DQMATCH Procedure

Example 2: Matching Values Using Mixed Sensitivity Levels
The following example
is similar to Generate Composite Match Codes in that it displays match codes and
clusters for a simple data set. This example differs in that the CRITERIA
statement for the ADDRESS variable uses a sensitivity of 50. The CRITERIA
statement for the NAME variable uses the same default sensitivity
of 85.
The use of mixed sensitivities
enables you to tailor your clusters for maximum accuracy. In this
case, clustering accuracy is increased when the sensitivity level
of a less important variable is decreased.
This example primarily
shows how to identify possible duplicate customers based on their
names. To minimize false duplicates, minimal sensitivity is applied
to the addresses.
/* Create the input data set. */ data cust_db; length customer $ 22; length address $ 31; input customer $char22. address $char31.; datalines; Bob Beckett 392 S. Main St. PO Box 2270 Robert E. Beckett 392 S. Main St. PO Box 2270 Rob Beckett 392 S. Main St. PO Box 2270 Paul Becker 392 N. Main St. PO Box 7720 Bobby Becket 392 Main St. Mr. Robert J. Beckeit P. O. Box 2270 392 S. Main St. Mr. Robert E Beckett 392 South Main Street #2270 Mr. Raul Becker 392 North Main St. ; run; /* Run the DQMATCH procedure. */ proc dqmatch data=cust_db out=out_db2 matchcode=match_cd cluster=clustergrp locale='ENUSA'; criteria matchdef='Name' var=customer; criteria matchdef='Address' var=address sensitivity=50; run; /* Print the results. */ proc print data=out_db2; run;
Details
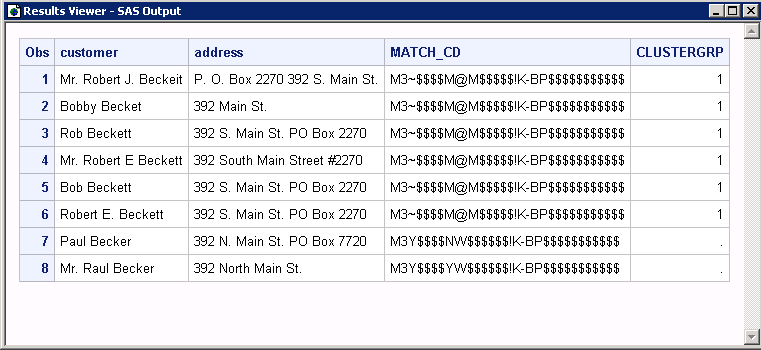
The output data set,
OUT_DB2, includes the new variables MATCH_CD and CLUSTERGRP. The MATCH_CD
variable contains the match code that represents both the customer
name and address. Because the default argument DELIMITER was used,
the resulting match code contains two match code components (one from
each CRITERIA statement) that are separated by an exclamation point.
The CLUSTERGRP variable
contains values that indicate that six of the character values are
grouped in a single cluster and that the other two are not part of
any cluster. The clustering is based on the values of the MATCH_CD
variable.
This result is different
than in Generate Composite Match Codes, where only
five values were clustered based on NAME and ADDRESS. This difference
is caused by the lower sensitivity setting for the ADDRESS criteria
in the current example. This makes the matching less sensitive to
variations in the address field. Therefore, the value Bobby Becket
has now been included in Cluster 1.392 Main St. is considered a match
with 392 S. Main St. PO Box 2270 and the other variations, this was
not true at a sensitivity of 85.