データのランクタスク
例:生徒を身長と年齢でランク付けする

役割へのデータの割り当て
データのランクタスクを実行するには、ランク付けを行う列役割に列を割り当てる必要があります。
|
役割
|
説明
|
|---|---|
|
役割
|
|
|
ランク付けを行う列
|
この役割に割り当てられる各列がランク付けされます。この役割には、少なくとも1つの変数を割り当てる必要があります。デフォルトでは、ランク付けされた列には、rank_column-nameという名前が付けられます。ここで、column-nameは、列の元の名前です。
|
|
追加役割
|
|
|
グループ変数
|
この役割に1つ以上の列を割り当てると、選択した1つ以上の列によって入力テーブルが並べ替えられ、各グループ内でランクが計算されます。
|
|
出力データセット
|
|
|
ランク付けした変数に新しい変数を作成する
|
出力テーブルに元の列とランク付けされた列を含めることを指定します。元の列をランク付けされた列で置き換える必要がある場合は、ランク付けした変数に新しい変数を作成するチェックボックスをクリアします。
デフォルトで、ランク付けされた列には、rank_column-nameという名前が付けられます。ここで、column-nameは、元の列の名前です。
|
|
出力データを表示する
|
結果に出力データのすべてまたはサブセットを表示するかどうかを指定します。
|
オプションの設定
少なくとも1つの出力オプションを選択する必要があります。
|
オプション名
|
説明
|
|---|---|
|
オプション
|
|
|
ランク付けの方法
|
データのランク付けを実行する際に使用する方法を指定します。有効な値は次のとおりです。
ランク
元の値を100個のグループに分割します。これらのグループでは、最小の値にパーセント点値0が付与され、最大の値にパーセント点値99が付与されます。
分位点
元の値をこれらの分位点のいずれかに分割します。
|
|
ランク付けの方法(続き)
|
分数順位
分母NまたはN+1のいずれかを使用して、分数順位を計算します。分母Nは、各ランクを、ランク付け変数の非欠損値を持つオブザベーションの数で割って、分数順位を計算します。分母N+1は、各ランクを、分母n+1 (ここで、nはランク付け変数の非欠損値を持つオブザベーションの数)で割って、分数順序を計算します。
パーセント
各ランクを、変数の非欠損値を持つオブザベーションの数で割り、その結果に100を掛けてパーセント値を求めます。
|
|
ランク付けの方法(続き)
|
ランクの正規スコア
ランクから正規スコアを計算します。結果変数は、正規分布で表示されます。式は次のとおりです。
Blom式
Tukey式
van der Waerden式
これらの式で、
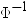 は累積正規分布関数の逆関数(PROBIT)で、riはi番目のオブザベーションのランク、nはランク付け変数の非欠損オブザベーションの数を表します。 は累積正規分布関数の逆関数(PROBIT)で、riはi番目のオブザベーションのランク、nはランク付け変数の非欠損オブザベーションの数を表します。
注: タイ値の場合、次の方法を使用するオプションを設定した場合、データのランクタスクでは、タイ値以外の値に基づいて、ランクから正規スコアを計算し、その結果得られるスコアにタイ値指定を適用します。
ランクの Savage スコア
ランクからSavage(指数)スコアを計算します。
注: タイ値の場合、次の方法を使用するオプションを設定した場合、データのランクタスクでは、タイ値以外の値に基づいて、ランクからSavageスコアを計算し、その結果得られるスコアにタイ値指定を適用します。
|
|
タイ値の場合、次の方法を使用する
|
タイ値となるデータについて正規スコアまたはランクの計算方法を指定します。
デフォルトの方法
ランク付けの方法にデフォルトの方法を割り当てます。ランク付け方法としてパーセントまたは分数順位を選択すると、高値がデフォルトになります。他のすべてのランク付け方法については、平均がデフォルトです。
平均順位
対応するランクまたは正規スコアの平均を割り当てます。
高順位
対応するランクまたは正規スコアの最大値を割り当てます。
低順位
対応するランクまたは正規スコアの最小値を割り当てます。
Dense順位(タイは同じ順位)
タイ値を単一順位の統計量として取り扱うことによりスコアおよびランクを計算します。デフォルトの方法の場合、ランクは、1で始まり、ランク付け対象の変数の一意の非欠損値の数で終わる連続した整数です。タイ値には、同じランクが割り当てられます。
|
|
ランク順
|
値を最小値から最大値の順にリストするか、最大値から最小値の順にリストするかを指定します。
|