予測回帰モデル


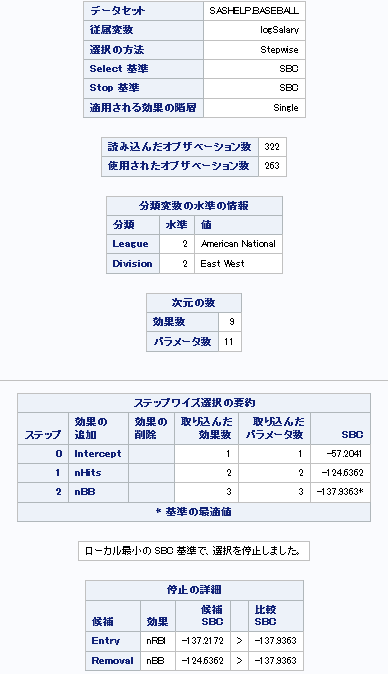
データの分割
十分なデータがある場合には、そのデータをトレーニングデータ、検証データおよび検定データの3つの部分に分割できます。選択プロセスでは、トレーニングデータにモデルが当てはめられ、検証データを使用してそのモデルの予測誤差が決定されます。この予測誤差は、その選択プロセスを終了するタイミングや、選択プロセスの進行時に追加すべき効果の決定に使用できます。最後に、任意のモデルが選択されたら、検証データを使用して、モデルの選択時に何の役割も果たさなかったデータに対してそのモデルがどのように一般化できるかを評価します。
データは、次のいずれかの方法で分割できます。
-
検証データまたは検定データの比率を指定します。この比率は、サンプリングによって入力データを分割する際に使用されます。
-
任意のオブザベーションが検証事例であるか、検定事例であるかを示す値を持つ変数が入力データセットに含まれている場合は、データの分割時にその変数を指定できます。変数を指定する場合には、検証事例または検定事例に適切な値も選択します。入力データセットは、このような値を使用して分割されます。
役割へのデータの割り当て
予測回帰モデルタスクを実行するには、従属変数役割に1つの列を割り当て、分類変数役割または連続変数役割に1つの列を割り当てる必要があります。
|
役割
|
説明
|
|---|---|
|
役割
|
|
|
従属変数
|
回帰分析の従属変数として使用する数値変数を指定します。
|
|
分類変数
|
分析でデータのグループ化(分類)に使用する変数を指定します。分類変数は、統計分析またはモデルをその値ではなく、水準で入力する変数です。変数の値を水準に関連付けるプロセスを水準化と呼びます。
|
|
効果のパラメータ化
|
|
|
コーディング
|
分類変数のパラメータ化方法を指定します。選択したコーディングスキーマに従って、分類変数から設計行列の列が作成されます。
次のコーディングスキーマから選択できます。
|
|
欠損値の処理
|
|
|
モデル内の変数に欠損値が含まれる場合、オブザベーションは分析対象から除外されます。また、このテーブルで前に指定した分類変数のいずれかに欠損値が含まれる場合は、その値をモデルで使用しているかどうかに関係なくオブザベーションは除外されます。
|
|
|
連続変数
|
回帰分析モデルの独立共変量(回帰変数)を指定します。連続変数を指定しない場合、タスクでは切片のみを使用するモデルの当てはめを行います。
|
|
追加役割
|
|
|
度数カウント
|
オブザベーションの度数を表す数値変数を指定します。この役割に変数を割り当てると、各オブザベーションがn件のオブザベーションを表すものとされます。nは、度数変数の値です。nが整数以外の場合、自動的に切り捨てられます。nが1未満か、欠損している場合、そのオブザベーションは分析から除外されます。度数変数の合計は、オブザベーションの合計数を表します。
|
|
重み
|
データの重み付き分析を実行する際に重みとして使用する数値列を指定します。
|
|
グループ分析
|
オブザベーションの各グループについてそれぞれ個別の分析を作成することを指定します。
|
モデルの構築
ネストされた効果の作成
モデルの選択
|
オプション名
|
説明
|
|---|---|
|
モデルの選択
|
|
|
選択方法
|
デフォルトでは、指定した完全モデルを使用してモデルの当てはめが行われます。ただし、次の選択方法のいずれかを使用することもできます。
|
|
選択方法(続き)
|
変数増加法
変数増加法を指定します。この方法では、効果なしのモデルから開始し、効果を追加します。
変数減少法
変数減少法を指定します。すべての効果を含むモデルから開始し、効果を削除します。
ステップワイズ回帰法
ステップワイズ回帰法を指定します。この方法は変数増加法に似ていますが、モデルにすでに存在する効果が必ずしもそのまま残らないという点で異なります。
LASSO
LASSO法を指定します。この方法では、絶対回帰係数の和が制限される最小二乗のバージョンに基づいてパラメータが追加および削除されます。モデルに分類変数が含まれる場合、それらの分類変数は分割されます。
Adaptive LASSO
LASSO法の各係数に適合型重みを適用するよう要求します。モデルのパラメータの最小二乗推定値は適合型重みの作成で使用されます。
|
|
選択方法(続き)
|
弾性ネット
elastic net法を指定します。この方法はLASSOを拡張したものです。elastic net法では、絶対回帰係数の和と二乗回帰係数の和の両方が制限される最小二乗のバージョンに基づいてパラメータが推定されます。モデルに分類変数が含まれる場合、それらの分類変数は分割されます。
Least angle regression
最小角度回帰を指定します。この方法では、効果なしのモデルから開始し、効果を追加します。対応する最小二乗推定値と比較する際にいずれかの段階のパラメータ推定値が"縮小"されます。モデルに分類変数が含まれる場合、それらの分類変数は分割されます。
|
|
効果の追加/削除法
|
モデルに対して効果を追加または削除するかどうかを決定するための基準を指定します。
|
|
効果の追加/削除の停止法
|
モデルに対する効果の追加または削除を停止するかどうかを決定するための基準を指定します。
|
|
最適モデルの選択方法
|
最も当てはまるモデルを決定するための基準を指定します。
|
|
統計量の選択
|
|
|
モデルの当てはまりに関する統計量
|
当てはめ要約テーブルと当てはめ統計テーブルに表示するモデル当てはめ統計量を指定します。デフォルトの当てはめの統計量を選択した場合、これらのテーブルに表示される統計量のデフォルトセットには、モデルの選択で使用されるすべての基準が含まれます。
結果に含めることのできる追加の当てはめ統計量を次に示します。
|
|
選択プロット
|
|
|
基準プロット
|
調整済みR2乗値、赤池の情報量規準、小サンプルバイアス用に修正された赤池の情報規準および最も当てはまるモデルの選択に使用する規準のプロットを表示します。これらのプロットをパネルに表示するか、個別に表示するかを選択できます。
|
|
係数プロット
|
次のプロットを表示します。
|
|
詳細
|
|
|
選択プロセスの詳細
|
選択プロセスに関してどの程度の情報を結果に含めるかを指定します。選択プロセスの各ステップの要約または詳細、または選択プロセスに関するすべての情報を表示できます。
|
|
分類効果の追加/削除
|
どの分類変数を1つまたは複数の実際の変数としてモデルに含めるかを指定します。変数の数は、分類変数の水準の数に関係しています。たとえば、分類変数に3つの水準(若年、中年、老年)がある場合、3つの変数で表されることがあります。各変数は、1自由度の効果です。
次のオプションのいずれかを選択できます。
|
|
モデル効果の階層
|
|
|
モデル効果の階層
|
モデル階層要件の適用方法と、モデルに一度に入力または削除できる効果が1つのみか複数かを指定します。たとえば、モデルに主効果AとB、および相互作用A*Bを指定したとします。選択プロセスの最初のステップでは、AまたはBのいずれかをモデルに入力できます。2番目のステップでは、他方の主効果をモデルに入力できます。相互作用効果は、両方の主効果がすでに入力されている場合にのみ入力できます。また、モデルからAまたはBを削除する場合は、まずA*B相互作用を削除する必要があります。
モデル階層は、モデルに含まれる用語について、用語に含まれるすべての効果がモデルに存在している必要があるという要件を意味します。たとえば、相互作用A*Bをモデルに入力するためには、主効果AとBがモデルに含まれている必要があります。同様に、A*Bが存在している間は、AとBいずれの効果もモデルから削除することはできません。
|
|
Model effects subject to the hierarchy requirement
|
モデル階層要件をモデル内の分類効果と連続効果に適用するか、または分類効果のみに適用するかを指定します。
|
最終モデルのオプションの設定
|
オプション名
|
説明
|
|---|---|
|
選択済みモデルの統計量
|
|
|
結果にデフォルトの統計量を含めるか、または追加統計量(標準回帰係数など)を含めるかを選択できます。標準回帰係数は、回帰変数のサンプル標準偏差に対する従属変数のサンプル標準偏差の比率によってパラメータ推定値を割ることによって計算されます。
|
|
|
共線性
|
|
|
共線性分析
|
回帰変数間の詳細な共線性分析を要求します。固有値、条件インデックス、および各固有値に対する推定値の分散分解などが挙げられます。
|
|
推定値のトレランス値
|
推定値のトレランス値を作成します。変数のトレランスは、
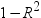 として定義されます。R2乗値は、モデルの他のすべての回帰変数に対する変数の回帰から得られます。 として定義されます。R2乗値は、モデルの他のすべての回帰変数に対する変数の回帰から得られます。
|
|
分散拡大係数
|
パラメータ推定値の分散拡大係数を作成します。分散拡大はトレランスの逆数です。
|
|
選択済みモデルのプロット
|
|
|
診断と残差プロット
|
|
|
結果にデフォルトの診断プロットを含めるかどうかを指定できます。説明変数の残差のプロットを含めるかどうかを指定することもできます。
|
|
|
その他の診断プロット
|
|
|
Rstudent統計量と予測値
|
予測値でスチューデント化残差をプロットします。極値ポイントのラベルオプションを選択した場合、参照線
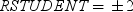 の帯域から外れるスチューデント化残差は異常値と見なされます。 の帯域から外れるスチューデント化残差は異常値と見なされます。
|
|
DFFITS 統計量とオブザベーション番号
|
DFFITS統計量とオブザベーション番号をプロットします。極値ポイントのラベルオプションを選択した場合、DFFITS統計量の大きさが
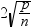 を超えるオブザベーションは影響因子と見なされます。使用されるオブザベーションの数はnで、回帰変数の数はpです。 を超えるオブザベーションは影響因子と見なされます。使用されるオブザベーションの数はnで、回帰変数の数はpです。
|
|
説明変数ごとの DFBETAS 統計量とオブザベーション番号
|
モデルの各回帰変数について、オブザベーション番号に対するDFBETASを示すパネルを作成します。これらのプロットはパネルとして表示することも、個々のプロットとして表示することもできます。極値ポイントのラベルオプションを選択した場合、DFBETAS統計量の大きさが
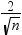 を超えるオブザベーションは該当する回帰変数に対する影響因子と見なされます。オブザベーションの数はnです。 を超えるオブザベーションは該当する回帰変数に対する影響因子と見なされます。オブザベーションの数はnです。
|
|
極値ポイントのラベル
|
プロットの各タイプの極値を識別します。
|
|
散布図
|
|
|
観測値と予測値
|
予測値に対する観測値の散布図を作成します。
|
|
説明変数ごとの偏回帰プロット
|
各回帰変数の偏回帰プロットを作成します。これらのプロットをパネルに表示する場合は、パネル1つ当たりの回帰変数数は最大で6つになります。
|
|
プロットポイントの最大数
|
各プロットに含める最大点数を指定します。
|