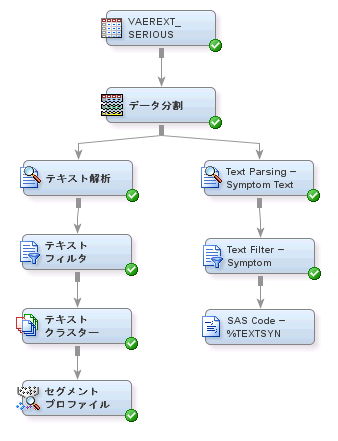
新しい類義語データセットの作成
SAS Text Minerの%TEXTSYNマクロを使用すると、新しい類義語データセットを作成できます。%TEXTSYNマクロはすべての語を評価することにより、スペルが間違っている語を自動的に特定し、正しいスペルの語を誤ったスペルの語に対応付ける類義語リストを作成します。
新しい類義語データセットを作成するには、次の操作を実行します。
-
%textsyn( termds=<libref>.<nodeID>_terms , docds=&em_import_data , outds=&em_import_transaction , textvar=symptom_text , mnpardoc=8 , mxchddoc=10 , synds=mylib.vaerextsyns , dict=mylib.engdict , maxsped=15 ) ;注: 上記のプログラム内の最初の行に含まれている<libref>と<nodeID>は、それぞれ各自が使用する正しいライブラリ名とノードIDで置き換える必要があります。これらの値が何であるかを決定するには、コードエディタウィンドウを閉じた後、Text Filter — Symptom TextノードをSAS Code — %TEXTSYNノードに接続している矢印を選択します。<libref>の値は、プロパティパネルに表示されているテーブル名の先頭部分になります(emwsやemws2など)。ノードIDは、<libref>値の後に表示されているものであり、TextFilterやTextFilter2などになります。<libref>と<nodeID>の値を正しい値で置き換えた場合、先頭行はtermds=emws2.textfilter2_termsのようになります。実際のライブラリ参照名とノードIDの値は、どれだけの数のテキストフィルタノードとダイアグラムが各自のワークスペース内に作成されているかによって異なります。%TEXTSYNマクロに関する詳細は、SAS Text Minerのヘルプを参照してください。 -
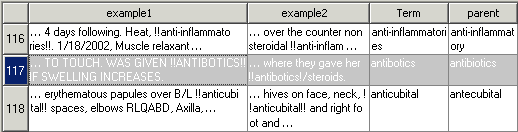
Vaerextsyns列の内容を次に示します。
-
Termはスペルが誤っている語です。
-
parentは、その語の正しいスペルであると推測された値です。
-
example1とexample2は、ドキュメント内にある語を表す2つの例です。
-
childndocsは、スペルが間違っている語を含んでいたドキュメントの数です。
-
numdocsは、parentを含んでいたドキュメントの数です。
-
minspedは、これらの語がどれだけ近似しているかを表す指標です。
-
dictは、その語が正しい英語の単語であるかどうかを示します。正しい単語であってもスペルが間違っていると判断される場合もありますが、そのようなケースが稀であるならば、正しい単語は頻繁にターゲットとなる語のスペルに非常に近くなります。
たとえば、オブザベーション117では、antiboticsはantibioticsのスペルミスであると示されています。これは、antiboticsは4つのドキュメントにしか含まれていないのに、そのparentであるantibioticsは745件のドキュメントに含まれているためです。スペルが間違っている語は、2個の連続する感嘆符(!!)で囲まれていることに注意してください。 -