バイナリロジスティック回帰分析タスク



役割へのデータの割り当て
バイナリロジスティック回帰分析タスクを実行するには、応答変数に複数の列を割り当て、分類変数役割または連続変数役割のいずれかに1つの列を割り当てます。
|
役割
|
説明
|
|---|---|
|
役割
|
|
|
応答
|
|
|
Response data consists of numbers of events and trials
|
応答データにイベントと試行が含まれるかどうかを指定します。
|
|
イベント数
|
各オブザベーションのイベント数を表す変数を指定します。
|
|
試行数
|
各オブザベーションの試行数を表す変数を指定します。
|
|
応答
|
応答データを表す変数を指定します。バイナリロジスティック回帰分析を実行するには、応答変数のレベルが2つのみである必要があります。
関心のあるイベントドロップダウンリストを使用して、バイナリ応答モデルのイベントカテゴリを選択します。
|
|
リンク関数
|
応答確率を線形予測子にリンクするリンク関数を指定します。
有効な値は次のとおりです。
|
|
説明変数
|
|
|
分類変数
|
分析で使用する分類変数を指定します。分類変数は、統計分析またはモデルをその値ではなく、水準で入力する変数です。変数の値を水準に関連付けるプロセスを水準化と呼びます。
|
|
効果のパラメータ化
|
|
|
コーディング
|
分類変数のパラメータ化方法を指定します。選択したコーディングスキーマに従って、分類変数から設計行列の列が作成されます。
次のコーディングスキーマから選択できます。
|
|
欠損値の処理
|
|
|
次の条件のいずれかが満たされた場合、オブザベーションは分析対象から除外されます。
|
|
|
連続変数
|
分析で説明変数として使用する連続変数を指定します。
|
|
追加役割
|
|
|
度数カウント
|
各オブザベーションの出現度数を表す変数を指定します。タスクは、各オブザベーションがn回出現するものとして扱います。ここでnは、そのオブザベーションの変数の値です。
|
|
重み変数
|
入力データセットにある各オブザベーションの重み付けの程度を指定します。
|
|
グループ分析
|
BY変数の数に基づいて、個別の分析を作成します。
|
モデルの構築
ネストされた効果の作成
モデルの選択オプションの指定
|
オプション
|
説明
|
|---|---|
|
モデルの選択
|
|
|
選択方法
|
モデルのモデル選択法を指定します。このタスクでは、選択法で定義されているルールに従って、モデルに効果を追加する必要があるか、モデルから効果を削除する必要があるかを調べることによって、モデルが選択されます。
選択方法の有効な値は次のとおりです。
|
|
選択方法(続き)
|
|
|
詳細
|
|
|
選択プロセスの詳細を表示する
|
選択プロセスに関してどの程度の情報を結果に含めるかを指定します。選択プロセスの各ステップの要約または詳細を表示するか、または選択プロセスに関するすべての情報を表示するかを選択できます。
|
|
効果の階層を維持する
|
モデル階層要件の適用方法と、モデルに一度に入力または削除できる効果が1つのみか複数かを指定します。たとえば、モデルに主効果AとB、および相互作用A*Bを指定したとします。選択プロセスの最初のステップでは、AまたはBのいずれかをモデルに入力できます。2番目のステップでは、他方の主効果をモデルに入力できます。相互作用効果は、両方の主効果がすでに入力されている場合にのみ入力できます。また、モデルからAまたはBを削除する場合は、まずA*B相互作用を削除する必要があります。
モデル階層は、モデルに含まれる用語について、用語に含まれるすべての効果がモデルに存在している必要があるという要件を意味します。たとえば、相互作用A*Bをモデルに入力するためには、主効果AとBがモデルに含まれている必要があります。同様に、A*Bが存在している間は、AとBいずれの効果もモデルから削除することはできません。
|
オプションの設定
|
オプション名
|
説明
|
|---|---|
|
統計量
注: 結果に含まれるデフォルトの統計量に加えて、追加で含める統計量を選択できます。
|
|
|
分類テーブル
|
予測されたイベント確率が範囲内のカットポイント値zを上回るか下回るかに従って、入力されたバイナリ応答オブザベーションを分類します。予測イベント確率がz以上である場合、オブザベーションはイベントとして予測されます。
|
|
偏相関
|
部分相関統計を
 各パラメータiについて計算します。ここで X2iはパラメータのWaldカイ2乗統計量であり、log L0は切片専用モデルの対数尤度です(Hilbe 2009)。X2i < 2の場合、部分相関は0に設定されます。 各パラメータiについて計算します。ここで X2iはパラメータのWaldカイ2乗統計量であり、log L0は切片専用モデルの対数尤度です(Hilbe 2009)。X2i < 2の場合、部分相関は0に設定されます。
|
|
一般化寄与率
|
当てはめモデルの一般化R2乗値測定を求めます。
|
|
適合度と過分散
|
|
|
デビアンスおよびPearsonのカイ2乗統計量
|
逸脱とPearson適合度検定を計算するかどうかを指定します。
|
|
集計
|
Pearsonカイ2乗検定統計量と尤度比カイ2乗検定統計量(逸脱)が計算される部分母集団を指定します。指定された変数のリストにある共通値を持つオブザベーションは、同じ部分母集団に属していると見なされます。リストにある変数は、入力データセットのどの変数にもなりえます。
|
|
過分散補正
|
逸脱またはPearson推定を使用して過分散を修正するかどうかを指定します。
|
|
Hosmer & Lemeshow goodness-of-fit
|
バイナリ応答モデルの場合のHosmer and Lemeshow適合度検定(Hosmer and Lemeshow 2000)を実行します。被験対象は、推定確率のパーセント点に基づいて、ほぼ同じサイズの約10のグループに分割されます。これらのグループのオブザベーションの観測数と期待数の不一致は、Pearsonカイ2乗統計量によって要約されます。統計量は、次にカイ2乗分布とt自由度で比較されます。ここでtは、グループ数マイナスnです。デフォルトでは、n = 2です。小文字のp-値は、当てはめモデルが適正モデルではないことを示唆しています。
|
|
多重比較
|
|
|
多重比較の実行
|
固定効果の最小二乗平均を計算して比較するかどうかを指定します。
|
|
テストする効果を選択する
|
比較する効果を指定します。これらの効果はモデルタブで指定します。
|
|
手法
|
p-値の多重比較調整と最小二乗平均の差異の信頼限界を求めます。有効な手法は次のとおりです。Bonferroni、Nelson、Scheffé、Sidak、Tukey。
|
|
有意水準
|
各最小二乗平均にt タイプ信頼区間( 1 – numberの信頼水準)が確立されることが求められます。numberの値は0から1の間である必要があります。デフォルト値は、0.05です。
|
|
正確検定
|
|
|
切片の正確検定
|
切片の正確検定を計算します。
|
|
テストする効果を選択する
|
選択した効果のパラメータの正確検定を計算します。
|
|
有意水準
|
パラメータ比またはオッズ比の
 信頼限界の有意水準 信頼限界の有意水準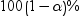 を指定します。 を指定します。
|
|
パラメータ推定値
|
|
|
次のパラメータ推定値を計算できます。
パラメータの信頼区間、オッズ比の信頼区間、およびこれらの推定値の信頼水準を指定できます。
|
|
|
診断
|
|
|
影響度診断
|
影響が大きいと見なされるオブザベーションの診断測定を表示します。各オブザベーションについて、結果にはオブザベーションのシーケンス番号、最終モデルに含まれる説明変数の値、およびPregibon
(1981)により考案された回帰診断測定が含まれています。標準化された残差と尤度残差を含めるかどうかを指定できます。
|
|
ブロット
|
|
|
結果にプロットを含めるかどうかを選択できます。
結果に含めることができる追加のプロットは次のとおりです。
これらのプロットをパネルに表示するか、個別に表示するかを指定できます。
|
|
|
影響度とROCプロットのラベル
|
影響度プロットとROCプロットのラベルを含む入力データの変数を指定します。
|
|
プロットポイントの最大数
|
プロットに含める最大点数を指定します。デフォルトでは、5,000点が表示されます。
|
|
手法
|
|
|
最適化
|
|
|
手法
|
回帰パラメータを推定するための最適化技術を指定します。FisherスコアリングとNewton-Raphsonアルゴリズムでは同じ推定値がを求められますが、バイナリ応答データにロジットリンク関数が指定されている場合以外は、推定される共分散行列に若干の差異があります。
|
|
最大反復回数
|
実行する最大反復回数を指定します。指定した回数の反復によって収束できない場合、タスクによって作成された表示出力とすべての出力データセットには、最後の最大尤度反復に基づく結果が含まれます。
|
出力データセットの作成
|
オプション名
|
説明
|
|---|---|
|
出力データセット
|
|
|
2種類の出力データセットを作成できます。作成する各データセットのチェックボックスを選択します。
出力データセットの作成
指定した統計量を含むデータセットを出力します。
出力データセットに含めることができる統計量は次のとおりです。
スコアリングされたデータセットの作成
出力データセットと事後確率のすべての統計量を含むデータセットを出力します。
|
|
|
SAS スコアリングコードをログに追加する
|
ファイルまたはカタログエントリのいずれかへの当てはめモデルの予測値を計算するためのSAS DATAステップコードを記述します。このコードは、さらに新しいデータにスコア付けするためのDATAステップに含めることができます。
|