線形回帰分析タスク


役割へのデータの割り当て
線形回帰分析タスクを実行するには、従属変数役割に1つの列を割り当て、分類変数役割または連続変数役割に1つの列を割り当てる必要があります。
|
役割
|
説明
|
|---|---|
|
役割
|
|
|
従属変数
|
回帰分析の従属変数として使用する数値変数を指定します。この役割には数値変数を割り当てる必要があります。
|
|
分類変数
|
設計行列コードを使って回帰分析モデルを入力する分類変数を指定します。
|
|
効果のパラメータ化
|
|
|
コーディング
|
分類変数のパラメータ化方法を指定します。選択したコーディングスキーマに従って、分類変数から設計行列の列が作成されます。
次のコーディングスキーマから選択できます。
|
|
欠損値の処理
|
|
|
次の条件のいずれかが満たされた場合、オブザベーションは分析対象から除外されます。
|
|
|
連続変数
|
回帰分析モデルの数値共変量(回帰変数)を指定します。
|
|
追加役割
|
|
|
度数カウント
|
オブザベーションの度数を表す数値変数を指定します。この役割に変数を割り当てると、各オブザベーションがn件のオブザベーションを表すものとされます。nは、度数変数の値です。nが整数以外の場合、自動的に切り捨てられます。nが1未満か、欠損している場合、そのオブザベーションは分析から除外されます。度数変数の合計は、オブザベーションの合計数を表します。
|
|
体重
|
データの重み付き分析を実行する際に重みとして使用する変数を指定します。
|
|
グループ分析
|
オブザベーションの各グループについてそれぞれ個別の分析を作成することを指定します。
|
モデルの構築
ネストされた効果の作成
モデルオプションの設定
|
オプション名
|
説明
|
|---|---|
|
手法
|
|
|
信頼水準
|
信頼区間の作成に使用する有意水準を指定します。
|
|
統計量
|
|
|
結果にデフォルトの統計量を含めるか、または追加統計量を含めるかを選択できます。
|
|
|
パラメータ推定値
|
|
|
標準回帰係数
|
標準回帰係数を表示します。標準回帰係数は、回帰変数のサンプル標準偏差に対する従属変数のサンプル標準偏差の比率によってパラメータ推定値を割ることによって計算されます。
|
|
推定値の信頼限界
|
パラメータ推定値の
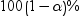 上側信頼限界と下側信頼限界を表示します。 上側信頼限界と下側信頼限界を表示します。
|
|
平方和
|
|
|
逐次平方和(Type I)
|
モデルの項ごとにパラメータ推定値と一緒に逐次平方和(Type I SS)を表示します。
|
|
偏平方和(Type II)
|
モデルの項ごとにパラメータ推定値と一緒に偏平方和(Type II SS)を表示します。
|
|
偏相関と半偏相関
|
|
|
平方偏相関
|
Type IとType IIの平方和を使用して計算される平方偏相関係数を表示します。
|
|
平方半偏相関
|
Type IとType IIの平方和を使用して計算される平方半偏相関係数を表示します。この値は、平方和を修正済み平方和合計で割ることによって計算されます。
|
|
診断
|
|
|
Analysis of influence
|
推定値と予測値に各オブザベーションが与える影響の詳細な分析を要求します。
|
|
Analysis of residuals
|
残差の分析を要求します。結果には、入力データと推定されたモデルからの予測値、平均の予測値と残差値の標準誤差、スチューデント化残差、およびパラメータ推定値への各オブザベーションの影響を評価するCookのD統計量が含まれます。
|
|
予測値
|
入力データと推定されたモデルから予測値を計算します。
|
|
多重比較
|
|
|
多重比較の実行
|
固定効果の最小二乗平均を計算して比較するかどうかを指定します。
|
|
テストする効果を選択する
|
比較する効果を指定します。これらの効果はモデルタブで指定します。
|
|
手法
|
p-値の多重比較調整と最小二乗平均の差異の信頼限界を求めます。有効な手法は次のとおりです。Bonferroni、Nelson、Scheffé、Sidak、Tukey。
|
|
有意水準
|
各最小二乗平均に1 – numberの信頼水準のtタイプ信頼区間が確立されることが求められます。numberの値は0~1の間である必要があります。デフォルト値は、0.05です。
|
|
共線性
|
|
|
共線性分析
|
回帰変数間の詳細な共線性分析を要求します。固有値、条件インデックス、および各固有値に対する推定値の分散分解などが挙げられます。
|
|
推定値のトレランス値
|
推定値のトレランス値を作成します。変数のトレランスは、
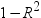 として定義されます。R2乗値は、モデルの他のすべての回帰変数に対する変数の回帰から得られます。 として定義されます。R2乗値は、モデルの他のすべての回帰変数に対する変数の回帰から得られます。
|
|
分散拡大係数
|
パラメータ推定値の分散拡大係数を作成します。分散拡大はトレランスの逆数です。
|
|
不等分散性
|
|
|
不等分散性分析
|
モデルの一次モーメントと二次モーメントが正しく指定されていることを確認する検定を実行します。
|
|
漸近共分散行列
|
不等分散性仮説下での推定値の漸近共分散行列とパラメータ推定値の不等分散一致標準誤差を表示します。
|
|
ブロット
|
|
|
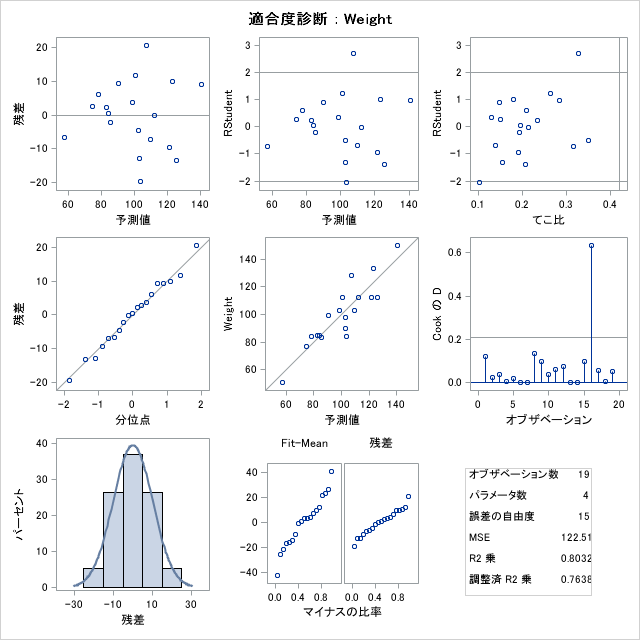
診断と残差プロット
|
|
|
デフォルトでは、いくつかの診断プロットが結果に含まれます。説明変数の残差のプロットを含めるかどうかを指定することもできます。
|
|
|
その他の診断プロット
|
|
|
Rstudent統計量と予測値
|
予測値でスチューデント化残差をプロットします。極値ポイントのラベルオプションを選択した場合、参照線
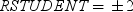 の帯域から外れるスチューデント化残差は異常値と見なされます。 の帯域から外れるスチューデント化残差は異常値と見なされます。
|
|
DFFITS統計量とオブザベーション番号
|
DFFITS統計量とオブザベーション番号をプロットします。極値ポイントのラベルオプションを選択した場合、DFFITS統計量の大きさが
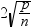 を超えるオブザベーションは影響因子と見なされます。使用されるオブザベーションの数はnで、回帰変数の数はpです。 を超えるオブザベーションは影響因子と見なされます。使用されるオブザベーションの数はnで、回帰変数の数はpです。
|
|
説明変数ごとの DFBETAS 統計量とオブザベーション番号
|
モデルの各回帰変数について、オブザベーション番号に対するDFBETASを示すパネルを作成します。これらのプロットはパネルとして表示することも、個々のプロットとして表示することもできます。極値ポイントのラベルオプションを選択した場合、DFBETAS統計量の大きさが
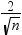 を超えるオブザベーションは該当する回帰変数に対する影響因子と見なされます。オブザベーションの数はnです。 を超えるオブザベーションは該当する回帰変数に対する影響因子と見なされます。オブザベーションの数はnです。
|
|
極値ポイントのラベル
|
プロットの各タイプの極値を識別します。
|
|
散布図
|
|
|
単一連続変数の当てはめプロット
|
単一の連続変数を持つモデルの回帰線、信頼帯および予測帯とデータを重ね合わせた散布図を作成します。切片は除外されます。点の数がプロットポイントの最大数オプションの値を超える場合は、散布図の代わりにヒートマップが表示されます。
|
|
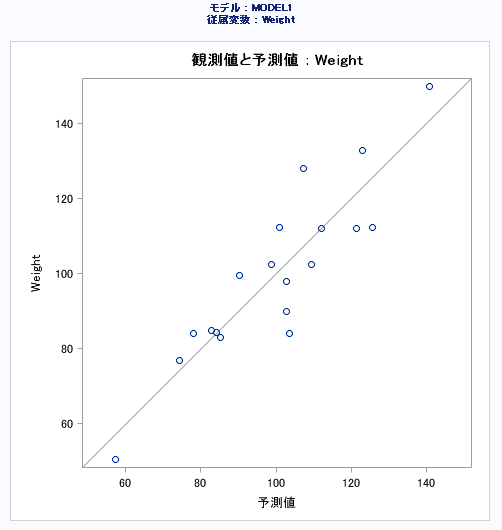
観測値と予測値
|
予測値に対する観測値の散布図を作成します。
|
|
説明変数ごとの偏回帰プロット
|
各回帰変数の偏回帰プロットを作成します。これらのプロットをパネルに表示する場合は、パネル1つ当たりの回帰変数数は最大で6つになります。
|
|
プロットポイントの最大数
|
各プロットに含める最大点数を指定します。
|
モデルの選択オプションの設定
|
オプション
|
説明
|
|---|---|
|
モデルの選択
|
|
|
選択方法
|
モデルのモデル選択法を指定します。このタスクでは、選択法で定義されているルールに従って、モデルに効果を追加する必要があるか、モデルから効果を削除する必要があるかを調べることによって、モデルが選択されます。
選択方法の有効な値は次のとおりです。
|
|
効果の追加/削除法
|
モデルに対して効果を追加または削除する際の基準を指定します。
|
|
効果の追加/削除の停止法
|
モデルに対する効果の追加または削除を停止する際の基準を指定します。
|
|
最適モデルの選択方法
|
最も当てはまるモデルが識別されるようにするための基準を指定します。
|
|
統計量の選択
|
|
|
モデルの当てはまりに関する統計量
|
当てはめ要約テーブルと当てはめ統計テーブルに表示するモデル当てはめ統計量を指定します。デフォルトの当てはめの統計量を選択した場合、これらのテーブルに表示される統計量のデフォルトセットには、モデルの選択で使用されるすべての基準が含まれます。
結果に含めることのできる追加の当てはめ統計量を次に示します。
|
|
選択プロット
|
|
|
基準プロット
|
調整済みR2乗値、赤池の情報量規準、小サンプルバイアス用に修正された赤池の情報規準および最も当てはまるモデルの選択に使用する規準のプロットを表示します。
|
|
係数プロット
|
次のプロットを表示します。
|
|
詳細
|
|
|
選択プロセスの詳細
|
選択プロセスに関してどの程度の情報を結果に含めるかを指定します。選択プロセスの各ステップの要約または詳細、または選択プロセスに関するすべての情報を表示できます。
|