The HPCDM Procedure(Experimental)

Overview: HPCDM Procedure
In many loss modeling applications, the loss events are analyzed by modeling the severity (magnitude) of loss and the frequency (count) of loss separately. The primary goal of preparing these models is to estimate the aggregate loss—that is, the total loss that occurs over a period of time for which the frequency model is applicable. For example, an insurance company might want to assess the expected and worst-case losses for a particular business line, such as automobile insurance, over an entire year given the models for the number of losses in a year and the severity of each loss. A bank might want to assess the value-at-risk (VaR), a measure of the worst-case loss, for a portfolio of assets given the frequency and severity models for each asset type.
Loss severity and loss frequency are random variables, so the aggregate loss is also a random variable. Instead of preparing a point estimate of the expected aggregate loss, it is more desirable to estimate its probability distribution, because this enables you to infer various aspects of the aggregate loss such as measures of location, scale (variability), and shape in addition to percentiles. For example, the value-at-risk that banks or insurance companies use to compute regulatory capital requirements is usually the estimate of the 97.5th or 99th percentile from the aggregate loss distribution.
Let N represent the frequency random variable for the number of loss events that occur in the time period of interest. Let X represent the severity random variable for the magnitude of one loss event. Then, the aggregate loss S is defined as
![\[ S = \sum _{j=1}^{N} X_ j \]](images/etsug_hpcdm0001.png)
The goal is to estimate the probability distribution of S. Let 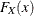 denote the cumulative distribution function (CDF) of X,
denote the cumulative distribution function (CDF) of X, 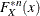 denote the n-fold convolution of the CDF of X, and
denote the n-fold convolution of the CDF of X, and 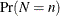 denote the probability of seeing n losses as per the frequency distribution. The CDF of S is theoretically computable as
denote the probability of seeing n losses as per the frequency distribution. The CDF of S is theoretically computable as
![\[ F_ S(s) = \sum _{n=0}^{\infty } \Pr (N=n) \cdot F_ X^{\ast n} (x) \]](images/etsug_hpcdm0005.png)
This probability distribution model of S, characterized by the CDF 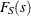 , is referred to as a compound distribution model (CDM). The HPCDM procedure computes an estimate of the CDM, given the distribution models of X and N.
, is referred to as a compound distribution model (CDM). The HPCDM procedure computes an estimate of the CDM, given the distribution models of X and N.
PROC HPCDM accepts the severity model of X as estimated by the SEVERITY procedure. It accepts the frequency model of N as estimated by the COUNTREG procedure. Both the SEVERITY and COUNTREG procedures are part of SAS/ETS software. Both procedures allow models of X and N to be conditional on external factors (regressors). In particular, you can model the severity distribution such that its scale parameter depends on severity regressors, and you can model the frequency distribution such that its mean depends on frequency regressors. The frequency model can also be a zero-inflated model. PROC HPCDM uses the estimates of model parameters and the values of severity and frequency regressors to estimate the compound distribution model.
Direct computation of 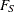 is usually a difficult task because of the need to compute the n-fold convolution. Klugman, Panjer, and Willmot (1998, Ch. 4) suggest some relatively efficient recursion and inversion methods for certain combinations of severity and frequency
distributions. However, those methods assume that distributions of N and X are fixed and all Xs are identically distributed. When the distributions of X and N are conditional on regressors, each set of regressor values results in a different distribution. So you must repeat the recursion
and inversion methods for each combination of regressor values, and this repetition makes these methods prohibitively expensive.
PROC HPCDM instead estimates the compound distribution by using a Monte Carlo simulation method, which can use all available
computational resources to generate a sufficiently large, representative sample of the compound distribution while accommodating
the dependence of distributions of X and N on external factors. Conceptually, the simulation method works as follows:
is usually a difficult task because of the need to compute the n-fold convolution. Klugman, Panjer, and Willmot (1998, Ch. 4) suggest some relatively efficient recursion and inversion methods for certain combinations of severity and frequency
distributions. However, those methods assume that distributions of N and X are fixed and all Xs are identically distributed. When the distributions of X and N are conditional on regressors, each set of regressor values results in a different distribution. So you must repeat the recursion
and inversion methods for each combination of regressor values, and this repetition makes these methods prohibitively expensive.
PROC HPCDM instead estimates the compound distribution by using a Monte Carlo simulation method, which can use all available
computational resources to generate a sufficiently large, representative sample of the compound distribution while accommodating
the dependence of distributions of X and N on external factors. Conceptually, the simulation method works as follows:
-
Use the specified frequency model to draw a value N, which represents the number of loss events.
-
Use the specified severity model to draw N values, each of which represents the magnitude of loss for each of the N loss events.
-
Add the N severity values from step 2 to compute aggregate loss S as
This forms one sample point of the CDM.
Steps 1 through 3 are repeated M number of times, where M is specified by you, to obtain the representative sample of the CDM. PROC HPCDM analyzes this sample to compute empirical
estimates of various summary statistics of the compound distribution such as the mean, variance, skewness, and kurtosis in
addition to percentiles such as the median, the 95th percentile, the 99th percentile, and so on. You can also use PROC HPCDM
to write the entire simulated sample to an output data set and to produce the plot of the empirical distribution function
(EDF), which serves as a nonparametric estimate of .
The simulation process gets more complicated when the frequency and severity models contain regression effects. The CDM is then conditional on the given values of regressors. The simulation process essentially becomes a scenario analysis, because you need to specify the expected values of the regressors that together represent the scenario for which you want to estimate the CDM. PROC HPCDM enables you to specify an input data set that contains the scenario. If you are modeling a group of entities together (such as a portfolio of multiple assets or a group of insurance policies), each with a different set of characteristics, then the scenario consists of more than one observation, and each observation corresponds to a different entity. PROC HPCDM enables you to specify such a group scenario in the input data set and performs a realistic simulation of loss events that each entity can generate.
PROC HPCDM also enables you to specify externally simulated counts. This is useful if you have an empirical frequency model or if you estimate the frequency model by using a method other than PROC COUNTREG and simulate counts by using such a model. You can specify M replications of externally simulated counts. For each of the replications, in step 1 of the simulation, instead of using the frequency model, PROC HPCDM uses the count N that you specify. If the severity model contains regression effects, then you can specify the scenario to simulate for each of the M replications.
If the parameters of your severity and frequency models have uncertainty associated with them, and they usually do, then you can use PROC HPCDM to conduct parameter perturbation analysis to assess the effect of parameter uncertainty on the estimates of CDM. If you specify that P perturbed samples be generated, then the parameter set is perturbed P times, and each time PROC HPCDM makes a random draw from either the univariate normal distribution of each parameter or the multivariate normal distribution over all parameters. For each of the P perturbed parameter sets, a full compound distribution sample is simulated and summarized. This process yields P number of estimates for each summary statistic and percentile, which are then used to provide you with estimates of the location and variability of each summary statistic and percentile.
You can also use PROC HPCDM to compute the distribution of an aggregate adjusted loss. For example, in insurance applications, you might want to compute the distribution of the amount paid in a given time period after applying adjustments such as deductible and policy limit to each individual loss. PROC HPCDM
enables you to specify SAS programming statements to adjust each severity value. If 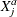 represents the adjusted severity value, then PROC HPCDM computes
represents the adjusted severity value, then PROC HPCDM computes 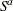 , an aggregate adjusted loss, as
, an aggregate adjusted loss, as
![\[ S^ a = \sum _{j=1}^{N} X_ j^ a \]](images/etsug_hpcdm0010.png)
All the analyses that PROC HPCDM conducts for the aggregate unadjusted loss, including scenario analysis and parameter perturbation analysis, are also conducted for the aggregate adjusted loss, thereby giving you a comprehensive picture of the adjusted compound distribution model.