| What's New |
What's New in SAS/ETS for SAS 9.2
|
|
| Overview |
Many SAS/ETS procedures now produce graphical output using the SAS Output Delivery System. This output is produced when you turn on ODS graphics with the following ODS statement:
ods graphics on;
Several procedures now support the PLOTS= option to control the graphical output produced. (See the chapters for individual SAS/ETS procedures for details on the plots supported.)
With SAS 9.2, SAS/ETS offers three new modules:
-
The new ESM procedure provides forecasting using exponential smoothing models with optimized smoothing weights.
-
The SASEHAVR interface engine is now production and available to Windows users for accessing economic and financial data residing in a HAVER ANALYTICS Data Link Express (DLX) database.
-
The new SIMILARITY (experimental) procedure provides similarity analysis of time series data.
New features have been added to the following SAS/ETS components:
-
PROC AUTOREG
-
PROC COUNTREG
-
PROC DATASOURCE
-
PROC MODEL
-
PROC PANEL
-
PROC QLIM
-
SASECRSP Interface Engine
-
SASEFAME Interface Engine
-
SASEHAVR Interface Engine
-
PROC UCM
-
PROC VARMAX
-
PROC X12
|
|
| AUTOREG Procedure |
Two new features have been added to the AUTOREG procedure.
-
An alternative test for stationarity, proposed by Kwiatkowski, Phillips, Schmidt, and Shin (KPSS), is implemented. The null hypothesis for this test is a stationary time series, which is a natural choice for many applications. Bartlett and quadratic spectral kernels for estimating long-run variance can be used. Automatic bandwidth selection is an option.
-
Corrected Akaike information criterion (AICC) is implemented. This modification of AIC corrects for small-sample bias. Along with the corrected Akaike information criterion, the mean absolute error (MAE) and mean absolute percentage error (MAPE) are now included in the summary statistics.
|
|
| COUNTREG Procedure |
Often the data that is being analyzed take the form of nonnegative integer (count) values. The new COUNTREG procedure implements count data models that take this discrete nature of data into consideration. The dependent variable in these models is a count that represents various discrete events (such as number of accidents, number of doctor visits, or number of children). The conditional mean of the dependent variable is a function of various covariates. Typically, you are interested in estimating the probability of the number of event occurrences using maximum likelihood estimation. The COUNTREG procedure supports the following types of models:
-
Poisson regression
-
negative binomial regression with linear (NEGBIN1) and quadratic (NEGBIN2) variance functions (Cameron and Trivedi 1986)
-
zero-inflated Poisson (ZIP) model (Lambert 1992)
-
zero-inflated negative binomial (ZINB) model
|
|
| DATASOURCE Procedure |
PROC DATASOURCE now supports the newest Compustat Industrial Universal Character Annual and Quarterly data by providing the new filetypes CSAUCY3 for annual data and CSQUCY3 for quarterly data.
|
|
| New ESM Procedure |
The ESM (Exponential Smoothing Models) procedure provides a quick way to generate forecasts for many time series or transactional data in one step. All parameters associated with the forecast model are optimized based on the data.
|
|
| MODEL Procedure |
The  copula and the normal mixture copula have been added to the MODEL procedure. Both copulas support asymmetric parameters. The copula is used to modify the correlation structure of the model residuals for simulation.
copula and the normal mixture copula have been added to the MODEL procedure. Both copulas support asymmetric parameters. The copula is used to modify the correlation structure of the model residuals for simulation.
Starting with SAS 9.2, the MODEL procedure stores MODEL files in SAS datasets using an XML-like format instead of in SAS catalogs. This makes MODEL files more readily extendable in the future and enables Java-based applications to read the MODEL files directly. More information is stored in the new format MODEL files; this enables some features that are not available when the catalog format is used.
The MODEL procedure continues to read and write old-style catalog MODEL files, and model files created by previous releases of SAS/ETS continue to work, so you should experience no direct impact from this change.
The CMPMODEL= option can be used in an OPTIONS statement to modify the behavior of the MODEL when reading and writing MODEL files. The values allowed are CMPMODEL= BOTH | XML | CATALOG. For example, the following statements restore the previous behavior:
options cmpmodel=catalog;
The CMPMODEL= option defaults to BOTH in SAS 9.2; this option is intended for transitional use while customers become accustomed to the new file format. If CMPMODEL=BOTH, the MODEL procedure writes both formats; when loading model files, PROC MODEL attempts to load the XML version first and the CATALOG version second (if the XML version is not found). If CMPMODEL=XML the MODEL procedure reads and writes only the XML format. If CMPMODEL=CATALOG, only the catalog format is used.
|
|
| PANEL Procedure |
The PANEL procedure expands the estimation capability of the TSCSREG procedure in the time-series cross-sectional framework. The new methods include: between estimators, pooled estimators, and dynamic panel estimators using GMM method. Creating lags of variables in a panel setting is simplified by the LAG statement. Because the presence of heteroscedasticity can result in inefficient and biased estimates of the variance covariance matrix in the OLS framework, several methods that produce heteroscedasticity-corrected covariance matrices (HCCME) are added. The new RESTRICT statement specifies linear restrictions on the parameters. New ODS Graphics plots simplify model development by providing visual analytical tools.
|
|
| QLIM Procedure |
Stochastic frontier models are now available in the QLIM procedure. Specification of these models allows for random shocks of production or cost along with technological or cost inefficiencies. The nonnegative error-term component that represents technological or cost inefficiencies has half-normal, exponential, or truncated normal distributions.
|
|
| SASECRSP Engine |
The SASECRSP interface now supports reading of CRSP stock, indices, and combined stock/indices databases by using a variety of keys, not just CRSP’s primary key PERMNO.
In addition, SASECRSP can now read the CRSP/Compustat Merged (CCM) database and fully supports cross-database access, enabling you to access the CCM database by CRSP’s main identifiers PERMNO and PERMCO, as well as to access the CRSP Stock databases by Compustat’s GVKEY identifier.
A list of other new features follows:
-
SASECRSP now fully supports access of fiscal CCM data members by both fiscal and calendar date range restrictions. Fiscal to calendar date shifting has been added as well.
-
New date fields have been added for CCM fiscal members. Now fiscal members have three different dates: a CRSP date, a fiscal integer date, and a calendar integer date.
-
An additional date function has been added which enables you to convert from fiscal to calendar dates.
-
Date range restriction for segment members has also been added.
|
|
| SASEFAME Engine |
The SASEFAME interface enables you to access and process financial and economic time series data that resides in a FAME database. SASEFAME for SAS 9.2 supports Windows, Solaris, AIX, Linux, Linux Opteron, and HP-UX hosts. You can now use the SAS windowing environment to view FAME data and use the SAS viewtable commands to navigate your FAME data base. You can select the time span of data by specifying a range of dates in the RANGE= option. You can use an input SAS data set with a WHERE clause to specify selection of variables based on BY variables, such as tickers or issues stored in a FAME string case series. You can use a FAME crosslist to perform selection based on the crossproduct of two FAME namelists. The new FAMEOUT= option now supports the following classes and types of data series objects: FORMULA, TIME, BOOLEAN, CASE, DATE, and STRING.
It is easy to use a SAS input data set with the INSET= option to create a specific view of your FAME data. Multiple views can be created by using multiple LIBNAME statements with customized options tailored to the unique view that you want to create. See Selecting Time Series Using CROSSLIST= Option with INSET= and WHERE=TICK in Chapter 34, The SASEFAME Interface Engine.
The INSET variables define the BY variables that enable you to view cross sections or slices of your data. When used in conjunction with the WHERE clause and the CROSSLIST= option, SASEFAME can show any or all of your BY groups in the same view or in multiple views. The INSET= option is invalid without a WHERE that clause specifies the BY variables you want to use in your view, and it must be used with the CROSSLIST=option.
The CROSSLIST= option provides a more efficient means of selecting cross sections of financial time series data. This option can be used without using the INSET= option. There are two methods for performing the crosslist selection function. The first method uses two FAME namelists, and the second method uses one namelist and one BY group specified in the WHERE= clause of the INSET=option. See Selecting Time Series Using CROSSLIST= Option with a FAME Namelist of Tickers in Chapter 34, The SASEFAME Interface Engine.
The FAMEOUT= option provides efficient selection of the class and type of the FAME data series objects you want in your SAS output data set. The possible values for fame_data_object_class_type are FORMULA, TIME, BOOLEAN, CASE, DATE, and STRING. If the FAMEOUT=option is not specified, numeric time series are output to the SAS data set. FAMEOUT=CASE defaults to case series of numeric type, so if you want another type of case series in your output, then you must specify it. Scalar data objects are not supported. See Reading Other FAME Data Objects with the FAMEOUT= Option in Chapter 34, The SASEFAME Interface Engine.
|
|
| SASEHAVR Engine |
The SASEHAVR interface engine is now production, giving Windows users random access to economic and financial data that resides in a Haver Analytics Data Link Express (DLX) database. You can now use the SAS windowing environment to view HAVERDLX data and use the SAS viewtable commands to navigate your Haver database. You can use the SQL procedure to create a view of your resulting SAS data set. You can limit the range of data that is read from the time series and specify a desired conversion frequency. Start dates are recommended in the LIBNAME statement to help you save resources when processing large databases or when processing a large number of observations. You can further subset your data by using the WHERE, KEEP, or DROP statements in your DATA step. New options are provided for more efficient subsetting by time series variables, groups, or sources. You can force the aggregation of all variables selected to be of the frequency specified by the FREQ= option if you also specify the FORCE=FREQ option. Aggregation is supported only from a more frequent time interval to a less frequent time interval, such as from weekly to monthly.
A list of other new features follows:
-
You can see the available data sets in the SAS LIBNAME window of the SAS windowing environment by selecting the SASEHAVR libref in the LIBNAME window that you have previously used in your LIBNAME statement. You can view your SAS output observations by double clicking on the desired output data set libref in the libname window of the SAS windowing environment. You can type Viewtable on the SAS command line to view any of your SASEHAVR tables, views, or librefs, both for input and output data sets.
-
By default, the SASEHAVR engine reads all time series in the Haver database that you reference by using your SASEHAVR libref. The START= option is specified in the form YYYYMMDD, as is the END= option. The start and end dates are used to limit the time span of data; they can help you save resources when processing large databases or when processing a large number of observations.
-
It is also possible to select specific variables to be included or excluded from the SAS data set by using the KEEP= or the DROP= option. When the KEEP= or the DROP= option is used, the resulting SAS data set keeps or drops the variables that you select in that option. There are three wildcards currently available: '*', '?', and '
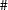 '. The '*' wildcard corresponds to any character string and will include any string pattern that corresponds to that position in the matching variable name. The '?' means that any single alphanumeric character is valid. The '' wildcard corresponds to a single numeric character.
'. The '*' wildcard corresponds to any character string and will include any string pattern that corresponds to that position in the matching variable name. The '?' means that any single alphanumeric character is valid. The '' wildcard corresponds to a single numeric character. -
You can also select time series in your data by using the GROUP= or the SOURCE= option to select on group name or on source name. Alternatively, you can deselect time series by using the DROPGROUP= or the DROPSOURCE= option. These options also support the wildcards '*', '?', and '
'. -
By default, SASEHAVR selects only the variables that are of the specified frequency in the FREQ= option. If this option is not specified, SASEHAVR selects the variables that match the frequency of the first selected variable. If no other selection criteria are specified, the first selected variable is the first physical DLXRecord read from the Haver database. The FORCE=FREQ option can be specified to force the aggregation of all variables selected to be of the frequency specified by the FREQ= option. Aggregation is supported only from a more frequent time interval to a less frequent time interval, such as from weekly to monthly. The FORCE= option is ignored if the FREQ= option is not specified.
|
|
| New SIMILARITY Procedure (Experimental) |
The new SIMILARITY procedure provides similarity analysis between two time series and other sequentially ordered numeric data. The SIMILARITY procedure computes similarity measures between an input sequence and target sequence, as well as similarity measures that "slide" the target sequence with respect to the input sequence. The "slides" can be by observation index (sliding-sequence similarity measures) or by seasonal index (seasonal-sliding-sequence similarity measures).
|
|
| UCM Procedure |
The following features are new to the UCM procedure:
-
The new RANDOMREG statement enables specification of regressors with time-varying regression coefficients. The coefficients are assumed to follow independent random walks. Multiple RANDOMREG statements can be specified, and each statement can specify multiple regressors. The regression coefficient random walks for regressors specified in the same RANDOMREG statement are assumed to have the same disturbance variance parameter. This arrangement enables a very flexible specification of regressors with time-varying coefficients.
-
The new SPLINEREG statement enables specification of a spline regressor that can optionally have time-varying coefficients. The spline specification is useful when the series being forecast depends on a regressor in a nonlinear fashion.
-
The new SPLINESEASON statement enables parsimonious modeling of long and complex seasonal patterns using the spline approximation.
-
The SEASON statement now has options that enable complete control over the constituent harmonics that make up the trigonometric seasonal model.
-
It is now easy to obtain diagnostic test statistics useful for detecting structural breaks such as additive outliers and level shifts.
-
As an experimental feature, you can now model the irregular component as an autoregressive moving-average (ARMA) process.
-
The memory management and numerical efficiency of the underlying algorithms have been improved.
|
|
| VARMAX Procedure |
The VARMAX procedure now enables independent (exogenous) variables with their distributed lags to influence dependent (endogenous) variables in various models, such as VARMAX, BVARX, VECMX, BVECMX, and GARCH-type multivariate conditional heteroscedasticity models.
Multivariate GARCH Models—New GARCH Statement
Multivariate GARCH modeling is now a production feature of VARMAX.
To enable greater flexibility in specifying multivariate GARCH models, the new GARCH statement has been added to the VARMAX procedure. With the addition of the GARCH statement, the GARCH= option is no longer supported on the MODEL statement.
The OUTHT= option can be specified in the GARCH statement to write the estimated conditional covariance matrix to an output data set. See GARCH Statement in Chapter 30, The VARMAX Procedure, for details.
The VARMAX Model
The VARMAX procedure provides modeling of a VARMAX(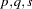 ) process which is written as
) process which is written as
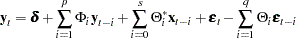 |
where 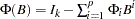 ,
, 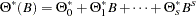 , and
, and 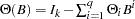 .
.
If the Kalman filtering method is used for the parameter estimation of the VARMAX( ,
, ,
, ) model, then the dimension of the state-space vector is large, which takes time and memory for computing. For convenience, the parameter estimation of the VARMAX(,,) model uses the two-stage estimation method, which computes the estimation of deterministic terms and exogenous parameters and then maximizes the log-likelihood function of the VARMA(,) model.
) model, then the dimension of the state-space vector is large, which takes time and memory for computing. For convenience, the parameter estimation of the VARMAX(,,) model uses the two-stage estimation method, which computes the estimation of deterministic terms and exogenous parameters and then maximizes the log-likelihood function of the VARMA(,) model.
Some examples of VARMAX modeling are:
model y1 y2 = x1 / q=1; nloptions tech=qn;
model y1 y2 = x1 / p=1 q=1 xlag=1 nocurrentx; nloptions tech=qn;
The BVARX Model
Bayesian modeling allows independent (exogenous) variables with their distributed lags. For example:
model y1 y2 = x1 / p=2 prior=(theta=0.2 lambda=5);
The VECMX Model
Vector error correction modeling now allows independent (exogenous) variables with their distributed lags. For example:
model y1 y2 = x1 / p=2 ecm=(rank=1);
The BVECMX Model
Bayesian vector error correction modeling allows independent (exogenous) variables with their distributed lags. For example:
model y1 y2 = x1 / p=2 prior=(theta=0.2 lambda=5) ecm=(rank=1);
The VARMAX-GARCH Model
VARMAX modeling now supports an error term that has a GARCH-type multivariate conditional heteroscedasticity model. For example:
model y1 y2 = x1 / p=1 q=1; garch q=1;
New Printing Control Options
The PRINT= option can be used in the MODEL statement to control the results printed. See the description of the PRINT= option in Chapter 30, The VARMAX Procedure, for details.
|
|
| X12 Procedure |
The X12 procedure has many new statements and options. Many of the new features are related to the regARIMA modeling, which is used to extend the series to be seasonally adjusted. A new experimental input and output data set has been added which describes the times series model fit to the series.
The following miscellaneous statements and options are new:
-
The NOINT option on the AUTOMDL statement suppresses the fitting of a constant term in automatically identified models.
-
The following tables are now available through the OUTPUT statement: A7, A9, A10, C20, D1, and D7.
-
The TABLES statement enables you to display some tables that represent intermediate calculations in the X11 method and that are not displayed by default.
The following statements and options related to the regression component of regARIMA modeling are new:
-
The SPAN= option on the OUTLIER statement can be used to limit automatic outlier detection to a subset of the time series observations.
-
The following predefined variables have been added to the PREDEFINED option on the REGRESSION statement: EASTER(value), SCEASTER(value), LABOR(value), THANK(value), TDSTOCK(value), SINCOS(value ...).
-
User-defined regression variables can be included on the regression model by specifying them in the USERVAR=(variables) option in the REGRESSION statement or the INPUT statement.
-
Events can be included as user-defined regression variables in the regression model by specifying them in the EVENT statement. SAS predefined events do not require an INEVENT= data set, but an INEVENT= data set can be specified to define other events.
-
You can now supply initial or fixed parameter values for regression variables by using the B=(value <F> ...) option in the EVENT statement, the B=(value <F> ...) option in the INPUT statement, the B=(value <F> ...) option in the REGRESSION statement, or by using the MDLINFOIN= data set in the PROC X12 statement. Some regression variable parameters can be fixed while others are estimated.
-
You can now assign user-defined regression variables to a group by the USERTYPE= option in the EVENT statement, the USERTYPE= option in the INPUT statement, the USERTYPE= option in the REGRESSION statement, or by using the MDLINFOIN= data set in the PROC X12 statement. Census Bureau predefined variables are automatically assigned to a regression group, and this cannot be modified. But assigning user-defined regression variables to a regression group allows them to be processed similarly to the predefined variables.
-
You can now supply initial or fixed parameters for ARMA coefficients using the MDLINFOIN= data set in the PROC X12 statement. Some ARMA coefficients can be fixed while others are estimated.
-
The INEVENT= option on the PROC X12 statement enables you to supply an EVENT definition data set so that the events defined in the EVENT definition data set can be used as user-defined regressors in the regARIMA model.
-
User-defined regression variables in the input data set can be identified by specifying them in the USERDEFINED statement. User-defined regression variables specified in the USERVAR=(variables) option of the REGRESSION statement or the INPUT statement do not need to be specified in the USERDEFINED statement, but user-defined variables specified only in the MDLINFOIN= data set need to be identfied in the USERDEFINED statement.
The following new experimental options specify input and output data sets that describe the times series model:
-
The MDLINFOIN= and MDLINFOOUT= data sets specified in the PROC X12 statement enable you to store the results of model identification and use the stored information as input when executing the X12 Procedure.
| References |
-
Center for Research in Security Prices (2003), CRSP/Compustat Merged Database Guide, Chicago: The University of Chicago Graduate School of Business, http://www.crsp.uchicago.edu/support/documentation/pdfs/ccm_database_guide.pdf.
-
Center for Research in Security Prices (2003), CRSP Data Description Guide, Chicago: The University of Chicago Graduate School of Business, http://www.crsp.uchicago.edu/support/documentation/pdfs/stock_indices_data_descriptions.pdf.
-
Center for Research in Security Prices (2002), CRSP Programmer’s Guide, Chicago: The University of Chicago Graduate School of Business, http://www.crsp.uchicago.edu/support/documentation/pdfs/stock_indices_programming.pdf.
-
Center for Research in Security Prices (2003), CRSPAccess Database Format Release Notes, Chicago: The University of Chicago Graduate School of Business, http://www.crsp.uchicago.edu/support/documentation/release_notes.html.
-
Center for Research in Security Prices (2003), CRSP Utilities Guide, Chicago: The University of Chicago Graduate School of Business, http://www.crsp.uchicago.edu/support/documentation/pdfs/stock_indices_utilities.pdf.
-
Center for Research in Security Prices (2002), CRSP SFA Guide, Chicago: The University of Chicago Graduate School of Business.
-
Gomez, V. and Maravall, A. (1997a), "Program TRAMO and SEATS: Instructions for the User, Beta Version," Banco de Espana.
-
Gomez, V. and Maravall, A. (1997b), "Guide for Using the Programs TRAMO and SEATS, Beta Version," Banco de Espana.
-
Haver Analytics (2001), DLX API Programmer’s Reference, New York, NY.
-
Stoffer, D. and Toloi, C. (1992), "A Note on the Ljung-Box-Pierce Portmanteau Statistic with Missing Data," Statistics & Probability Letters 13, 391-396.
-
SunGard Data Management Solutions (1998), Guide to FAME Database Servers, 888 Seventh Avenue, 12th Floor, New York, NY 10106 USA, http://www.fame.sungard.com/support.html, http://www.data.sungard.com.
-
SunGard Data Management Solutions (1995), User’s Guide to FAME, Ann Arbor, MI, http://www.fame.sungard.com/support.html.
-
SunGard Data Management Solutions (1995), Reference Guide to Seamless C HLI, Ann Arbor, MI, http://www.fame.sungard.com/support.html.
-
SunGard Data Management Solutions(1995), Command Reference for Release 7.6, Vols. 1 and 2, Ann Arbor, MI, http://www.fame.sungard.com/support.html.
Copyright © 2008 by SAS Institute Inc.,Cary, NC, USA. All rights reserved.