The LIFETEST Procedure

Rank Tests for the Association of Survival Time with Covariates
The rank tests for the association of covariates (Kalbfleisch and Prentice 1980, Chapter 6) are more general cases of the rank tests for homogeneity. In this section, the index  is used to label all observations,
is used to label all observations, 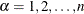 , and the indices
, and the indices 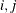 range only over the observations that correspond to events,
range only over the observations that correspond to events, 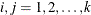 . The ordered event times are denoted as
. The ordered event times are denoted as 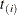 , the corresponding vectors of covariates are denoted as
, the corresponding vectors of covariates are denoted as 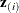 , and the ordered times, both censored and event times, are denoted as
, and the ordered times, both censored and event times, are denoted as 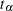 .
.
The rank test statistics have the form
![\[ \mb{v} = \sum _{\alpha =1}^ n c_{\alpha ,\delta _{\alpha }} \mb{z}_{\alpha } \]](images/statug_lifetest0293.png)
where n is the total number of observations,
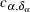 are rank scores, which can be either log-rank or Wilcoxon rank scores,
are rank scores, which can be either log-rank or Wilcoxon rank scores, 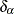 is 1 if the observation is an event and 0 if the observation is censored, and
is 1 if the observation is an event and 0 if the observation is censored, and 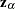 is the vector of covariates in the TEST statement for the th observation. Notice that the scores, , depend on the censoring pattern and that the terms are summed up over all observations.
is the vector of covariates in the TEST statement for the th observation. Notice that the scores, , depend on the censoring pattern and that the terms are summed up over all observations.
The log-rank scores are
![\[ c_{\alpha ,\delta _{\alpha }} = \sum _{(j:t_{(j)} \leq t_{\alpha })} \left( \frac{1}{n_ j} - \delta _{\alpha } \right) \]](images/statug_lifetest0297.png)
and the Wilcoxon scores are
![\[ c_{\alpha ,\delta _{\alpha }} = 1 - (1 + \delta _{\alpha }) \prod _{(j:t_{(j)} \leq t_{\alpha })} \frac{n_ j}{n_ j + 1} \]](images/statug_lifetest0298.png)
where 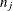 is the number at risk just prior to
is the number at risk just prior to 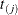 .
.
The estimates used for the covariance matrix of the log-rank statistics are
![\[ \mb{V} = \sum _{i=1}^ k \frac{\mb{V}_ i}{n_ i} \]](images/statug_lifetest0301.png)
where 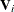 is the corrected sum of squares and crossproducts matrix for the risk set at time ; that is,
is the corrected sum of squares and crossproducts matrix for the risk set at time ; that is,
![\[ \mb{V}_ i = \sum _{(\alpha :t_{\alpha } \geq t_{(i)} ) } (\mb{z}_{\alpha } - \mb{\bar{z}}_ i)^{\prime } (\mb{z}_{\alpha } - \mb{\bar{z}}_ i) \]](images/statug_lifetest0303.png)
where
![\[ \mb{\bar{z}}_ i = \sum _{(\alpha :t_{\alpha } \geq t_{(i)} ) } \frac{\mb{z}_{\alpha }}{n_ i} \]](images/statug_lifetest0304.png)
The estimate used for the covariance matrix of the Wilcoxon statistics is
![\[ \mb{V} = \sum _{i=1}^ k \left[ a_ i (1 - a_ i^*) (2\mb{z}_{(i)}\mb{z}_{(i)}^{\prime } + \mb{S}_ i) - (a_ i^* - a_ i) \left( a_ i \mb{x}_ i\mb{x}_ i^{\prime } + \sum _{j=i+1}^ k a_ j (\mb{x}_ i\mb{x}_ j^{\prime } + \mb{x}_ j\mb{x}_ i^{\prime }) \right) \right] \]](images/statug_lifetest0305.png)
where
![\begin{eqnarray*} a_ i & = & \prod _{j=1}^ i \frac{n_ j}{n_ j + 1} \\[0.05in] a_ i^* & = & \prod _{j=1}^ i \frac{n_ j + 1}{n_ j + 2} \\[0.05in] \Strong{S}_ i & = & \sum _{(\alpha :t_{(i+1)} > t_{\alpha } > t_{(i)})} \Strong{z}_{\alpha } \Strong{z}_{\alpha }^{\prime } \\[0.05in] \Strong{x}_ i & = & 2 \Strong{z}_{(i)} + \sum _{(\alpha :t_{(i+1)} > t_{\alpha } > t_{(i)})} \Strong{z}_{\alpha } \\ \end{eqnarray*}](images/statug_lifetest0306.png)
In the case of tied failure times, the statistics  are averaged over the possible orderings of the tied failure times. The covariance matrices are also averaged over the tied
failure times. Averaging the covariance matrices over the tied orderings produces functions with appropriate symmetries for
the tied observations; however, the actual variances of the statistics would be smaller than the preceding estimates. Unless the proportion of ties is large, it is unlikely that this
will be a problem.
are averaged over the possible orderings of the tied failure times. The covariance matrices are also averaged over the tied
failure times. Averaging the covariance matrices over the tied orderings produces functions with appropriate symmetries for
the tied observations; however, the actual variances of the statistics would be smaller than the preceding estimates. Unless the proportion of ties is large, it is unlikely that this
will be a problem.
The univariate tests for each covariate are formed from each component of and the corresponding diagonal element of 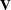 as
as 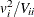 . These statistics are treated as coming from a chi-square distribution for calculation of probability values.
. These statistics are treated as coming from a chi-square distribution for calculation of probability values.
The statistic 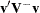 is computed by sweeping each pivot of the matrix in the order of greatest increase to the statistic. The corresponding sequence of partial statistics is tabulated.
Sequential increments for including a given covariate and the corresponding probabilities are also included in the same table.
These probabilities are calculated as the tail probabilities of a chi-square distribution with one degree of freedom. Because
of the selection process, these probabilities should not be interpreted as p-values.
is computed by sweeping each pivot of the matrix in the order of greatest increase to the statistic. The corresponding sequence of partial statistics is tabulated.
Sequential increments for including a given covariate and the corresponding probabilities are also included in the same table.
These probabilities are calculated as the tail probabilities of a chi-square distribution with one degree of freedom. Because
of the selection process, these probabilities should not be interpreted as p-values.
If desired for data screening purposes, the output data set requested by the OUTTEST= option can be treated as a sum of squares and crossproducts matrix and processed by the REG procedure by using the option METHOD=RSQUARE. Then the sets of variables of a given size can be found that give the largest test statistics. Product-Limit Estimates and Tests of Association illustrates this process.