Split Columns Task
About the Split Columns Task
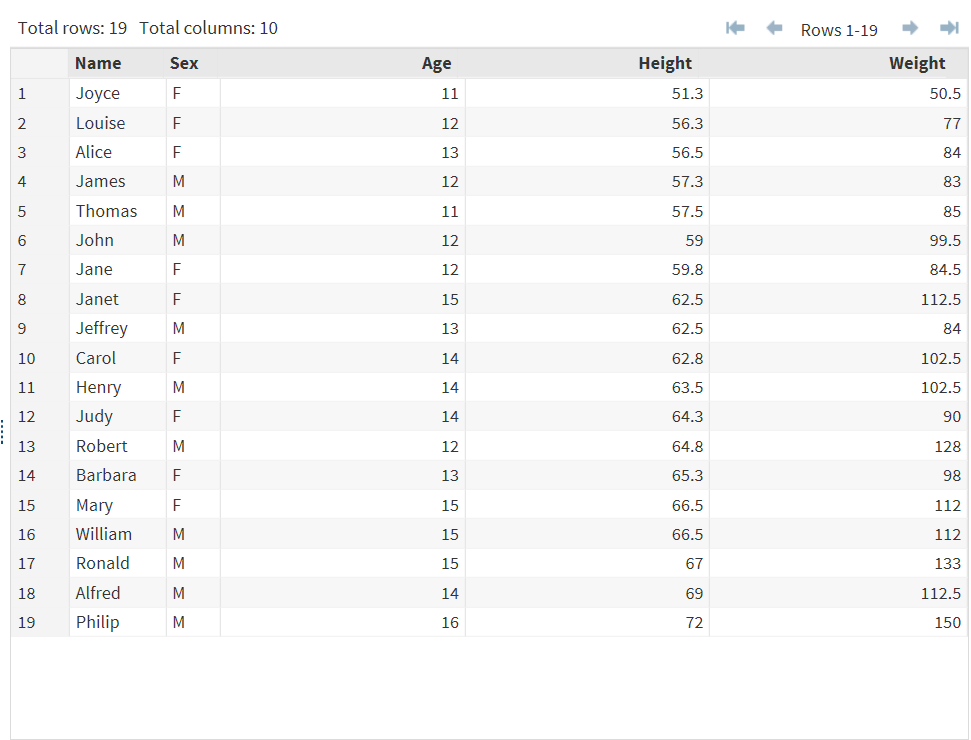
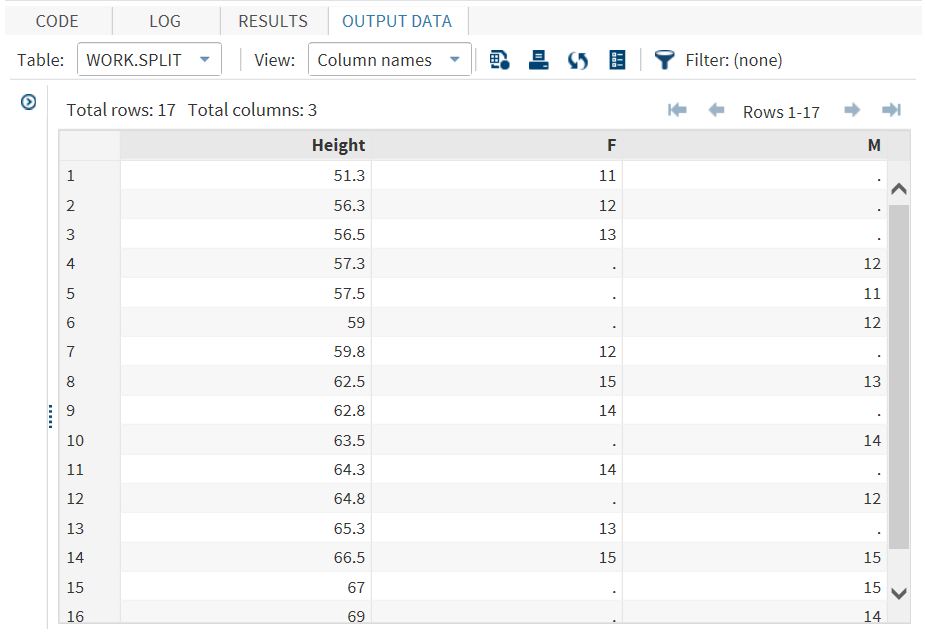
The Split Columns task creates an output data set by splitting the unique combination of values of the selected columns in the input data set into multiple columns.
This task is useful when you have a data set in which one column contains multiple observations for different subgroups and you want to split the subgroup measures into separate
columns. For example, you could split a column that contains the monthly temperature
readings for various locations across a geographic region. The output data set would
contain the monthly temperature readings for each location in a column for
each month.
Split a Column
To split a column:
-
-
RoleDescriptionRolesColumn to splitspecifies the variable that contains the values that you want to split into multiple columns.Case identifieridentifies the values that belong to a particular case.Level identifieridentifies the levels of the column to split. Each new variable contains the values of one level of the level identifier.Additional RolesGroup analysis byspecifies the variable to use to form BY groups.
-
Option NameDescriptionConstruct New Variable NamesUse prefixYou can specify a prefix to use in constructing the names for the transposed variables in the output data set. When you use a prefix, the variable name begins with the prefix value and is followed by the number 1, 2, and so on. To create a variable name with the prefix and the value of the selected variable, select Select a variable that contains the names for the new variables.Select a variable that contains the names of the new variablesThe variable that you assign to the New column names role is used to name the new columns in the output data set.Show Output DataShow output dataspecifies whether to include the output data in the results that appear on the Results tab. You can include all or a subset of the output data. The task always creates the output data set that appears on the Output Data tab. This data set is also saved to the specified location.
Copyright © SAS Institute Inc. All rights reserved.