The PANEL Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsMissing ValuesComputational ResourcesRestricted EstimatesNotationOne-Way Fixed-Effects ModelTwo-Way Fixed-Effects ModelBalanced PanelsUnbalanced PanelsBetween EstimatorsPooled EstimatorOne-Way Random-Effects ModelTwo-Way Random-Effects ModelParks Method (Autoregressive Model)Da Silva Method (Variance-Component Moving Average Model)Dynamic Panel EstimatorLinear Hypothesis TestingHeteroscedasticity-Corrected Covariance MatricesHeteroscedasticity- and Autocorrelation-Consistent Covariance MatricesR SquareSpecification TestsPanel Data Poolability TestPanel Data Unit Root TestsTroubleshootingCreating ODS GraphicsOUTPUT OUT= Data SetOUTEST= Data SetOUTTRANS= Data SetPrinted OutputODS Table Names
-
Example
- References
Dynamic Panel Estimator
For an example on dynamic panel estimation using GMM option, see The Cigarette Sales Data: Dynamic Panel Estimation with GMM.
Consider the case of the following general model:
|
|
The ![]() variables can include ones that are correlated or uncorrelated to the individual effects, predetermined, or strictly exogenous.
The
variables can include ones that are correlated or uncorrelated to the individual effects, predetermined, or strictly exogenous.
The ![]() and
and ![]() are cross-sectional and time series fixed effects, respectively. Arellano and Bond (1991) show that it is possible to define
conditions that should result in a consistent estimator.
are cross-sectional and time series fixed effects, respectively. Arellano and Bond (1991) show that it is possible to define
conditions that should result in a consistent estimator.
Consider the simple case of an autoregression in a panel setting (with only individual effects):
|
|
Differencing the preceding relationship results in:
|
|
where ![]() .
.
Obviously, ![]() is not exogenous. However, Arellano and Bond (1991) show that it is still useful as an instrument, if properly lagged.
is not exogenous. However, Arellano and Bond (1991) show that it is still useful as an instrument, if properly lagged.
For ![]() (assuming the first observation corresponds to time period 1) you have,
(assuming the first observation corresponds to time period 1) you have,
|
|
Using ![]() as an instrument is not a good idea since
as an instrument is not a good idea since ![]() . Therefore, since it is not possible to form a moment restriction, you discard this observation.
. Therefore, since it is not possible to form a moment restriction, you discard this observation.
For ![]() you have,
you have,
|
|
Clearly, you have every reason to suspect that ![]() . This condition forms one restriction.
. This condition forms one restriction.
For ![]() , both
, both ![]() and
and ![]() must hold.
must hold.
Proceeding in that fashion, you have the following matrix of instruments,
![\[ \mb {Z} _\mi {i} = \left( \begin{array}{*{10}{c}} \mi {y} _\mi {i1} & 0 & 0 & \cdots & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & \mi {y} _\mi {i1} & \mi {y} _\mi {i2} & 0 & \cdots & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & \mi {y} _\mi {i1} & \mi {y} _\mi {i2} & \mi {y} _\mi {i3} & 0 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & & & & \vdots & & \vdots & \vdots \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & \mi {y} _\mi {i1} & \cdots & \mi {y} _\mi {i(T-2)} \\ \end{array} \right) \]](images/etsug_panel0546.png) |
Using the instrument matrix, you form the weighting matrix ![]() as
as
|
|
The initial weighting matrix is
![\[ \mb {H} _\mi {i} = \left( \begin{array}{*{10}{r}} 2 & -1 & 0 & \cdots & 0 & 0 & 0 & 0 & 0 & 0 \\ -1 & 2 & -1 & 0 & \cdots & 0 & 0 & 0 & 0 & 0 \\ 0 & -1 & 2 & -1 & 0 & \cdots & 0 & 0 & 0 & 0 \\ \vdots & \vdots & \vdots & & & & \vdots & & \vdots & \vdots \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & -1 & 2 & -1 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & -1 & 2 \\ \end{array} \right) \]](images/etsug_panel0549.png) |
Note that the maximum size of the ![]() matrix is T–2. The origins of the initial weighting matrix are the expected error covariances. Notice that on the diagonals,
matrix is T–2. The origins of the initial weighting matrix are the expected error covariances. Notice that on the diagonals,
|
|
and off diagonals,
|
|
If you let the vector of lagged differences (in the series ![]() ) be denoted as
) be denoted as ![]() and the dependent variable as
and the dependent variable as ![]() , then the optimal GMM estimator is
, then the optimal GMM estimator is
|
|
Using the estimate, ![]() , you can obtain estimates of the errors,
, you can obtain estimates of the errors, ![]() , or the differences,
, or the differences, ![]() . From the errors, the variance is calculated as,
. From the errors, the variance is calculated as,
|
|
where ![]() is the total number of observations.
is the total number of observations.
Furthermore, you can calculate the variance of the parameter as,
|
|
Alternatively, you can view the initial estimate of the ![]() as a first step. That is, by using
as a first step. That is, by using ![]() , you can improve the estimate of the weight matrix,
, you can improve the estimate of the weight matrix, ![]() .
.
Instead of imposing the structure of the weighting, you form the ![]() matrix through the following:
matrix through the following:
|
|
You then complete the calculation as previously shown. The PROC PANEL option TWOSTEP specifies this estimation.
The case of multiple right-hand-side variables illustrates more clearly the power of Arellano and Bond (1991) and Arellano and Bover (1995).
Considering the general case you have:
|
|
It is clear that lags of the dependent variable are both not exogenous and correlated to the fixed effects. However, the independent variables can fall into one of several categories. An independent variable can be correlated and exogenous, uncorrelated and exogenous, correlated and predetermined, and uncorrelated and predetermined. The category in which an independent variable is found influences when or whether it becomes a suitable instrument. Note, however, that neither PROC PANEL nor Arellano and Bond require that a regressor be an instrument or that an instrument be a regressor.
First, consider the question of exogenous or endogenous. An exogenous variable is not correlated with the error term in the model at all. Therefore, all observations (on the exogenous variable) become valid instruments at all time periods. If the model has only one instrument and it happens to be exogenous, then the optimal instrument matrix looks like,
![\[ \mb {Z} _\mi {i} = \left( \begin{array}{*{5}{c}} \mi {x} _\mi {i1} \cdots \mi {x} _\mi {iT} & 0 & 0 & 0 & 0 \\ 0 & \mi {x} _\mi {i1} \cdots \mi {x} _\mi {iT} & 0 & 0 & 0 \\ 0 & 0 & \mi {x} _\mi {i1} \cdots \mi {x} _\mi {iTS} & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \mi {x} _\mi {i1} \cdots \mi {x} _\mi {iTS} \\ \end{array} \right) \]](images/etsug_panel0566.png) |
The situation for the predetermined variables becomes a little more difficult. A predetermined variable is one whose future realizations can be correlated to current shocks in the dependent variable. With such an understanding, it is admissible to allow all current and lagged realizations as instruments. In other words you have,
![\[ \mb {Z} _\mi {i} = \left( \begin{array}{*{5}{c}} \mi {x} _\mi {i1} & 0 & 0 & 0 & 0 \\ 0 & \mi {x} _\mi {i1} \mi {x} _\mi {i2} & 0 & 0 & 0 \\ 0 & 0 & \mi {x} _\mi {i1} \cdots \mi {x} _\mi {i3} & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \mi {x} _\mi {i1} \cdots \mi {x} _\mi {i(TS-2)} \\ \end{array} \right) \]](images/etsug_panel0567.png) |
When the data contain a mix of endogenous, exogenous, and predetermined variables, the instrument matrix is formed by combining the three. The third observation would have one observation on the dependent variable as an instrument, three observations on the predetermined variables as instruments, and all observations on the exogenous variables.
There is yet another set of moment restrictions that can be employed. An uncorrelated variable means that the variable’s level is not affected by the individual specific effect. You write the general model presented above as:
|
|
where ![]() .
.
Since the variables are uncorrelated with ![]() and uncorrelated with the error, you can perform a system estimation with the difference and level equations. That is, the
uncorrelated variables imply moment restrictions on the level equation. If you denote the new instrument matrix with the full
complement of instruments available by a
and uncorrelated with the error, you can perform a system estimation with the difference and level equations. That is, the
uncorrelated variables imply moment restrictions on the level equation. If you denote the new instrument matrix with the full
complement of instruments available by a ![]() and both
and both ![]() and
and ![]() are uncorrelated, then you have:
are uncorrelated, then you have:
![\[ \mb {Z} _\mi {i} ^{*} = \left( \begin{array}{*{5}{c}} \mb {Z} _\mi {i} & 0 & 0 & 0 & 0 \\ 0 & x^\mi {p} _\mi {i1} & x^\mi {e} _\mi {i1} & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & \cdots & x^\mi {p} _\mi {iTS} & x^\mi {e} _\mi {iTS} \\ \end{array} \right) \]](images/etsug_panel0573.png) |
The formation of the initial weighting matrix becomes somewhat problematic. If you denote the new weighting matrix with a
![]() , then you can write the following:
, then you can write the following:
|
|
where
![\[ \mb {H} _\mi {i} ^{*} = \left( \begin{array}{*{5}{c}} \mb {H} _\mi {i} & 0 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \cdots & 1 \\ \end{array} \right) \]](images/etsug_panel0575.png) |
To finish, you write out the two equations (or two stages) that are estimated.
|
|
where ![]() is the matrix of all explanatory variables, lagged endogenous, exogenous, and predetermined.
is the matrix of all explanatory variables, lagged endogenous, exogenous, and predetermined.
Let ![]() be given by
be given by
|
|
Using the information above,
|
|
If the TWOSTEP or ITGMM option is not requested, estimation terminates here. If it terminates, you can obtain the following information.
Variance of the error term comes from the second stage equation—that is,
|
|
where ![]() is the number of regressors.
is the number of regressors.
The variance covariance matrix can be obtained from
|
|
Alternatively, a robust estimate of the variance covariance matrix can be obtained by specifying the ROBUST option. Without
further reestimation of the model, the ![]() matrix is recalculated as follows:
matrix is recalculated as follows:
|
|
And the weighting matrix becomes
|
|
Using the information above, you construct the robust variance covariance matrix from the following:
Let ![]() denote a temporary matrix.
denote a temporary matrix.
|
|
The robust variance covariance estimate of ![]() is:
is:
|
|
Alternatively, the new weighting matrix can be used to form an updated estimate of the regression parameters. This results when the TWOSTEP option is requested. In short,
|
|
The variance covariance estimate of the two step ![]() becomes
becomes
|
|
As a final note, it possible to iterate more than twice by specifying the ITGMM option. Such a multiple iteration should result in a more stable estimate of the variance covariance estimate. PROC PANEL allows two convergence criteria. Convergence can occur in the parameter estimates or in the weighting matrices. Iterate until
![\[ \max _{i,j\leq \mr {dim}\left( \mb {\mi {A}} _\mb {N, k} \right) } \frac{\left| \mb {\mi {A}} _\mb {N, k+1} ^{*}(i,j)- \mb {\mi {A}} _\mb {N, k} ^{*}(i,j) \right|}{ \left| \mb {\mi {A}} _\mb {N, k} ^{*}(i,j) \right| } \leq \mr {ATOL} \]](images/etsug_panel0592.png) |
or
|
|
where ATOL is the tolerance for convergence in the weighting matrix and BTOL is the tolerance for convergence in the parameter estimate matrix. The default convergence criteria is BTOL = 1E–8 for PROC PANEL.
Specification Testing For Dynamic Panel
Specification tests under the GMM in PROC PANEL follow Arellano and Bond (1991) very generally. The first test available is a Sargan/Hansen test of over-identification. The test for a one-step estimation is constructed as
|
|
where ![]() is the stacked error term (of the differenced equation and level equation).
is the stacked error term (of the differenced equation and level equation).
When the robust weighting matrix is used, the test statistic is computed as
|
|
This definition of the Sargan test is used for all iterated estimations. The Sargan test is distributed as a ![]() with degrees of freedom equal to the number of moment conditions minus the number of parameters.
with degrees of freedom equal to the number of moment conditions minus the number of parameters.
In addition to the Sargan test, PROC PANEL tests for autocorrelation in the residuals. These tests are distributed as standard
normal. PROC PANEL tests the hypothesis that the autocorrelation of the ![]() th lag is significant.
th lag is significant.
Define ![]() as the lag of the differenced error, with zero padding for the missing values generated. Symbolically,
as the lag of the differenced error, with zero padding for the missing values generated. Symbolically,
![\[ {\bomega }_\mi {l} = \left( \begin{array}{*{1}{c}} 0 \\ \vdots \\ 0 \\ \nu _{1} \\ \vdots \\ \nu _{TS - 2 - \mi {l} } \end{array} \right) \]](images/etsug_panel0600.png) |
You define the constant ![]() as
as
|
|
You next define the constant ![]() as
as
|
|
Note that the choice of ![]() is dependent on the stage of estimation. If the estimation is first stage, then you would use the matrix with twos along
the main diagonal, and minus ones along the primary subdiagonals. In a robust estimation or multi-step estimation, this matrix
would be formed from the outer product of the residuals (from the previous step).
is dependent on the stage of estimation. If the estimation is first stage, then you would use the matrix with twos along
the main diagonal, and minus ones along the primary subdiagonals. In a robust estimation or multi-step estimation, this matrix
would be formed from the outer product of the residuals (from the previous step).
Define the constant ![]() as
as
|
|
The matrix ![]() is defined as
is defined as
|
|
The constant ![]() is defined as
is defined as
|
|
Using the four quantities, the test for autoregressive structure in the differenced residual is
|
|
The ![]() statistic is distributed as a normal random variable with mean zero and standard deviation of one.
statistic is distributed as a normal random variable with mean zero and standard deviation of one.
Instrument Choice
Arellano and Bond’s technique is a very useful method for dealing with any autoregressive characteristics in the data. However, there is one caveat to consider. Too many instruments bias the estimator to the within estimate. Furthermore, many instruments make this technique not scalable. The weighting matrix becomes very large, so every operation that involves it becomes more computationally intensive. The PANEL procedure enables you to specify a bandwidth for instrument selection. For example, specifying MAXBAND=10 means that at most there will be ten time observations for each variable that enters as an instrument. The default is to follow the Arellano-Bond methodology.
In specifying a maximum bandwidth, you can also specify the selection of the time observations. There are three possibilities: leading, trailing (default), and centered. The exact consequence of choosing any of those possibilities depends on the variable type (correlated, exogenous, or predetermined) and the time period of the current observation.
If the MAXBAND option is specified, then the following is true under any selection criterion (let ![]() be the time subscript for the current observation). The first observation for the endogenous variable (as instrument) is
max
be the time subscript for the current observation). The first observation for the endogenous variable (as instrument) is
max![]() and the last instrument is
and the last instrument is ![]() . The first observation for a predetermined variable is max
. The first observation for a predetermined variable is max![]() and the last is
and the last is ![]() . The first and last observation for an exogenous variable is given in the following list:
. The first and last observation for an exogenous variable is given in the following list:
-
Trailing: If
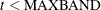 , then the first instrument is for the first time period and the last observation is
, then the first instrument is for the first time period and the last observation is 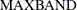 . Otherwise, if
. Otherwise, if 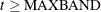 , then the first observation is
, then the first observation is 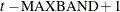 and the last instrument to enter is
and the last instrument to enter is  .
.
-
Centered: If
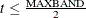 , then the first observation is the first time period and the last observation is . If
, then the first observation is the first time period and the last observation is . If 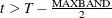 , then the first instrument included is
, then the first instrument included is 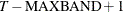 and the last observation is
and the last observation is 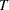 . If
. If 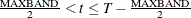 , then the first included instrument is
, then the first included instrument is 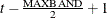 and the last observation is
and the last observation is 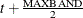 . If the value is an odd number, the procedure decrements by one.
. If the value is an odd number, the procedure decrements by one.
-
Leading : If
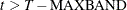 , then the first instrument corresponds to time period and the last observation is . Otherwise, if
, then the first instrument corresponds to time period and the last observation is . Otherwise, if 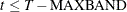 , then the first observation is and the last observation is
, then the first observation is and the last observation is 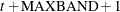 .
.
The PANEL procedure enables you to include dummy variables to deal with the presence of time effects that are not captured
by including the lagged dependent variable. The dummy variables directly affect the level equations. However, this implies
that the difference of the dummy variable for time period ![]() and
and ![]() enters the difference equation. The first usable observation occurs at
enters the difference equation. The first usable observation occurs at ![]() . If the level equation is not used in the estimation, then there is no way to identify the dummy variables. Selecting the
TIME option gives the same result as that which would be obtained by creating dummy variables in the data set and using those
in the regression.
. If the level equation is not used in the estimation, then there is no way to identify the dummy variables. Selecting the
TIME option gives the same result as that which would be obtained by creating dummy variables in the data set and using those
in the regression.
The PANEL procedure gives you several options when it comes to missing values and unbalanced panel. By default, any time period
for which there are missing values is skipped. The corresponding rows and columns of ![]() matrices are zeroed, and the calculation is continued. Alternatively, you can elect to replace missing values and missing
observations with zeros (ZERO), the overall mean of the series (OAM), the cross-sectional mean (CSM), or the time series mean
(TSM).
matrices are zeroed, and the calculation is continued. Alternatively, you can elect to replace missing values and missing
observations with zeros (ZERO), the overall mean of the series (OAM), the cross-sectional mean (CSM), or the time series mean
(TSM).