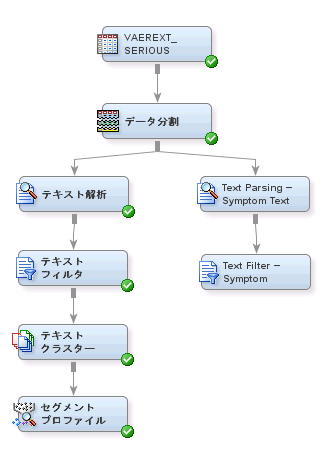
新しい類義語データセットを使用するには、次の操作を実行します。
-
テキスト解析ノードを右クリックし、
コピーを選択します。
この例では、新しいテキスト解析ノードを作成する代わりに、既存のノードをコピーします。これは、以前にテキスト解析ノードのプロパティパネルで指定した設定が使われるようにするためです。
-
空のダイアグラムワークスペースを右クリックし、
ペーストを選択します。
-
この新しくペーストされた
テキスト解析ノードをコピー元のノードから区別するために、新しいノードを右クリックし、
名前の変更を選択します。
-
ノード名フィールドに
Text
Parsing — Symptom Textと入力した後、
OKをクリックします。
-
テキストフィルタノードを右クリックし、
コピーを選択します。
この例では、新しいテキストフィルタノードを作成する代わりに、既存のノードをコピーします。これは、以前にテキストフィルタノードのプロパティパネルで指定した設定が使われるようにするためです。
-
空のダイアグラムワークスペースを右クリックし、
ペーストを選択します。
-
この新しくペーストされた
テキストフィルタノードをコピー元のノードから区別するために、新しいノードを右クリックし、
名前の変更を選択します。
-
ノード名フィールドに
Text
Filter — Symptom Textと入力した後、
OKをクリックします。
-
データ分割ノードを
Text Parsing — Symptom Textノードに接続します。
-
Text Parsing — Symptom Textノードを
Text Filter — Symptom Textノードに接続します。
-
Text Parsing — Symptom Textノードを選択します。
-
類義語プロパティの

を選択します。
ダイアログボックスが表示されます。
-
SASテーブルの選択ダイアログボックスが表示されます。
-
フォルダツリーから
Mylibライブラリを選択します。
Mylibライブラリの内容が表示されます。
-
Vaer_abbrevを選択して
OKをクリックします。
Vaer_abbrevデータソースの内容がダイアログボックスに表示されます。
-
-
その他のすべての設定は、元のテキスト解析ノードの設定と同じままにします。
-
ダイアグラムワークスペース内にある
Text Filter — Symptomノードを右クリックし、
実行を選択します。
確認ダイアログボックスで
はいを選択します。
-
同ノードの実行完了後に表示される
実行ステータスダイアログボックス内で
OKをクリックします。
-
Text Filter — Symptom Textノードの
フィルタビューアプロパティの
をクリックします。
対話型のフィルタ ビューアウィンドウが表示されます。
-
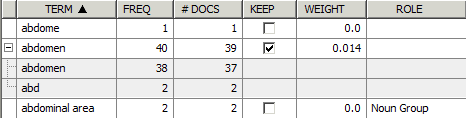
TERM列見出しをクリックして、語テーブルを頻度順に並べ替えます。
-
たとえば、
語ウィンドウのTERM列の下にある
abdomenを選択します。
語を表示するために下スクロールが必要となる場合があります。語ウィンドウで、abdomenの隣にプラス記号(+)が表示されます。このプラス記号をクリックすると、この語を展開できます。これにより、この語に対応付けられているすべての類義語や語幹が表示されます。語幹とは、語の原形です。展開された語としてabdが含まれています。abdomenとabdは両方とも同じものとして扱われます。
-