplseq50.gif)
where the random variable
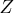
is assumed to be continuous.
Therefore,
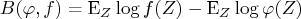
where
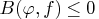
and E
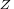
denotes the
expectation concerning the random variable
.
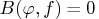
if and only if
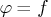
(a.s.).
The larger the quantity E
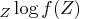
, the closer
the function
is to the true PDF
.
Given the data
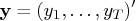
that has the same distribution as the random variable
, let the likelihood function of the parameter
vector
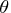
be
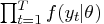
.
Then the average of the log-likelihood function
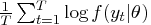
is
an estimate of the expected value of
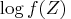
.
Akaike (1981) derived the alternative estimate of
E
by using the Bayesian predictive likelihood.
The AIC is the bias-corrected estimate of
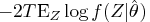
, where
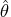
is the maximum likelihood estimate.
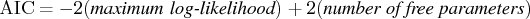
Let
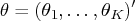
be a
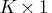
parameter vector that is
contained in the parameter space
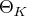
.
Given the data
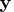
, the log-likelihood function is
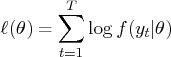
Suppose the probability density function
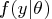
has
the true PDF
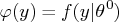
, where the true
parameter vector
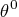
is contained in
.
Let
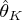
be a maximum likelihood estimate.
The maximum of the log-likelihood function is denoted as
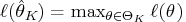
.
The expected log-likelihood function is defined by
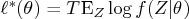
The Taylor series expansion of the expected log-likelihood
function around the true parameter
gives the following asymptotic relationship:
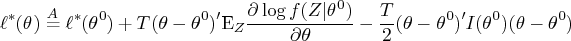
where
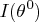
is the information matrix and
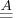
stands for asymptotic equality.
Note that
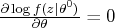
since
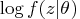
is maximized at
.
By substituting
, the expected
log-likelihood function can be written as
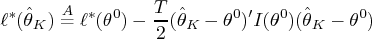
The maximum likelihood estimator is asymptotically
normally distributed under the regularity conditions
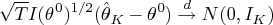
Therefore,
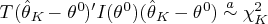
The mean expected log-likelihood function,
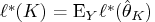
, becomes
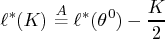
When the Taylor series expansion of the log-likelihood
function around
is used,
the log-likelihood function
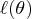
is written
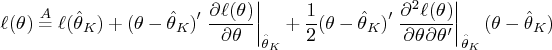
Since
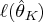
is the
maximum log-likelihood function,
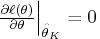
.
Note that
![{\rm plim} [ -\frac{1}t . \frac{\partial^2 \ell(\theta)} {\partial \theta \partial \theta^'} | _{\hat{\theta}_k} ] = i(\theta^0)](images/timeseriesexpls_timeseriesexplseq90.gif)
if the maximum likelihood estimator
is a consistent estimator of
.
Replacing
with the true parameter
and
taking expectations with respect to the random variable
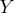
,
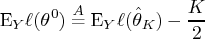
Consider the following relationship:
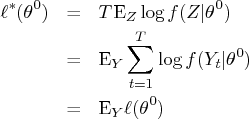
From the previous derivation,
Therefore,
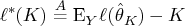
The natural estimator for E
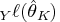
is
.
Using this estimator, you can write the
mean expected log-likelihood function as
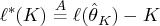
Consequently, the AIC is defined as an asymptotically unbiased
estimator of
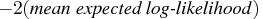
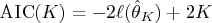
In practice, the previous asymptotic result is expected
to be valid in finite samples if the number of free
parameters does not exceed
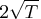
and the upper
bound of the number of free parameters is
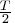
.
It is worth noting that the amount of AIC is
not meaningful in itself, since this value is
not the Kullback-Leibler information measure.
The difference of AIC values can be used to select the model.
The difference of the two AIC values is
considered insignificant if it is far less than 1.
It is possible to find a better model when the
minimum AIC model contains many free parameters.