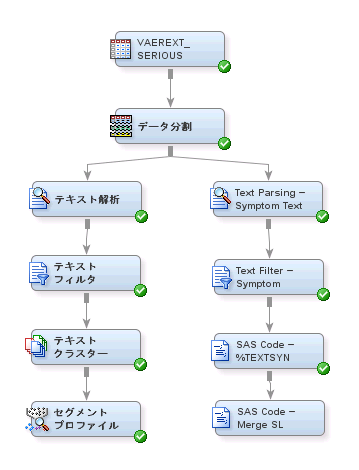
この一連のタスクでは、Mylib.VaerextsynsデータセットとMylib.Vaer_abbrevデータセットの両方に含まれているすべてのオブザベーションを含む新しデータセットを作成します。その後、このマージされた類義語データセットを使用して結果を調べます。次の手順を実行します。
-
ノードツールバー上で
ユーティリティタブを選択し、
SASコードノードをダイアグラムワークスペースへとドラッグします。
-
SASコードノードを右クリックし、
名前の変更選択します。
-
ノード名フィールドに
SAS
Code — Merge SLと入力した後、
OKをクリックします。
SLはSynonym Listsを意味します。
-
SAS Code — %TEXTSYNノードを
SAS Code — Merge SLノードに接続します。
-
SAS Code — Merge SLノードを選択します。
-
コードエディタプロパティの

をクリックします。
コードエディタが表示されます。
-
data mylib.vaerextsyns_new;
set mylib.vaerextsyns mylib.vaer_abbrev;
run;
このプログラムは、最初のSAS Code — %TEXTSYNノードで作成された類義語データセットを、略語データセットとマージします。
-

をクリックします。
-
-
SAS Code — Merge SLノードを右クリックし、
実行を選択します。
確認ダイアログボックスで
はいを選択します。
-
同ノードの実行完了後に表示される
実行ステータスダイアログボックス内で
結果をクリックします。
-
結果ウィンドウで
表示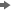 SAS結果ログ
SAS結果ログを選択し、新しいデータセットを作成するSASコードを確認します。
結果ウィンドウを閉じます。
-
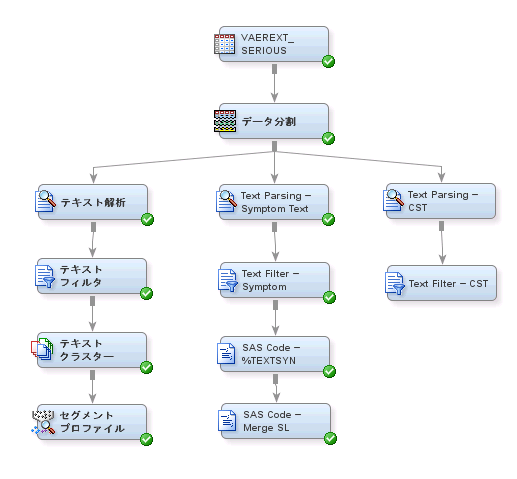
Text Parsing — Symptom Textノードを右クリックし、
コピーを選択します。
注: 新しいText Minerノードを作成するのではなく、Text Parsing — Symptom Textノードをコピーする必要があります。これは、以前にText Parsing — Symptom Textノードで設定したのと同じプロパティ設定を保持するためです。
-
ダイアグラムワークスペース内の空のスペースを右クリックし、
ペーストを選択します。
-
テキスト解析ノードを右クリックし、
名前の変更を選択します。
-
ノード名フィールドに
Text
Parsing — CSTと入力します。
CSTはCleaned Symptom Textを意味します。
-
-
Text Filter — Symptom Textノードを右クリックし、
コピーを選択します。
-
ダイアグラムワークスペース内の空のスペースを右クリックし、
ペーストを選択します。
-
テキストフィルタノードを右クリックし、
名前の変更を選択します。
-
ノード名フィールドに
Text
Filter — CSTと入力します。
-
-
データ分割ノードを
Text Parsing — CSTノードに接続します。
-
Text Parsing — CSTノードを
Text Filter — CSTノードに接続します。
-
Text Parsing — CSTノードを選択します。
-
類義語プロパティの
をクリックします。
-
-
SASライブラリツリー内の
Mylibをクリックします。
Mylibライブラリの内容が表示されます。
-
Mylib.Vaerextsyns_newを選択します。
-
-
データセットの内容がダイアログボックスに表示されます。
-
-
Text Filter — CSTノードを右クリックし、
実行を選択します。
確認ダイアログボックスで
はいを選択します。
-
同ノードの実行完了後に表示される
実行ステータスダイアログボックス内で
OKをクリックします。
-
Text Filter — CSTノードを選択します。
-
フィルタビューアプロパティの
をクリックします。
対話型のフィルタビューアウィンドウが表示されます。
-
下スクロールし、
語テーブル内の
patientの隣にあるプラス記号(+)を選択します。
patien、
patietn、
paitentが、スペルの間違っている語として表示されていることに注意してください。
-