The HPQUANTSELECT Procedure

OUTPUT Statement
-
OUTPUT <OUT=SAS-data-set><COPYVARS=(variables)><keyword <=name>>…<keyword <=name>> ;
The OUTPUT statement creates a data set that contains observationwise statistics, which are computed after the final selected model is fit. To avoid data duplication for large data sets, the variables in the input data set are not included in the output data set; however, variables that are specified in the ID statement or COPYVARS= option are included.
If the input data are in distributed form, where access of data in a particular order cannot be guaranteed, the HPQUANTSELECT procedure copies the distribution or partition key to the output data set so that its contents can be joined with the input data.
The output statistics are computed based on the parameter estimates for the selected model. If you specify multiple quantile
levels by using the QUANTILE= option in the MODEL
statement, then for each appropriate keyword that is specified in the OUTPUT statement, one variable is generated for each
specified quantile level. These variables appear in the sorted order of the specified quantile levels. For example, the following
statements generate the Out data set, which contains the two predicted quantile variables p1 and p2:
proc hpquantselect data=one; model y = x1-x4 /quantile=0.5 0.3; output out=out pred=p; run;
The variable p1 is for quantile level 0.3, and the variable p2 is for quantile level 0.5, because the sorted quantile levels are (0.3 0.5), not (0.5 0.3).
You can specify the following options in the OUTPUT statement:
-
OUT=SAS-data-set
DATA=SAS-data-set -
specifies the name of the output data set. If you omit the OUT= (or DATA=) option, PROC HPQUANTSELECT uses the
DATAn convention to name the output data set. -
COPYVAR=variable
COPYVARS=(variables) -
transfers one or more variables from the input data set to the output data set. Variables that you name in an ID statement are also copied from the input data set to the output data set.
- keyword <=name>
-
specifies the statistics to include in the output data set and optionally names the new variables that contain the statistics. Specify a keyword for each desired statistic (see the following list of keywords), followed optionally by an equal sign and a variable to contain the statistic.
If you specify keyword=name, the new variable that contains the requested statistic has the specified name. If you omit the optional =name after a keyword, then a default name is used.
You can specify the following keywords to request statistics that are available with for selection methods:
- LCLM
-
requests the lower bound of a
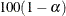 % confidence interval for the expected quantile of the dependent variable. The default variable name is
% confidence interval for the expected quantile of the dependent variable. The default variable name is LCLM. -
PREDICTED
PRED
P -
requests predicted values for the response variable. The default variable name is
Pred. -
RESIDUAL
RESID
R -
requests the residual, calculated as ACTUAL – PREDICTED. The default variable name is
Residual. - ROLE
-
requests a numeric variable that indicates the role that each observation plays in fitting the model. The default variable name is
_ROLE_. For each observation, the interpretation of this variable is shown in Table 59.3.Table 59.3: Role Interpretation
Value
Observation Role
0
Not used
1
Training
2
Validation
3
Testing
If you do not partition the input data by using a PARTITION statement, then the role variable value is 1 for observations that are used in fitting the model, and 0 for observations that have at least one missing or invalid value for the response, regressor, or weight variables.
You can use the following statements to display the values of the
_ROLE_variable in the output data set:proc format; value role 0 = 'Not Used' 1 = 'Training' 2 = 'Validation' 3 = 'Testing'; run; proc freq; tables _role_; format _role_ role.; run; - STDP
-
requests standard error of the mean predicted quantiles. The default variable name is
STDP. - UCLM
-
requests the upper bound of a
% confidence interval for the expected quantile of the dependent variable. The default variable name is UCLM.